 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoal-Driven Autonomous Mapping Through Deep Reinforcement Learning and Planning-Based Navigation
Mar 12, 2021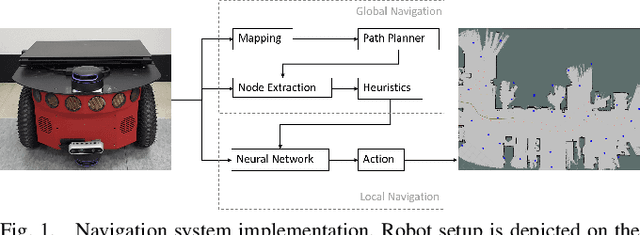
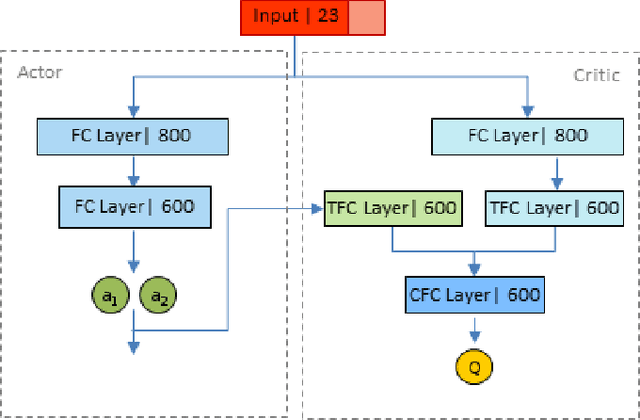

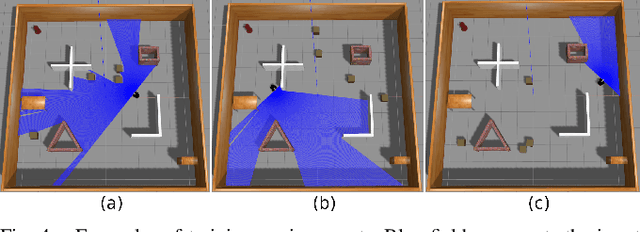
In this paper, we present a goal-driven autonomous mapping and exploration system that combines reactive and planned robot navigation. First, a navigation policy is learned through a deep reinforcement learning (DRL) framework in a simulated environment. This policy guides an autonomous agent towards a goal while avoiding obstacles. We develop a navigation system where this learned policy is integrated into a motion planning stack as the local navigation layer to move the robot towards the intermediate goals. A global path planner is used to mitigate the local optimum problem and guide the robot towards the global goal. Possible intermediate goal locations are extracted from the environment and used as local goals according to the navigation system heuristics. The fully autonomous navigation is performed without any prior knowledge while mapping is performed as the robot moves through the environment. Experiments show the capability of the system navigating in previously unknown surroundings and arriving at the designated goal.
Acceleration of Actor-Critic Deep Reinforcement Learning for Visual Grasping in Clutter by State Representation Learning Based on Disentanglement of a Raw Input Image
Feb 27, 2020
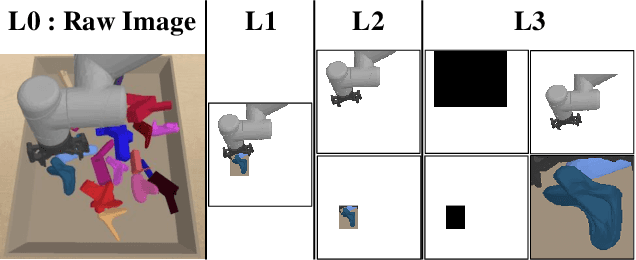
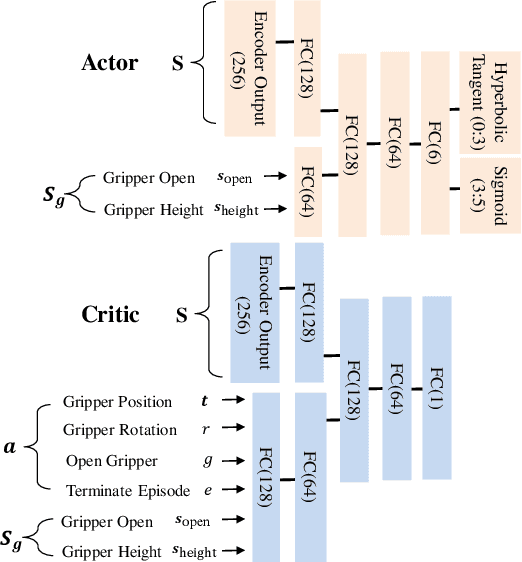
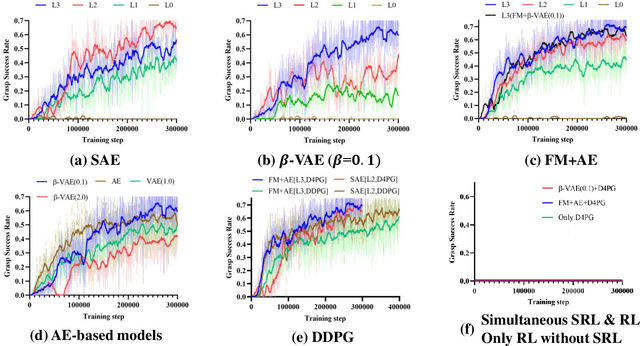
For a robotic grasping task in which diverse unseen target objects exist in a cluttered environment, some deep learning-based methods have achieved state-of-the-art results using visual input directly. In contrast, actor-critic deep reinforcement learning (RL) methods typically perform very poorly when grasping diverse objects, especially when learning from raw images and sparse rewards. To make these RL techniques feasible for vision-based grasping tasks, we employ state representation learning (SRL), where we encode essential information first for subsequent use in RL. However, typical representation learning procedures are unsuitable for extracting pertinent information for learning the grasping skill, because the visual inputs for representation learning, where a robot attempts to grasp a target object in clutter, are extremely complex. We found that preprocessing based on the disentanglement of a raw input image is the key to effectively capturing a compact representation. This enables deep RL to learn robotic grasping skills from highly varied and diverse visual inputs. We demonstrate the effectiveness of this approach with varying levels of disentanglement in a realistic simulated environment.
From Big to Small: Multi-Scale Local Planar Guidance for Monocular Depth Estimation
Aug 26, 2019



Estimating accurate depth from a single image is challenging, because it is an ill-posed problem as infinitely many 3D scenes can be projected to the same 2D scene. However, recent works based on deep convolutional neural networks show great progress achieving plausible results. The networks are generally composed of two parts: an encoder for dense feature extraction and a decoder for predicting the desired depth. In the encoder-decoder schemes, repeated strided convolution and spatial pooling layers lower the spatial resolution of transitional outputs, and several techniques such as skip connections or multi-layer deconvolutional networks are adopted to effectively recover back to the original resolution. In this paper, for a more effective guidance of densely encoded features to desired depth prediction, we propose a network architecture that utilizes novel local planar guidance layers located at multiple stages in decoding phase. We show that the proposed method outperforms the state-of-the-art works with significant margin evaluating on challenging benchmarks. We also provide results from an ablation study to validate the effectiveness of the proposed core factors.
Efficient Feature Matching by Progressive Candidate Search
Jan 20, 2017
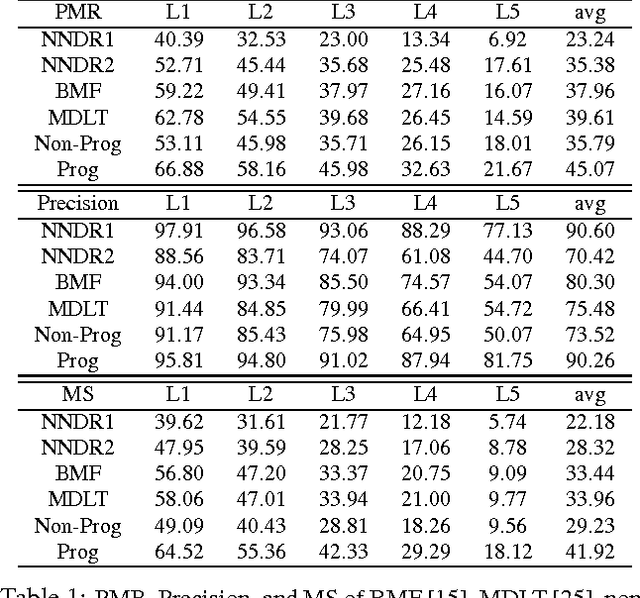
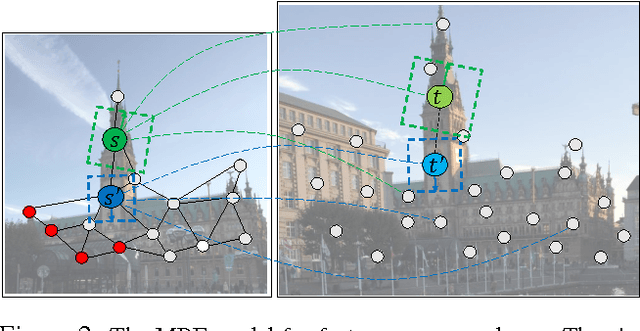
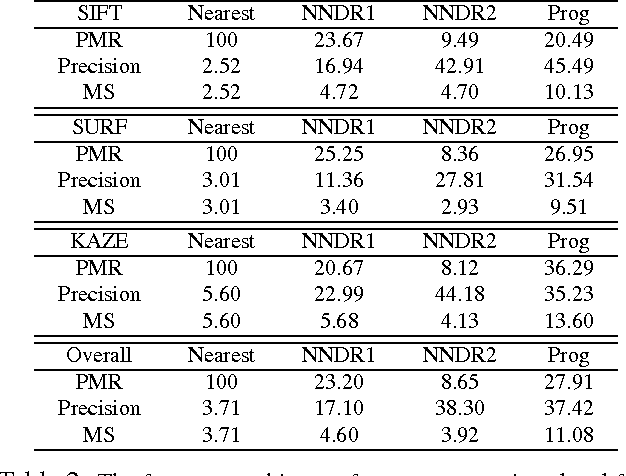
We present a novel feature matching algorithm that systematically utilizes the geometric properties of features such as position, scale, and orientation, in addition to the conventional descriptor vectors. In challenging scenes with the presence of repetitive patterns or with a large viewpoint change, it is hard to find the correct correspondences using feature descriptors only, since the descriptor distances of the correct matches may not be the least among the candidates due to appearance changes. Assuming that the layout of the nearby features does not changed much, we propose the bidirectional transfer measure to gauge the geometric consistency of a pair of feature correspondences. The feature matching problem is formulated as a Markov random field (MRF) which uses descriptor distances and relative geometric similarities together. The unmatched features are explicitly modeled in the MRF to minimize its negative impact. For speed and stability, instead of solving the MRF on the entire features at once, we start with a small set of confident feature matches, and then progressively search the candidates in nearby features and expand the MRF with them. Experimental comparisons show that the proposed algorithm finds better feature correspondences, i.e. more matches with higher inlier ratio, in many challenging scenes with much lower computational cost than the state-of-the-art algorithms.
Tracking Human-like Natural Motion Using Deep Recurrent Neural Networks
Apr 15, 2016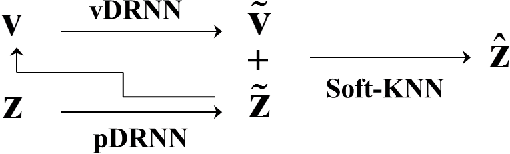
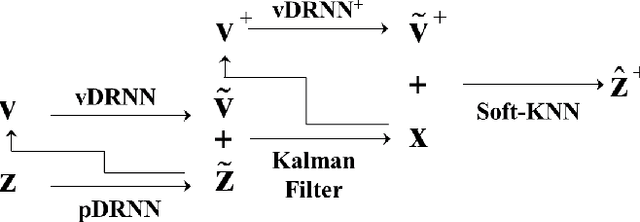

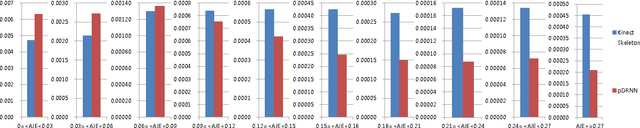
Kinect skeleton tracker is able to achieve considerable human body tracking performance in convenient and a low-cost manner. However, The tracker often captures unnatural human poses such as discontinuous and vibrated motions when self-occlusions occur. A majority of approaches tackle this problem by using multiple Kinect sensors in a workspace. Combination of the measurements from different sensors is then conducted in Kalman filter framework or optimization problem is formulated for sensor fusion. However, these methods usually require heuristics to measure reliability of measurements observed from each Kinect sensor. In this paper, we developed a method to improve Kinect skeleton using single Kinect sensor, in which supervised learning technique was employed to correct unnatural tracking motions. Specifically, deep recurrent neural networks were used for improving joint positions and velocities of Kinect skeleton, and three methods were proposed to integrate the refined positions and velocities for further enhancement. Moreover, we suggested a novel measure to evaluate naturalness of captured motions. We evaluated the proposed approach by comparison with the ground truth obtained using a commercial optical maker-based motion capture system.