 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStay in your Lane: Role Specific Queries with Overlap Suppression Loss for Dense Video Captioning
Mar 12, 2026Dense Video Captioning (DVC) is a challenging multimodal task that involves temporally localizing multiple events within a video and describing them with natural language. While query-based frameworks enable the simultaneous, end-to-end processing of localization and captioning, their reliance on shared queries often leads to significant multi-task interference between the two tasks, as well as temporal redundancy in localization. In this paper, we propose utilizing role-specific queries that separate localization and captioning into independent components, allowing each to exclusively learn its role. We then employ contrastive alignment to enforce semantic consistency between the corresponding outputs, ensuring coherent behavior across the separated queries. Furthermore, we design a novel suppression mechanism in which mutual temporal overlaps across queries are penalized to tackle temporal redundancy, supervising the model to learn distinct, non-overlapping event regions for more precise localization. Additionally, we introduce a lightweight module that captures core event concepts to further enhance semantic richness in captions through concept-level representations. We demonstrate the effectiveness of our method through extensive experiments on major DVC benchmarks YouCook2 and ActivityNet Captions.
MultiLexNorm++: A Unified Benchmark and a Generative Model for Lexical Normalization for Asian Languages
Jan 23, 2026Social media data has been of interest to Natural Language Processing (NLP) practitioners for over a decade, because of its richness in information, but also challenges for automatic processing. Since language use is more informal, spontaneous, and adheres to many different sociolects, the performance of NLP models often deteriorates. One solution to this problem is to transform data to a standard variant before processing it, which is also called lexical normalization. There has been a wide variety of benchmarks and models proposed for this task. The MultiLexNorm benchmark proposed to unify these efforts, but it consists almost solely of languages from the Indo-European language family in the Latin script. Hence, we propose an extension to MultiLexNorm, which covers 5 Asian languages from different language families in 4 different scripts. We show that the previous state-of-the-art model performs worse on the new languages and propose a new architecture based on Large Language Models (LLMs), which shows more robust performance. Finally, we analyze remaining errors, revealing future directions for this task.
AI-Enhanced High-Density NIRS Patch for Real-Time Brain Layer Oxygenation Monitoring in Neurological Emergencies
Nov 06, 2025Photon scattering has traditionally limited the ability of near-infrared spectroscopy (NIRS) to extract accurate, layer-specific information from the brain. This limitation restricts its clinical utility for precise neurological monitoring. To address this, we introduce an AI-driven, high-density NIRS system optimized to provide real-time, layer-specific oxygenation data from the brain cortex, specifically targeting acute neuro-emergencies. Our system integrates high-density NIRS reflectance data with a neural network trained on MRI-based synthetic datasets. This approach achieves robust cortical oxygenation accuracy across diverse anatomical variations. In simulations, our AI-assisted NIRS demonstrated a strong correlation (R2=0.913) with actual cortical oxygenation, markedly outperforming conventional methods (R2=0.469). Furthermore, biomimetic phantom experiments confirmed its superior anatomical reliability (R2=0.986) compared to standard commercial devices (R2=0.823). In clinical validation with healthy subjects and ischemic stroke patients, the system distinguished between the two groups with an AUC of 0.943. This highlights its potential as an accessible, high-accuracy diagnostic tool for emergency and point-of-care settings. These results underscore the system's capability to advance neuro-monitoring precision through AI, enabling timely, data-driven decisions in critical care environments.
Contrastive Representation Regularization for Vision-Language-Action Models
Oct 02, 2025Vision-Language-Action (VLA) models have shown its capabilities in robot manipulation by leveraging rich representations from pre-trained Vision-Language Models (VLMs). However, their representations arguably remain suboptimal, lacking sensitivity to robotic signals such as control actions and proprioceptive states. To address the issue, we introduce Robot State-aware Contrastive Loss (RS-CL), a simple and effective representation regularization for VLA models, designed to bridge the gap between VLM representations and robotic signals. In particular, RS-CL aligns the representations more closely with the robot's proprioceptive states, by using relative distances between the states as soft supervision. Complementing the original action prediction objective, RS-CL effectively enhances control-relevant representation learning, while being lightweight and fully compatible with standard VLA training pipeline. Our empirical results demonstrate that RS-CL substantially improves the manipulation performance of state-of-the-art VLA models; it pushes the prior art from 30.8% to 41.5% on pick-and-place tasks in RoboCasa-Kitchen, through more accurate positioning during grasping and placing, and boosts success rates from 45.0% to 58.3% on challenging real-robot manipulation tasks.
SAFE-SQL: Self-Augmented In-Context Learning with Fine-grained Example Selection for Text-to-SQL
Feb 17, 2025Text-to-SQL aims to convert natural language questions into executable SQL queries. While previous approaches, such as skeleton-masked selection, have demonstrated strong performance by retrieving similar training examples to guide large language models (LLMs), they struggle in real-world scenarios where such examples are unavailable. To overcome this limitation, we propose Self-Augmentation in-context learning with Fine-grained Example selection for Text-to-SQL (SAFE-SQL), a novel framework that improves SQL generation by generating and filtering self-augmented examples. SAFE-SQL first prompts an LLM to generate multiple Text-to-SQL examples relevant to the test input. Then SAFE-SQL filters these examples through three relevance assessments, constructing high-quality in-context learning examples. Using self-generated examples, SAFE-SQL surpasses the previous zero-shot, and few-shot Text-to-SQL frameworks, achieving higher execution accuracy. Notably, our approach provides additional performance gains in extra hard and unseen scenarios, where conventional methods often fail.
Probing-RAG: Self-Probing to Guide Language Models in Selective Document Retrieval
Oct 17, 2024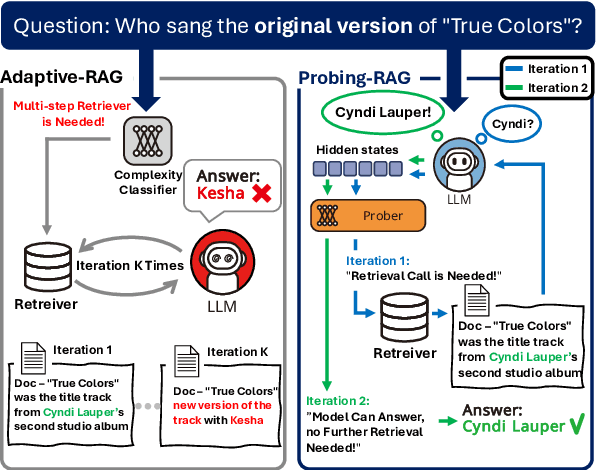
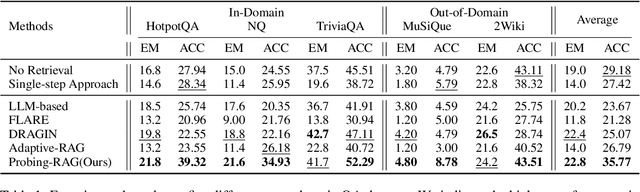
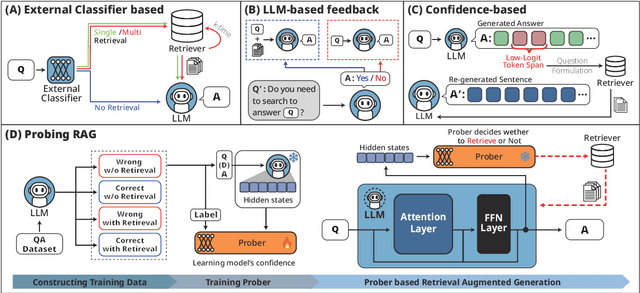
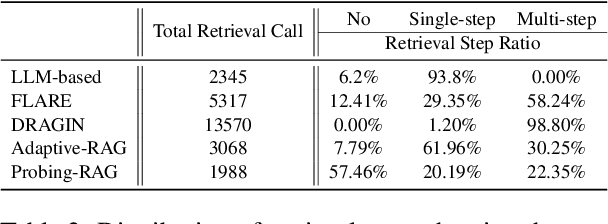
Retrieval-Augmented Generation (RAG) enhances language models by retrieving and incorporating relevant external knowledge. However, traditional retrieve-and-generate processes may not be optimized for real-world scenarios, where queries might require multiple retrieval steps or none at all. In this paper, we propose a Probing-RAG, which utilizes the hidden state representations from the intermediate layers of language models to adaptively determine the necessity of additional retrievals for a given query. By employing a pre-trained prober, Probing-RAG effectively captures the model's internal cognition, enabling reliable decision-making about retrieving external documents. Experimental results across five open-domain QA datasets demonstrate that Probing-RAG outperforms previous methods while reducing the number of redundant retrieval steps.
SoccerNet 2024 Challenges Results
Sep 16, 2024

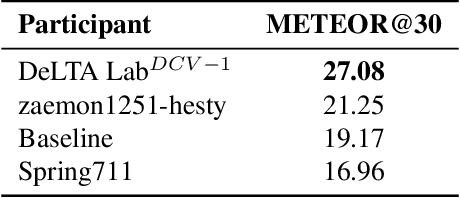
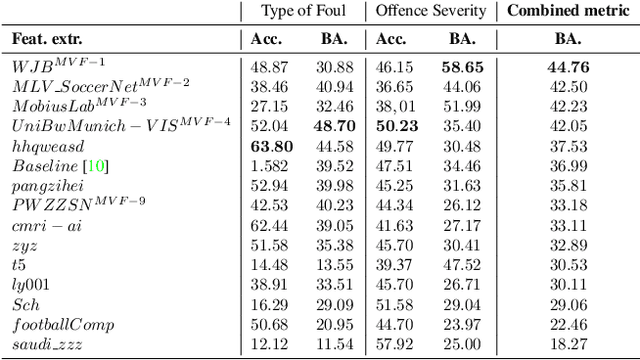
The SoccerNet 2024 challenges represent the fourth annual video understanding challenges organized by the SoccerNet team. These challenges aim to advance research across multiple themes in football, including broadcast video understanding, field understanding, and player understanding. This year, the challenges encompass four vision-based tasks. (1) Ball Action Spotting, focusing on precisely localizing when and which soccer actions related to the ball occur, (2) Dense Video Captioning, focusing on describing the broadcast with natural language and anchored timestamps, (3) Multi-View Foul Recognition, a novel task focusing on analyzing multiple viewpoints of a potential foul incident to classify whether a foul occurred and assess its severity, (4) Game State Reconstruction, another novel task focusing on reconstructing the game state from broadcast videos onto a 2D top-view map of the field. Detailed information about the tasks, challenges, and leaderboards can be found at https://www.soccer-net.org, with baselines and development kits available at https://github.com/SoccerNet.
Crafting the Path: Robust Query Rewriting for Information Retrieval
Jul 17, 2024Query rewriting aims to generate a new query that can complement the original query to improve the information retrieval system. Recent studies on query rewriting, such as query2doc (Q2D), query2expand (Q2E) and querey2cot (Q2C), rely on the internal knowledge of Large Language Models (LLMs) to generate a relevant passage to add information to the query. Nevertheless, the efficacy of these methodologies may markedly decline in instances where the requisite knowledge is not encapsulated within the model's intrinsic parameters. In this paper, we propose a novel structured query rewriting method called Crafting the Path tailored for retrieval systems. Crafting the Path involves a three-step process that crafts query-related information necessary for finding the passages to be searched in each step. Specifically, the Crafting the Path begins with Query Concept Comprehension, proceeds to Query Type Identification, and finally conducts Expected Answer Extraction. Experimental results show that our method outperforms previous rewriting methods, especially in less familiar domains for LLMs. We demonstrate that our method is less dependent on the internal parameter knowledge of the model and generates queries with fewer factual inaccuracies. Furthermore, we observe that Crafting the Path has less latency compared to the baselines.
Conversion of single-energy computed tomography to parametric maps of dual-energy computed tomography using convolutional neural network
Sep 26, 2023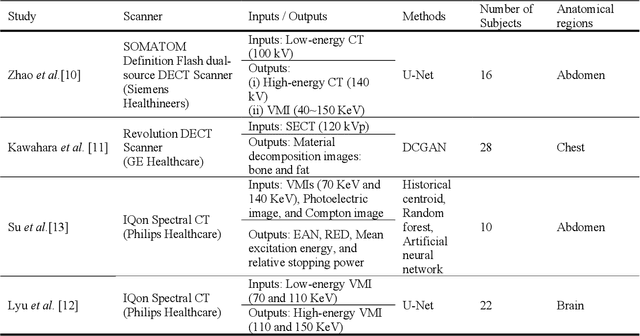
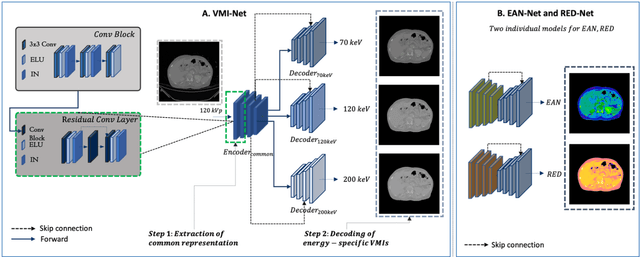

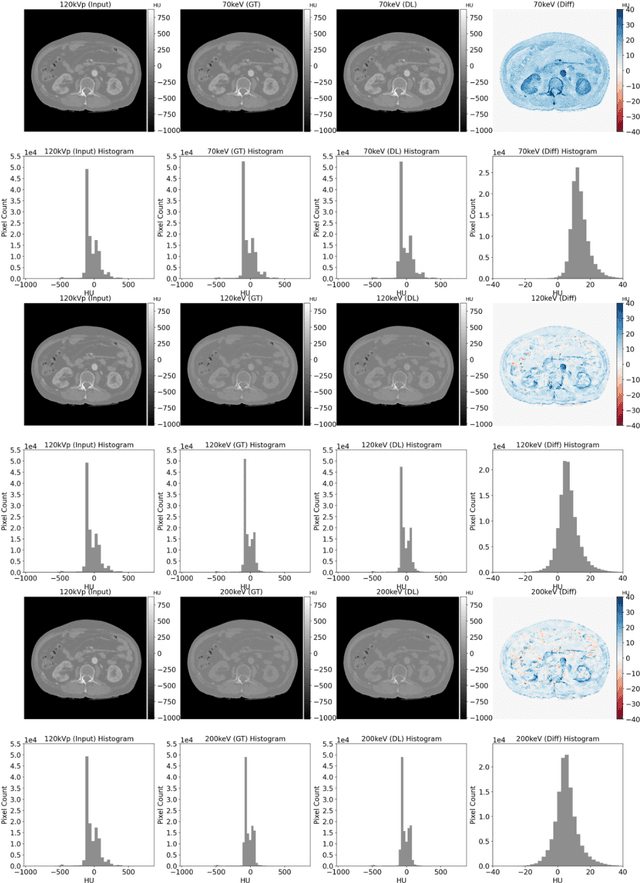
Objectives: We propose a deep learning (DL) multi-task learning framework using convolutional neural network (CNN) for a direct conversion of single-energy CT (SECT) to three different parametric maps of dual-energy CT (DECT): Virtual-monochromatic image (VMI), effective atomic number (EAN), and relative electron density (RED). Methods: We propose VMI-Net for conversion of SECT to 70, 120, and 200 keV VMIs. In addition, EAN-Net and RED-Net were also developed to convert SECT to EAN and RED. We trained and validated our model using 67 patients collected between 2019 and 2020. SECT images with 120 kVp acquired by the DECT (IQon spectral CT, Philips) were used as input, while the VMIs, EAN, and RED acquired by the same device were used as target. The performance of the DL framework was evaluated by absolute difference (AD) and relative difference (RD). Results: The VMI-Net converted 120 kVp SECT to the VMIs with AD of 9.02 Hounsfield Unit, and RD of 0.41% compared to the ground truth VMIs. The ADs of the converted EAN and RED were 0.29 and 0.96, respectively, while the RDs were 1.99% and 0.50% for the converted EAN and RED, respectively. Conclusions: SECT images were directly converted to the three parametric maps of DECT (i.e., VMIs, EAN, and RED). By using this model, one can generate the parametric information from SECT images without DECT device. Our model can help investigate the parametric information from SECT retrospectively. Advances in knowledge: Deep learning framework enables converting SECT to various high-quality parametric maps of DECT.
Intelligent upper-limb exoskeleton using deep learning to predict human intention for sensory-feedback augmentation
Sep 09, 2023
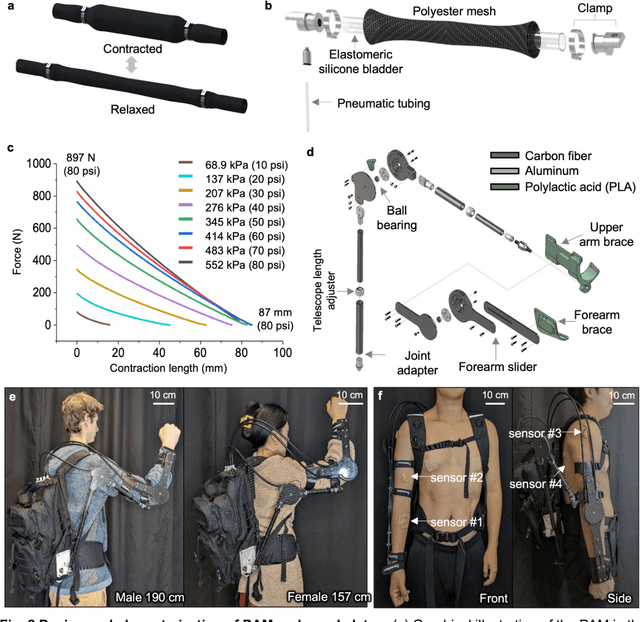
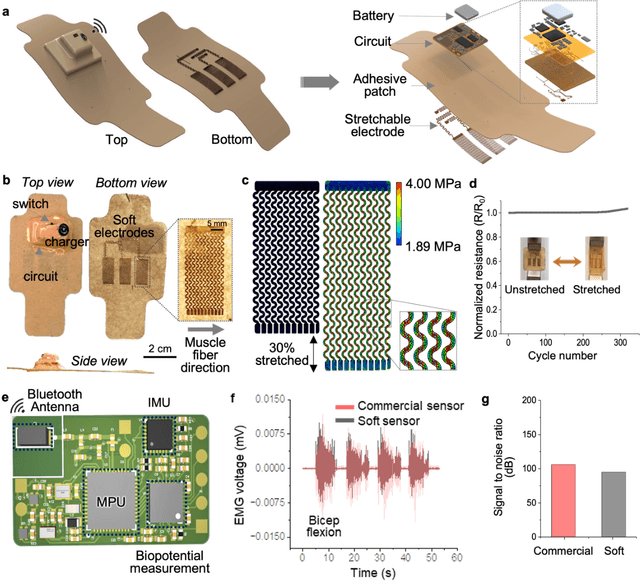
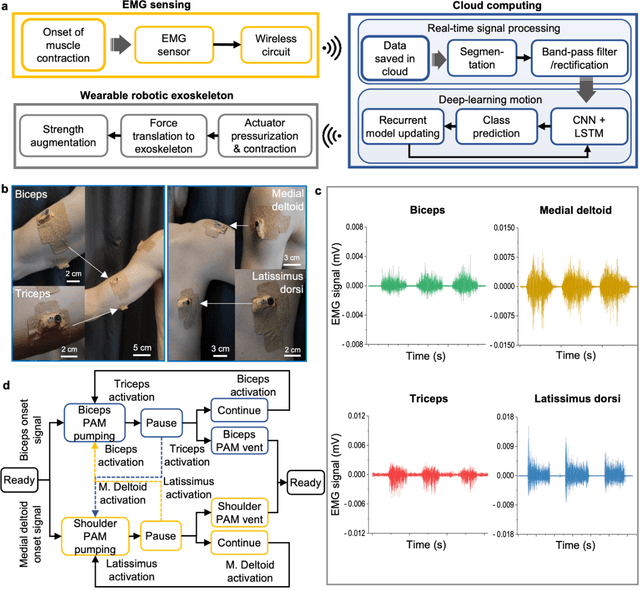
The age and stroke-associated decline in musculoskeletal strength degrades the ability to perform daily human tasks using the upper extremities. Although there are a few examples of exoskeletons, they need manual operations due to the absence of sensor feedback and no intention prediction of movements. Here, we introduce an intelligent upper-limb exoskeleton system that uses cloud-based deep learning to predict human intention for strength augmentation. The embedded soft wearable sensors provide sensory feedback by collecting real-time muscle signals, which are simultaneously computed to determine the user's intended movement. The cloud-based deep-learning predicts four upper-limb joint motions with an average accuracy of 96.2% at a 200-250 millisecond response rate, suggesting that the exoskeleton operates just by human intention. In addition, an array of soft pneumatics assists the intended movements by providing 897 newton of force and 78.7 millimeter of displacement at maximum. Collectively, the intent-driven exoskeleton can augment human strength by 5.15 times on average compared to the unassisted exoskeleton. This report demonstrates an exoskeleton robot that augments the upper-limb joint movements by human intention based on a machine-learning cloud computing and sensory feedback.