 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe MVTec AD 2 Dataset: Advanced Scenarios for Unsupervised Anomaly Detection
Mar 27, 2025In recent years, performance on existing anomaly detection benchmarks like MVTec AD and VisA has started to saturate in terms of segmentation AU-PRO, with state-of-the-art models often competing in the range of less than one percentage point. This lack of discriminatory power prevents a meaningful comparison of models and thus hinders progress of the field, especially when considering the inherent stochastic nature of machine learning results. We present MVTec AD 2, a collection of eight anomaly detection scenarios with more than 8000 high-resolution images. It comprises challenging and highly relevant industrial inspection use cases that have not been considered in previous datasets, including transparent and overlapping objects, dark-field and back light illumination, objects with high variance in the normal data, and extremely small defects. We provide comprehensive evaluations of state-of-the-art methods and show that their performance remains below 60% average AU-PRO. Additionally, our dataset provides test scenarios with lighting condition changes to assess the robustness of methods under real-world distribution shifts. We host a publicly accessible evaluation server that holds the pixel-precise ground truth of the test set (https://benchmark.mvtec.com/). All image data is available at https://www.mvtec.com/company/research/datasets/mvtec-ad-2.
EfficientAD: Accurate Visual Anomaly Detection at Millisecond-Level Latencies
Mar 25, 2023Detecting anomalies in images is an important task, especially in real-time computer vision applications. In this work, we focus on computational efficiency and propose a lightweight feature extractor that processes an image in less than a millisecond on a modern GPU. We then use a student-teacher approach to detect anomalous features. We train a student network to predict the extracted features of normal, i.e., anomaly-free training images. The detection of anomalies at test time is enabled by the student failing to predict their features. We propose a training loss that hinders the student from imitating the teacher feature extractor beyond the normal images. It allows us to drastically reduce the computational cost of the student-teacher model, while improving the detection of anomalous features. We furthermore address the detection of challenging logical anomalies that involve invalid combinations of normal local features, for example, a wrong ordering of objects. We detect these anomalies by efficiently incorporating an autoencoder that analyzes images globally. We evaluate our method, called EfficientAD, on 32 datasets from three industrial anomaly detection dataset collections. EfficientAD sets new standards for both the detection and the localization of anomalies. At a latency of two milliseconds and a throughput of six hundred images per second, it enables a fast handling of anomalies. Together with its low error rate, this makes it an economical solution for real-world applications and a fruitful basis for future research.
A Hybrid Approach for 6DoF Pose Estimation
Nov 11, 2020



We propose a method for 6DoF pose estimation of rigid objects that uses a state-of-the-art deep learning based instance detector to segment object instances in an RGB image, followed by a point-pair based voting method to recover the object's pose. We additionally use an automatic method selection that chooses the instance detector and the training set as that with the highest performance on the validation set. This hybrid approach leverages the best of learning and classic approaches, using CNNs to filter highly unstructured data and cut through the clutter, and a local geometric approach with proven convergence for robust pose estimation. The method is evaluated on the BOP core datasets where it significantly exceeds the baseline method and is the best fast method in the BOP 2020 Challenge.
Oriented Boxes for Accurate Instance Segmentation
Nov 27, 2019
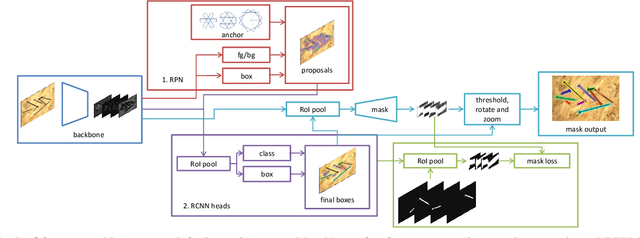

State-of-the-art instance-aware semantic segmentation algorithms use axis-aligned bounding boxes as an intermediate processing step to infer the final instance mask output. This leads to coarse and inaccurate mask proposals due to the following reasons: Axis-aligned boxes have a high background to foreground pixel-ratio, there is a strong variation of mask targets with respect to the underlying box, and neighboring instances frequently reach into the axis-aligned bounding box of the instance mask of interest. In this work, we overcome these problems and propose using oriented boxes as the basis to infer instance masks. We show that oriented instance segmentation leads to very accurate mask predictions, especially when objects are diagonally aligned, touching, or overlapping each other. We evaluate our model on the D2S and Screws datasets and show that we can significantly improve the mask accuracy by 7% and 11% mAP (14.9% and 27.5% relative improvement), respectively.
MVTec D2S: Densely Segmented Supermarket Dataset
Jul 25, 2018
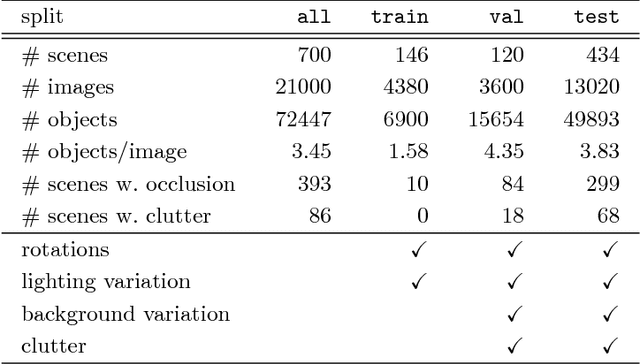

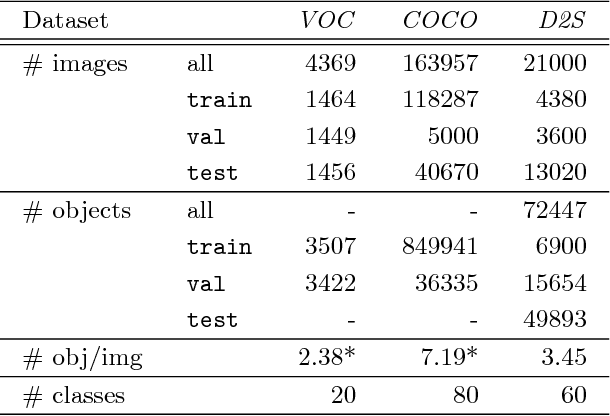
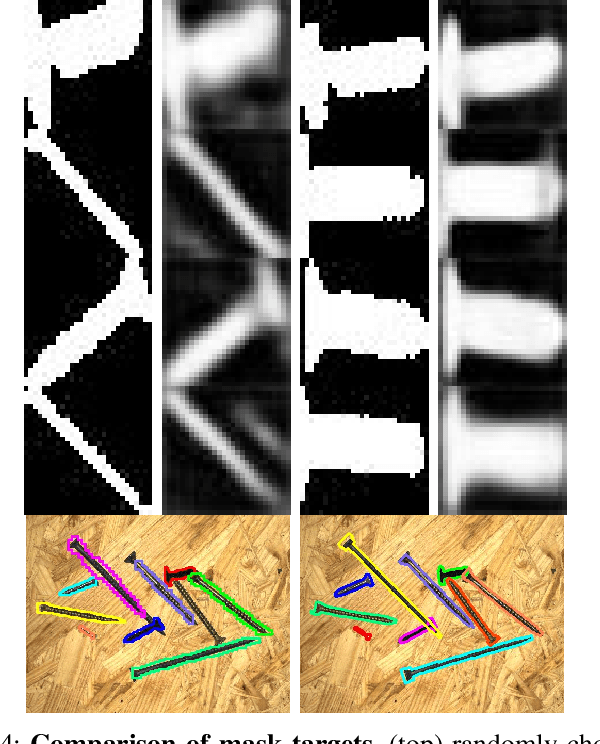
We introduce the Densely Segmented Supermarket (D2S) dataset, a novel benchmark for instance-aware semantic segmentation in an industrial domain. It contains 21,000 high-resolution images with pixel-wise labels of all object instances. The objects comprise groceries and everyday products from 60 categories. The benchmark is designed such that it resembles the real-world setting of an automatic checkout, inventory, or warehouse system. The training images only contain objects of a single class on a homogeneous background, while the validation and test sets are much more complex and diverse. To further benchmark the robustness of instance segmentation methods, the scenes are acquired with different lightings, rotations, and backgrounds. We ensure that there are no ambiguities in the labels and that every instance is labeled comprehensively. The annotations are pixel-precise and allow using crops of single instances for articial data augmentation. The dataset covers several challenges highly relevant in the field, such as a limited amount of training data and a high diversity in the test and validation sets. The evaluation of state-of-the-art object detection and instance segmentation methods on D2S reveals significant room for improvement.
Learning to See the Invisible: End-to-End Trainable Amodal Instance Segmentation
Apr 24, 2018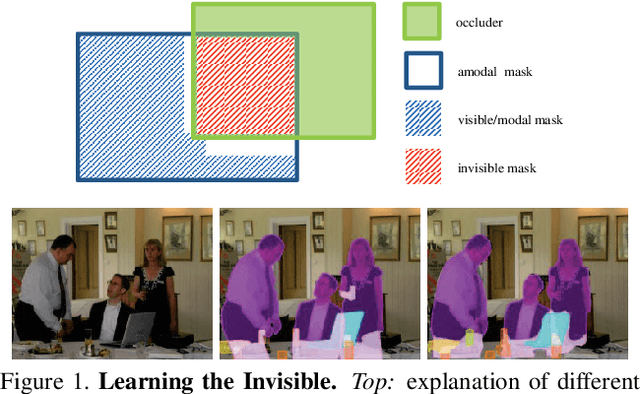
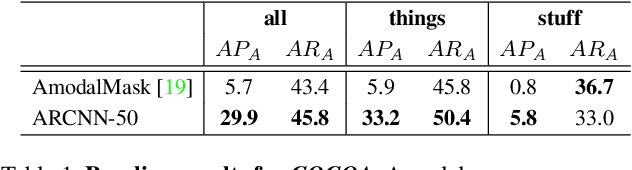
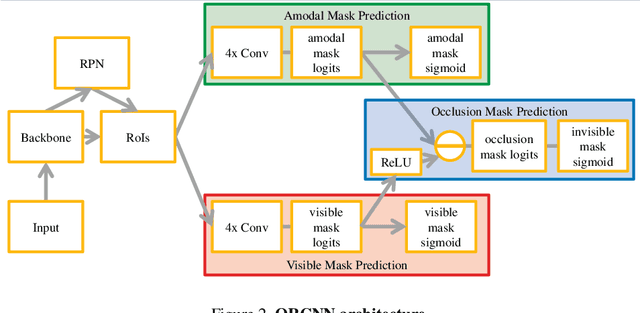
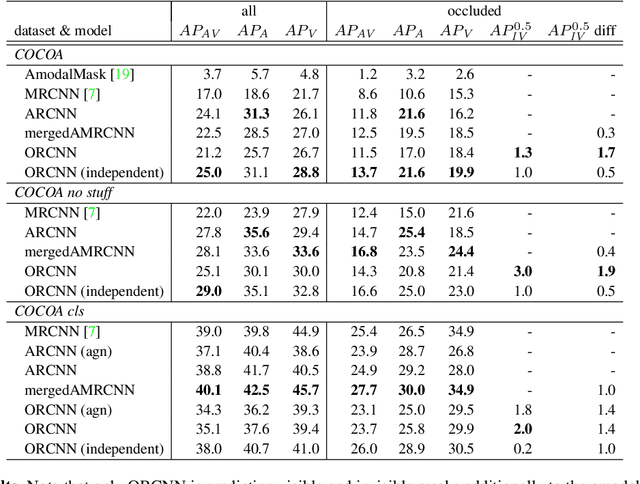
Semantic amodal segmentation is a recently proposed extension to instance-aware segmentation that includes the prediction of the invisible region of each object instance. We present the first all-in-one end-to-end trainable model for semantic amodal segmentation that predicts the amodal instance masks as well as their visible and invisible part in a single forward pass. In a detailed analysis, we provide experiments to show which architecture choices are beneficial for an all-in-one amodal segmentation model. On the COCO amodal dataset, our model outperforms the current baseline for amodal segmentation by a large margin. To further evaluate our model, we provide two new datasets with ground truth for semantic amodal segmentation, D2S amodal and COCOA cls. For both datasets, our model provides a strong baseline performance. Using special data augmentation techniques, we show that amodal segmentation on D2S amodal is possible with reasonable performance, even without providing amodal training data.