 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoc-PP: Document Policy Preservation Benchmark for Large Vision-Language Models
Jan 07, 2026The deployment of Large Vision-Language Models (LVLMs) for real-world document question answering is often constrained by dynamic, user-defined policies that dictate information disclosure based on context. While ensuring adherence to these explicit constraints is critical, existing safety research primarily focuses on implicit social norms or text-only settings, overlooking the complexities of multimodal documents. In this paper, we introduce Doc-PP (Document Policy Preservation Benchmark), a novel benchmark constructed from real-world reports requiring reasoning across heterogeneous visual and textual elements under strict non-disclosure policies. Our evaluation highlights a systemic Reasoning-Induced Safety Gap: models frequently leak sensitive information when answers must be inferred through complex synthesis or aggregated across modalities, effectively circumventing existing safety constraints. Furthermore, we identify that providing extracted text improves perception but inadvertently facilitates leakage. To address these vulnerabilities, we propose DVA (Decompose-Verify-Aggregation), a structural inference framework that decouples reasoning from policy verification. Experimental results demonstrate that DVA significantly outperforms standard prompting defenses, offering a robust baseline for policy-compliant document understanding
K-EXAONE Technical Report
Jan 05, 2026This technical report presents K-EXAONE, a large-scale multilingual language model developed by LG AI Research. K-EXAONE is built on a Mixture-of-Experts architecture with 236B total parameters, activating 23B parameters during inference. It supports a 256K-token context window and covers six languages: Korean, English, Spanish, German, Japanese, and Vietnamese. We evaluate K-EXAONE on a comprehensive benchmark suite spanning reasoning, agentic, general, Korean, and multilingual abilities. Across these evaluations, K-EXAONE demonstrates performance comparable to open-weight models of similar size. K-EXAONE, designed to advance AI for a better life, is positioned as a powerful proprietary AI foundation model for a wide range of industrial and research applications.
How Do Large Vision-Language Models See Text in Image? Unveiling the Distinctive Role of OCR Heads
May 21, 2025Despite significant advancements in Large Vision Language Models (LVLMs), a gap remains, particularly regarding their interpretability and how they locate and interpret textual information within images. In this paper, we explore various LVLMs to identify the specific heads responsible for recognizing text from images, which we term the Optical Character Recognition Head (OCR Head). Our findings regarding these heads are as follows: (1) Less Sparse: Unlike previous retrieval heads, a large number of heads are activated to extract textual information from images. (2) Qualitatively Distinct: OCR heads possess properties that differ significantly from general retrieval heads, exhibiting low similarity in their characteristics. (3) Statically Activated: The frequency of activation for these heads closely aligns with their OCR scores. We validate our findings in downstream tasks by applying Chain-of-Thought (CoT) to both OCR and conventional retrieval heads and by masking these heads. We also demonstrate that redistributing sink-token values within the OCR heads improves performance. These insights provide a deeper understanding of the internal mechanisms LVLMs employ in processing embedded textual information in images.
Hallucinate at the Last in Long Response Generation: A Case Study on Long Document Summarization
May 21, 2025Large Language Models (LLMs) have significantly advanced text generation capabilities, including tasks like summarization, often producing coherent and fluent outputs. However, faithfulness to source material remains a significant challenge due to the generation of hallucinations. While extensive research focuses on detecting and reducing these inaccuracies, less attention has been paid to the positional distribution of hallucination within generated text, particularly in long outputs. In this work, we investigate where hallucinations occur in LLM-based long response generation, using long document summarization as a key case study. Focusing on the challenging setting of long context-aware long response generation, we find a consistent and concerning phenomenon: hallucinations tend to concentrate disproportionately in the latter parts of the generated long response. To understand this bias, we explore potential contributing factors related to the dynamics of attention and decoding over long sequences. Furthermore, we investigate methods to mitigate this positional hallucination, aiming to improve faithfulness specifically in the concluding segments of long outputs.
Keep Security! Benchmarking Security Policy Preservation in Large Language Model Contexts Against Indirect Attacks in Question Answering
May 21, 2025As Large Language Models (LLMs) are increasingly deployed in sensitive domains such as enterprise and government, ensuring that they adhere to user-defined security policies within context is critical-especially with respect to information non-disclosure. While prior LLM studies have focused on general safety and socially sensitive data, large-scale benchmarks for contextual security preservation against attacks remain lacking. To address this, we introduce a novel large-scale benchmark dataset, CoPriva, evaluating LLM adherence to contextual non-disclosure policies in question answering. Derived from realistic contexts, our dataset includes explicit policies and queries designed as direct and challenging indirect attacks seeking prohibited information. We evaluate 10 LLMs on our benchmark and reveal a significant vulnerability: many models violate user-defined policies and leak sensitive information. This failure is particularly severe against indirect attacks, highlighting a critical gap in current LLM safety alignment for sensitive applications. Our analysis reveals that while models can often identify the correct answer to a query, they struggle to incorporate policy constraints during generation. In contrast, they exhibit a partial ability to revise outputs when explicitly prompted. Our findings underscore the urgent need for more robust methods to guarantee contextual security.
Which Retain Set Matters for LLM Unlearning? A Case Study on Entity Unlearning
Feb 17, 2025



Large language models (LLMs) risk retaining unauthorized or sensitive information from their training data, which raises privacy concerns. LLM unlearning seeks to mitigate these risks by selectively removing specified data while maintaining overall model performance. However, most existing work focus on methods to achieve effective forgetting and does not provide a detailed analysis of the retain set, the portion of training data that is not targeted for removal. In this paper, we investigate the effects of unlearning on various subsets of the retain set through a case study on entity unlearning. We introduce the Syntactically Similar Neighbor Set, a group of queries that share similar syntactic structures with the data targeted for removal, and show that this subset suffers the greatest performance drop during unlearning. Moreover, when used for regularization, this set not only preserves performance on syntactically similar queries but also delivers comparable or improved results across other data subsets. Our results highlight that syntactic similarity is a critical factor, potentially more so than domain or entity relationships, in achieving effective and practical LLM unlearning.
Probing-RAG: Self-Probing to Guide Language Models in Selective Document Retrieval
Oct 17, 2024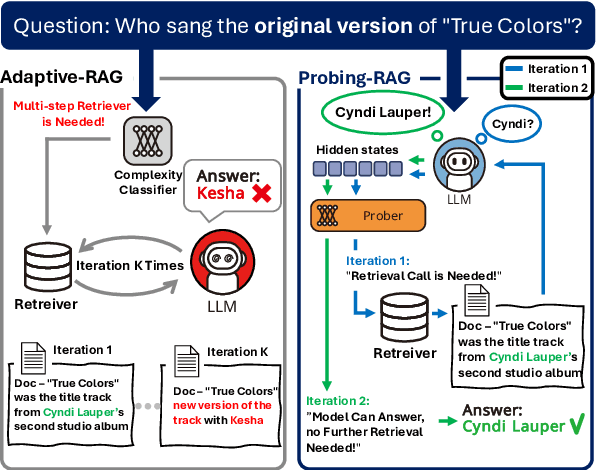
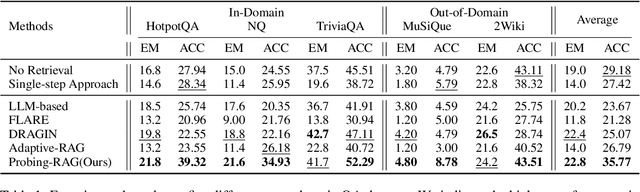
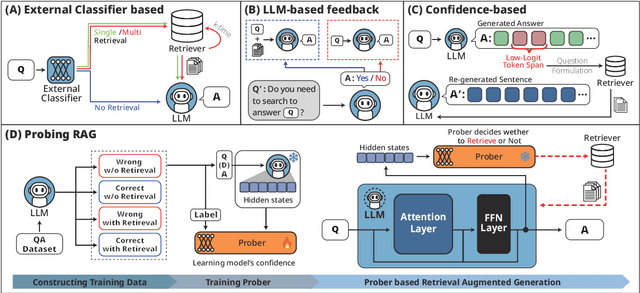
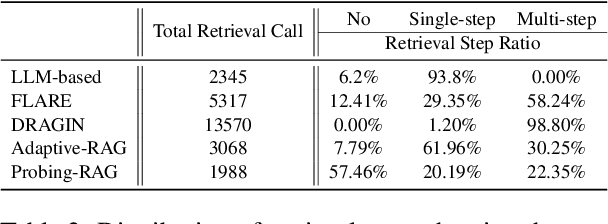
Retrieval-Augmented Generation (RAG) enhances language models by retrieving and incorporating relevant external knowledge. However, traditional retrieve-and-generate processes may not be optimized for real-world scenarios, where queries might require multiple retrieval steps or none at all. In this paper, we propose a Probing-RAG, which utilizes the hidden state representations from the intermediate layers of language models to adaptively determine the necessity of additional retrievals for a given query. By employing a pre-trained prober, Probing-RAG effectively captures the model's internal cognition, enabling reliable decision-making about retrieving external documents. Experimental results across five open-domain QA datasets demonstrate that Probing-RAG outperforms previous methods while reducing the number of redundant retrieval steps.