 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond One Path: Evaluating and Enhancing Divergent Thinking in Interactive LLM Agents
May 27, 2026Divergent thinking is a core dimension of creativity, yet existing evaluations of Large Language Models (LLMs) treat them as single-turn text generations, failing to capture how an agent reasons through iterative interaction. To address this, we introduce MUTATE, an interactive benchmark designed to evaluate agentic divergent thinking at two levels: path-level, where an agent discovers multiple alternative paths to the same goal, and action-level, where individual actions require non-typical, mechanism-shifting object uses. Unlike success-only evaluations, MUTATE scores both completed paths and off-path attempts, capturing divergent reasoning that conventional success rates discard. Our experiments with frontier LLMs reveal a structural blind spot in existing frameworks: when exposed to immediate convergence pressure, they tend to fall into immediate action fixation, failing to improve action-level divergence. To overcome this, we propose ReDNA, which separates unconstrained divergent candidate generation from convergent constraint selection. ReDNA significantly outperforms prior methods across both divergence levels and generalizes effectively to an external creativity environment. We also confirm its success stems from a qualitative enhancement of resilient divergent reasoning rather than simple environmental exploration.
Enhancing Multilingual RAG Systems with Debiased Language Preference-Guided Query Fusion
Jan 06, 2026Multilingual Retrieval-Augmented Generation (mRAG) systems often exhibit a perceived preference for high-resource languages, particularly English, resulting in the widespread adoption of English pivoting. While prior studies attribute this advantage to the superior English-centric capabilities of Large Language Models (LLMs), we find that such measurements are significantly distorted by structural priors inherent in evaluation benchmarks. Specifically, we identify exposure bias and a gold availability prior-both driven by the disproportionate concentration of resources in English-as well as cultural priors rooted in topic locality, as factors that hinder accurate assessment of genuine language preference. To address these biases, we propose DeLP (Debiased Language Preference), a calibrated metric designed to explicitly factor out these structural confounds. Our analysis using DeLP reveals that the previously reported English preference is largely a byproduct of evidence distribution rather than an inherent model bias. Instead, we find that retrievers fundamentally favor monolingual alignment between the query and the document language. Building on this insight, we introduce DELTA (DEbiased Language preference-guided Text Augmentation), a lightweight and efficient mRAG framework that strategically leverages monolingual alignment to optimize cross-lingual retrieval and generation. Experimental results demonstrate that DELTA consistently outperforms English pivoting and mRAG baselines across diverse languages.
Chronological Passage Assembling in RAG framework for Temporal Question Answering
Aug 26, 2025
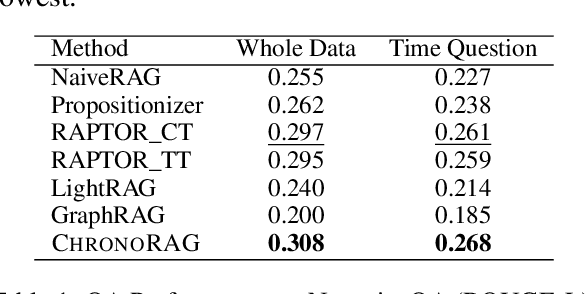

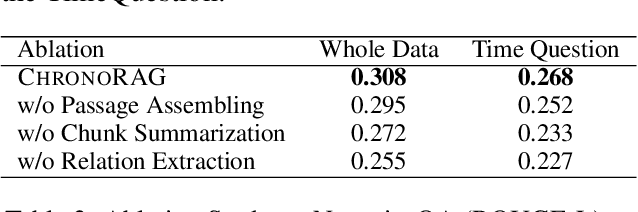
Long-context question answering over narrative tasks is challenging because correct answers often hinge on reconstructing a coherent timeline of events while preserving contextual flow in a limited context window. Retrieval-augmented generation (RAG) indexing methods aim to address this challenge by selectively retrieving only necessary document segments. However, narrative texts possess unique characteristics that limit the effectiveness of these existing approaches. Specifically, understanding narrative texts requires more than isolated segments, as the broader context and sequential relationships between segments are crucial for comprehension. To address these limitations, we propose ChronoRAG, a novel RAG framework specialized for narrative texts. This approach focuses on two essential aspects: refining dispersed document information into coherent and structured passages, and preserving narrative flow by explicitly capturing and maintaining the temporal order among retrieved passages. We empirically demonstrate the effectiveness of ChronoRAG through experiments on the NarrativeQA dataset, showing substantial improvements in tasks requiring both factual identification and comprehension of complex sequential relationships, underscoring that reasoning over temporal order is crucial in resolving narrative QA.
Conversational Query Reformulation with the Guidance of Retrieved Documents
Jul 17, 2024



Conversational search seeks to retrieve relevant passages for the given questions in Conversational QA (ConvQA). Questions in ConvQA face challenges such as omissions and coreferences, making it difficult to obtain desired search results. Conversational Query Reformulation (CQR) transforms these current queries into de-contextualized forms to resolve these issues. However, existing CQR methods focus on rewriting human-friendly queries, which may not always yield optimal search results for the retriever. To overcome this challenge, we introduce GuideCQR, a framework that utilizes guided documents to refine queries, ensuring that they are optimal for retrievers. Specifically, we augment keywords, generate expected answers from the re-ranked documents, and unify them with the filtering process. Experimental results show that queries enhanced by guided documents outperform previous CQR methods. Especially, GuideCQR surpasses the performance of Large Language Model (LLM) prompt-powered approaches and demonstrates the importance of the guided documents in formulating retriever-friendly queries across diverse setups.