 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Multilingual RAG Systems with Debiased Language Preference-Guided Query Fusion
Jan 06, 2026Multilingual Retrieval-Augmented Generation (mRAG) systems often exhibit a perceived preference for high-resource languages, particularly English, resulting in the widespread adoption of English pivoting. While prior studies attribute this advantage to the superior English-centric capabilities of Large Language Models (LLMs), we find that such measurements are significantly distorted by structural priors inherent in evaluation benchmarks. Specifically, we identify exposure bias and a gold availability prior-both driven by the disproportionate concentration of resources in English-as well as cultural priors rooted in topic locality, as factors that hinder accurate assessment of genuine language preference. To address these biases, we propose DeLP (Debiased Language Preference), a calibrated metric designed to explicitly factor out these structural confounds. Our analysis using DeLP reveals that the previously reported English preference is largely a byproduct of evidence distribution rather than an inherent model bias. Instead, we find that retrievers fundamentally favor monolingual alignment between the query and the document language. Building on this insight, we introduce DELTA (DEbiased Language preference-guided Text Augmentation), a lightweight and efficient mRAG framework that strategically leverages monolingual alignment to optimize cross-lingual retrieval and generation. Experimental results demonstrate that DELTA consistently outperforms English pivoting and mRAG baselines across diverse languages.
Chronological Passage Assembling in RAG framework for Temporal Question Answering
Aug 26, 2025
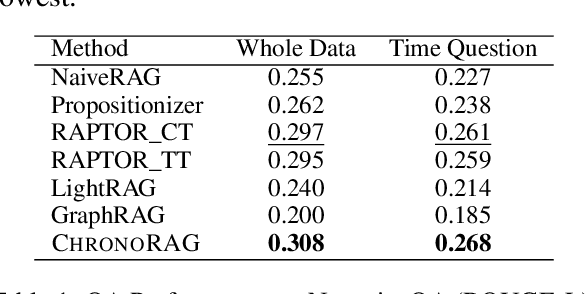

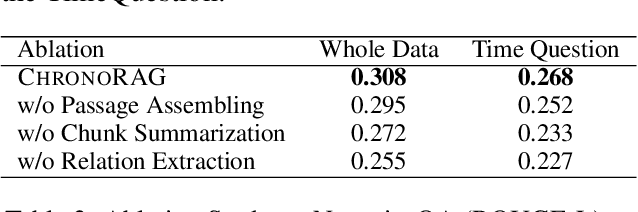
Long-context question answering over narrative tasks is challenging because correct answers often hinge on reconstructing a coherent timeline of events while preserving contextual flow in a limited context window. Retrieval-augmented generation (RAG) indexing methods aim to address this challenge by selectively retrieving only necessary document segments. However, narrative texts possess unique characteristics that limit the effectiveness of these existing approaches. Specifically, understanding narrative texts requires more than isolated segments, as the broader context and sequential relationships between segments are crucial for comprehension. To address these limitations, we propose ChronoRAG, a novel RAG framework specialized for narrative texts. This approach focuses on two essential aspects: refining dispersed document information into coherent and structured passages, and preserving narrative flow by explicitly capturing and maintaining the temporal order among retrieved passages. We empirically demonstrate the effectiveness of ChronoRAG through experiments on the NarrativeQA dataset, showing substantial improvements in tasks requiring both factual identification and comprehension of complex sequential relationships, underscoring that reasoning over temporal order is crucial in resolving narrative QA.
Hallucinate at the Last in Long Response Generation: A Case Study on Long Document Summarization
May 21, 2025Large Language Models (LLMs) have significantly advanced text generation capabilities, including tasks like summarization, often producing coherent and fluent outputs. However, faithfulness to source material remains a significant challenge due to the generation of hallucinations. While extensive research focuses on detecting and reducing these inaccuracies, less attention has been paid to the positional distribution of hallucination within generated text, particularly in long outputs. In this work, we investigate where hallucinations occur in LLM-based long response generation, using long document summarization as a key case study. Focusing on the challenging setting of long context-aware long response generation, we find a consistent and concerning phenomenon: hallucinations tend to concentrate disproportionately in the latter parts of the generated long response. To understand this bias, we explore potential contributing factors related to the dynamics of attention and decoding over long sequences. Furthermore, we investigate methods to mitigate this positional hallucination, aiming to improve faithfulness specifically in the concluding segments of long outputs.
Personality Editing for Language Models through Relevant Knowledge Editing
Feb 17, 2025Large Language Models (LLMs) play a vital role in applications like conversational agents and content creation, where controlling a model's personality is crucial for maintaining tone, consistency, and engagement. However, traditional prompt-based techniques for controlling personality often fall short, as they do not effectively mitigate the model's inherent biases. In this paper, we introduce a novel method PALETTE that enhances personality control through knowledge editing. By generating adjustment queries inspired by psychological assessments, our approach systematically adjusts responses to personality-related queries similar to modifying factual knowledge, thereby achieving controlled shifts in personality traits. Experimental results from both automatic and human evaluations demonstrate that our method enables more stable and well-balanced personality control in LLMs.
SAFE-SQL: Self-Augmented In-Context Learning with Fine-grained Example Selection for Text-to-SQL
Feb 17, 2025Text-to-SQL aims to convert natural language questions into executable SQL queries. While previous approaches, such as skeleton-masked selection, have demonstrated strong performance by retrieving similar training examples to guide large language models (LLMs), they struggle in real-world scenarios where such examples are unavailable. To overcome this limitation, we propose Self-Augmentation in-context learning with Fine-grained Example selection for Text-to-SQL (SAFE-SQL), a novel framework that improves SQL generation by generating and filtering self-augmented examples. SAFE-SQL first prompts an LLM to generate multiple Text-to-SQL examples relevant to the test input. Then SAFE-SQL filters these examples through three relevance assessments, constructing high-quality in-context learning examples. Using self-generated examples, SAFE-SQL surpasses the previous zero-shot, and few-shot Text-to-SQL frameworks, achieving higher execution accuracy. Notably, our approach provides additional performance gains in extra hard and unseen scenarios, where conventional methods often fail.
Probing-RAG: Self-Probing to Guide Language Models in Selective Document Retrieval
Oct 17, 2024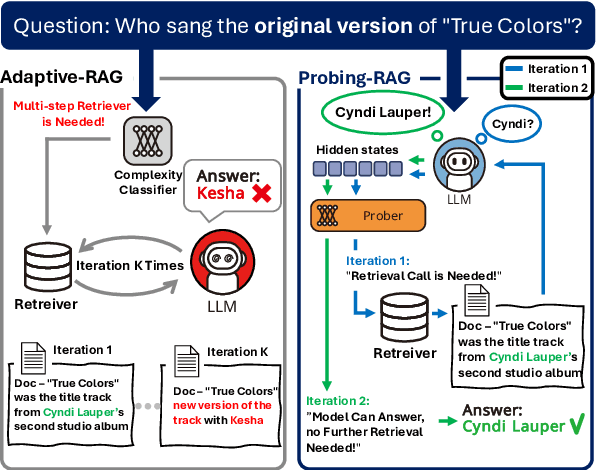
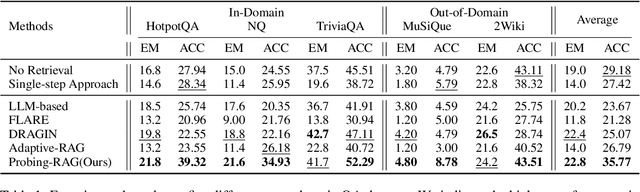
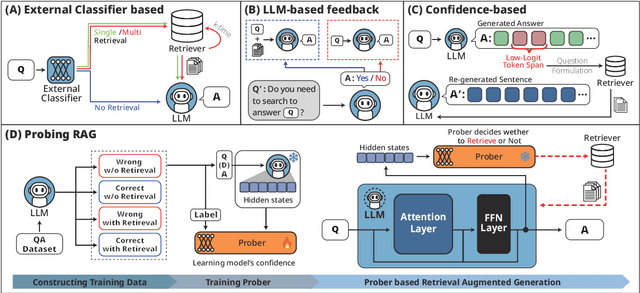
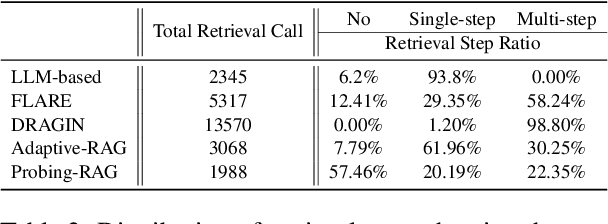
Retrieval-Augmented Generation (RAG) enhances language models by retrieving and incorporating relevant external knowledge. However, traditional retrieve-and-generate processes may not be optimized for real-world scenarios, where queries might require multiple retrieval steps or none at all. In this paper, we propose a Probing-RAG, which utilizes the hidden state representations from the intermediate layers of language models to adaptively determine the necessity of additional retrievals for a given query. By employing a pre-trained prober, Probing-RAG effectively captures the model's internal cognition, enabling reliable decision-making about retrieving external documents. Experimental results across five open-domain QA datasets demonstrate that Probing-RAG outperforms previous methods while reducing the number of redundant retrieval steps.
FIZZ: Factual Inconsistency Detection by Zoom-in Summary and Zoom-out Document
Apr 18, 2024Through the advent of pre-trained language models, there have been notable advancements in abstractive summarization systems. Simultaneously, a considerable number of novel methods for evaluating factual consistency in abstractive summarization systems has been developed. But these evaluation approaches incorporate substantial limitations, especially on refinement and interpretability. In this work, we propose highly effective and interpretable factual inconsistency detection method metric Factual Inconsistency Detection by Zoom-in Summary and Zoom-out Document for abstractive summarization systems that is based on fine-grained atomic facts decomposition. Moreover, we align atomic facts decomposed from the summary with the source document through adaptive granularity expansion. These atomic facts represent a more fine-grained unit of information, facilitating detailed understanding and interpretability of the summary's factual inconsistency. Experimental results demonstrate that our proposed factual consistency checking system significantly outperforms existing systems.