 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCode-Switching Reveals Language Anchoring in Multilingual LLMs
Jun 18, 2026Multilingual Large Language Models (MLLMs) are increasingly expected to handle Code-Switched (CS) inputs, yet mixing languages frequently degrades performance relative to source- or target-language monolingual counterparts. To understand this degradation, we use grammar-forced CS as a controlled diagnostic setting for locating CS representations relative to their source and target counterparts. We introduce Anchor Bias, a geometric measure that quantifies language anchoring, whether a CS hidden state aligns closer to its source or target language counterpart. Across diverse MLLMs, Anchor Bias reveals a consistent grammar-frame effect: source-framed CS stays source-anchored, whereas target-framed CS shifts target-ward and shows larger Question Answering (QA) degradation. Motivated by this representational pattern, we propose CANVAS (Contextual Anchor-based Neural Vector Alignment Steering), an inference-time intervention that extracts a source-side canvas from the input and softly steers target-language hidden states toward the source anchor during prefill. CANVAS consistently recovers QA F1 across MLLMs and CS conditions, showing that internal anchoring signals provide an actionable target for mitigating CS inference failures.
Beyond One Path: Evaluating and Enhancing Divergent Thinking in Interactive LLM Agents
May 27, 2026Divergent thinking is a core dimension of creativity, yet existing evaluations of Large Language Models (LLMs) treat them as single-turn text generations, failing to capture how an agent reasons through iterative interaction. To address this, we introduce MUTATE, an interactive benchmark designed to evaluate agentic divergent thinking at two levels: path-level, where an agent discovers multiple alternative paths to the same goal, and action-level, where individual actions require non-typical, mechanism-shifting object uses. Unlike success-only evaluations, MUTATE scores both completed paths and off-path attempts, capturing divergent reasoning that conventional success rates discard. Our experiments with frontier LLMs reveal a structural blind spot in existing frameworks: when exposed to immediate convergence pressure, they tend to fall into immediate action fixation, failing to improve action-level divergence. To overcome this, we propose ReDNA, which separates unconstrained divergent candidate generation from convergent constraint selection. ReDNA significantly outperforms prior methods across both divergence levels and generalizes effectively to an external creativity environment. We also confirm its success stems from a qualitative enhancement of resilient divergent reasoning rather than simple environmental exploration.
Framing Matters: Addressing Framing Sensitivity in Decision-Making through Behaviorally-Grounded Value Alignment
May 27, 2026Large Language Models (LLMs) are increasingly deployed in high-stakes decision-making settings such as legal reasoning, where consistency under factually equivalent inputs is critical. However, we find that fact-preserved but differently framed inputs can significantly destabilize LLM decisions. To systematically investigate this problem, we introduce Fragile, a large-scale benchmark that isolates fact-preserving semantic framing across three controlled dimensions: value-tinted narration, temporal slice, and narrative vividness. Our experiments reveal a high susceptibility of LLMs to framing, with an average decision flip rate of 28.6%. We find that simple prior prompt-level and activation-level interventions not only fail to suppress framing sensitivity but actively amplify it. We therefore propose Valign, a representation-level method that explicitly targets these framing dimensions by anchoring decisions to a stable value prior, steering hidden states toward the model's value-consistent direction, and projecting out temporal-vividness-sensitive directions from the model's hidden states. Valign consistently reduces framing-induced decision flips, demonstrating that robust mitigation requires directly targeting the internal pathways in which framing operates.
Mitigating Cognitive Inertia in Large Reasoning Models via Latent Spike Steering
Jan 30, 2026While Large Reasoning Models (LRMs) have achieved remarkable performance by scaling test-time compute, they frequently suffer from Cognitive Inertia, a failure pattern manifesting as either overthinking (inertia of motion) or reasoning rigidity (inertia of direction). Existing detection methods, typically relying on superficial textual heuristics like self-correction tokens, often fail to capture the model's unvoiced internal conflicts. To address this, we propose STARS (Spike-Triggered Adaptive Reasoning Steering), a training-free framework designed to rectify cognitive inertia by monitoring latent dynamics. STARS identifies Cognitive Pivots-critical moments of reasoning transition-by detecting distinct L2 distance spikes in the hidden states. Upon detection, the framework employs geometric trajectory analysis to diagnose the structural nature of the transition and injects state-aware language cues to steer the model in real-time. Our experiments across diverse benchmarks confirm that STARS efficiently curtails redundant loops while improving accuracy through the adaptive correction of erroneous trajectories. STARS offers a robust, unsupervised mechanism to optimize the reasoning process of LRMs without requiring additional fine-tuning.
MultiLexNorm++: A Unified Benchmark and a Generative Model for Lexical Normalization for Asian Languages
Jan 23, 2026Social media data has been of interest to Natural Language Processing (NLP) practitioners for over a decade, because of its richness in information, but also challenges for automatic processing. Since language use is more informal, spontaneous, and adheres to many different sociolects, the performance of NLP models often deteriorates. One solution to this problem is to transform data to a standard variant before processing it, which is also called lexical normalization. There has been a wide variety of benchmarks and models proposed for this task. The MultiLexNorm benchmark proposed to unify these efforts, but it consists almost solely of languages from the Indo-European language family in the Latin script. Hence, we propose an extension to MultiLexNorm, which covers 5 Asian languages from different language families in 4 different scripts. We show that the previous state-of-the-art model performs worse on the new languages and propose a new architecture based on Large Language Models (LLMs), which shows more robust performance. Finally, we analyze remaining errors, revealing future directions for this task.
Fame Fades, Nature Remains: Disentangling the Character Identity of Role-Playing Agents
Jan 08, 2026Despite the rapid proliferation of Role-Playing Agents (RPAs) based on Large Language Models (LLMs), the structural dimensions defining a character's identity remain weakly formalized, often treating characters as arbitrary text inputs. In this paper, we propose the concept of \textbf{Character Identity}, a multidimensional construct that disentangles a character into two distinct layers: \textbf{(1) Parametric Identity}, referring to character-specific knowledge encoded from the LLM's pre-training, and \textbf{(2) Attributive Identity}, capturing fine-grained behavioral properties such as personality traits and moral values. To systematically investigate these layers, we construct a unified character profile schema and generate both Famous and Synthetic characters under identical structural constraints. Our evaluation across single-turn and multi-turn interactions reveals two critical phenomena. First, we identify \textit{"Fame Fades"}: while famous characters hold a significant advantage in initial turns due to parametric knowledge, this edge rapidly vanishes as models prioritize accumulating conversational context over pre-trained priors. Second, we find that \textit{"Nature Remains"}: while models robustly portray general personality traits regardless of polarity, RPA performance is highly sensitive to the valence of morality and interpersonal relationships. Our findings pinpoint negative social natures as the primary bottleneck in RPA fidelity, guiding future character construction and evaluation.
Doc-PP: Document Policy Preservation Benchmark for Large Vision-Language Models
Jan 07, 2026The deployment of Large Vision-Language Models (LVLMs) for real-world document question answering is often constrained by dynamic, user-defined policies that dictate information disclosure based on context. While ensuring adherence to these explicit constraints is critical, existing safety research primarily focuses on implicit social norms or text-only settings, overlooking the complexities of multimodal documents. In this paper, we introduce Doc-PP (Document Policy Preservation Benchmark), a novel benchmark constructed from real-world reports requiring reasoning across heterogeneous visual and textual elements under strict non-disclosure policies. Our evaluation highlights a systemic Reasoning-Induced Safety Gap: models frequently leak sensitive information when answers must be inferred through complex synthesis or aggregated across modalities, effectively circumventing existing safety constraints. Furthermore, we identify that providing extracted text improves perception but inadvertently facilitates leakage. To address these vulnerabilities, we propose DVA (Decompose-Verify-Aggregation), a structural inference framework that decouples reasoning from policy verification. Experimental results demonstrate that DVA significantly outperforms standard prompting defenses, offering a robust baseline for policy-compliant document understanding
Enhancing Multilingual RAG Systems with Debiased Language Preference-Guided Query Fusion
Jan 06, 2026Multilingual Retrieval-Augmented Generation (mRAG) systems often exhibit a perceived preference for high-resource languages, particularly English, resulting in the widespread adoption of English pivoting. While prior studies attribute this advantage to the superior English-centric capabilities of Large Language Models (LLMs), we find that such measurements are significantly distorted by structural priors inherent in evaluation benchmarks. Specifically, we identify exposure bias and a gold availability prior-both driven by the disproportionate concentration of resources in English-as well as cultural priors rooted in topic locality, as factors that hinder accurate assessment of genuine language preference. To address these biases, we propose DeLP (Debiased Language Preference), a calibrated metric designed to explicitly factor out these structural confounds. Our analysis using DeLP reveals that the previously reported English preference is largely a byproduct of evidence distribution rather than an inherent model bias. Instead, we find that retrievers fundamentally favor monolingual alignment between the query and the document language. Building on this insight, we introduce DELTA (DEbiased Language preference-guided Text Augmentation), a lightweight and efficient mRAG framework that strategically leverages monolingual alignment to optimize cross-lingual retrieval and generation. Experimental results demonstrate that DELTA consistently outperforms English pivoting and mRAG baselines across diverse languages.
Chronological Passage Assembling in RAG framework for Temporal Question Answering
Aug 26, 2025
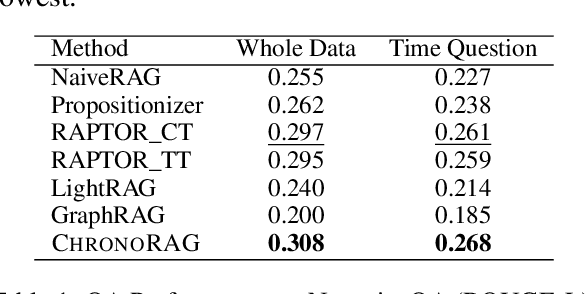

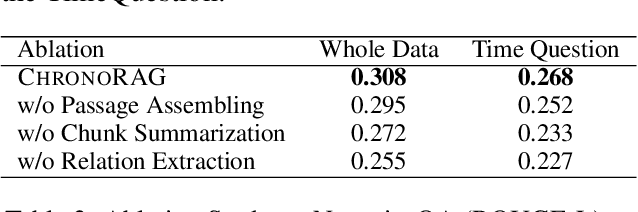
Long-context question answering over narrative tasks is challenging because correct answers often hinge on reconstructing a coherent timeline of events while preserving contextual flow in a limited context window. Retrieval-augmented generation (RAG) indexing methods aim to address this challenge by selectively retrieving only necessary document segments. However, narrative texts possess unique characteristics that limit the effectiveness of these existing approaches. Specifically, understanding narrative texts requires more than isolated segments, as the broader context and sequential relationships between segments are crucial for comprehension. To address these limitations, we propose ChronoRAG, a novel RAG framework specialized for narrative texts. This approach focuses on two essential aspects: refining dispersed document information into coherent and structured passages, and preserving narrative flow by explicitly capturing and maintaining the temporal order among retrieved passages. We empirically demonstrate the effectiveness of ChronoRAG through experiments on the NarrativeQA dataset, showing substantial improvements in tasks requiring both factual identification and comprehension of complex sequential relationships, underscoring that reasoning over temporal order is crucial in resolving narrative QA.
ToDi: Token-wise Distillation via Fine-Grained Divergence Control
May 22, 2025Large language models (LLMs) offer impressive performance but are impractical for resource-constrained deployment due to high latency and energy consumption. Knowledge distillation (KD) addresses this by transferring knowledge from a large teacher to a smaller student model. However, conventional KD, notably approaches like Forward KL (FKL) and Reverse KL (RKL), apply uniform divergence loss across the entire vocabulary, neglecting token-level prediction discrepancies. By investigating these representative divergences via gradient analysis, we reveal that FKL boosts underestimated tokens, while RKL suppresses overestimated ones, showing their complementary roles. Based on this observation, we propose Token-wise Distillation (ToDi), a novel method that adaptively combines FKL and RKL per token using a sigmoid-based weighting function derived from the teacher-student probability log-ratio. ToDi dynamically emphasizes the appropriate divergence for each token, enabling precise distribution alignment. We demonstrate that ToDi consistently outperforms recent distillation baselines using uniform or less granular strategies across instruction-following benchmarks. Extensive ablation studies and efficiency analysis further validate ToDi's effectiveness and practicality.