 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAcceleration of Actor-Critic Deep Reinforcement Learning for Visual Grasping in Clutter by State Representation Learning Based on Disentanglement of a Raw Input Image
Paper and Code
Feb 27, 2020
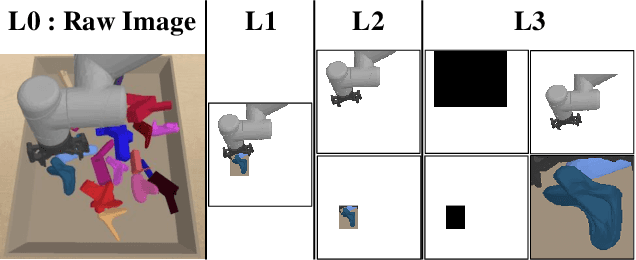
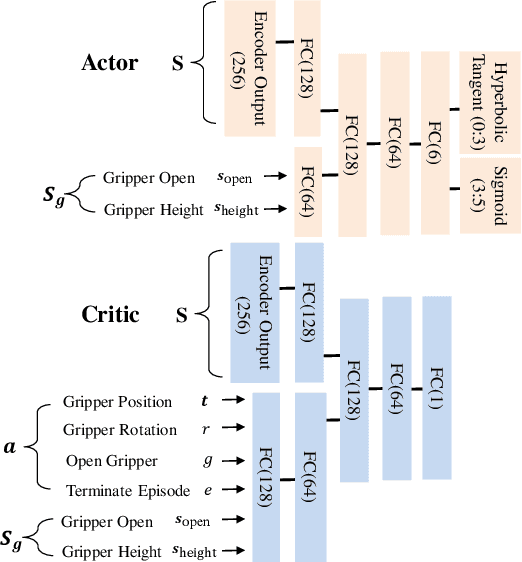
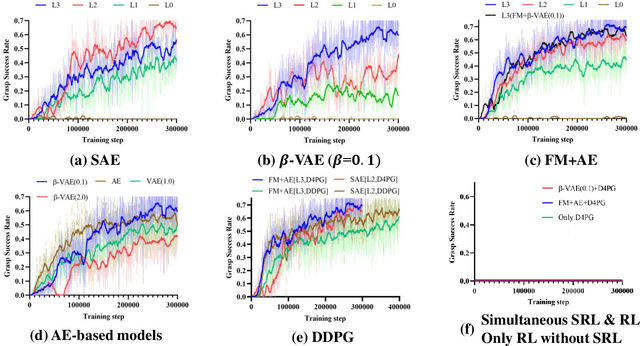
For a robotic grasping task in which diverse unseen target objects exist in a cluttered environment, some deep learning-based methods have achieved state-of-the-art results using visual input directly. In contrast, actor-critic deep reinforcement learning (RL) methods typically perform very poorly when grasping diverse objects, especially when learning from raw images and sparse rewards. To make these RL techniques feasible for vision-based grasping tasks, we employ state representation learning (SRL), where we encode essential information first for subsequent use in RL. However, typical representation learning procedures are unsuitable for extracting pertinent information for learning the grasping skill, because the visual inputs for representation learning, where a robot attempts to grasp a target object in clutter, are extremely complex. We found that preprocessing based on the disentanglement of a raw input image is the key to effectively capturing a compact representation. This enables deep RL to learn robotic grasping skills from highly varied and diverse visual inputs. We demonstrate the effectiveness of this approach with varying levels of disentanglement in a realistic simulated environment.