 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShift Variance in Scene Text Detection
Aug 19, 2022


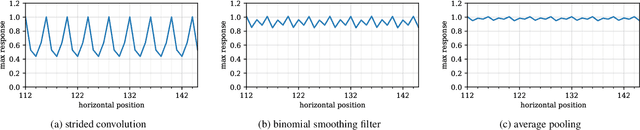
Theory of convolutional neural networks suggests the property of shift equivariance, i.e., that a shifted input causes an equally shifted output. In practice, however, this is not always the case. This poses a great problem for scene text detection for which a consistent spatial response is crucial, irrespective of the position of the text in the scene. Using a simple synthetic experiment, we demonstrate the inherent shift variance of a state-of-the-art fully convolutional text detector. Furthermore, using the same experimental setting, we show how small architectural changes can lead to an improved shift equivariance and less variation of the detector output. We validate the synthetic results using a real-world training schedule on the text detection network. To quantify the amount of shift variability, we propose a metric based on well-established text detection benchmarks. While the proposed architectural changes are not able to fully recover shift equivariance, adding smoothing filters can substantially improve shift consistency on common text datasets. Considering the potentially large impact of small shifts, we propose to extend the commonly used text detection metrics by the metric described in this work, in order to be able to quantify the consistency of text detectors.
MVTec D2S: Densely Segmented Supermarket Dataset
Jul 25, 2018
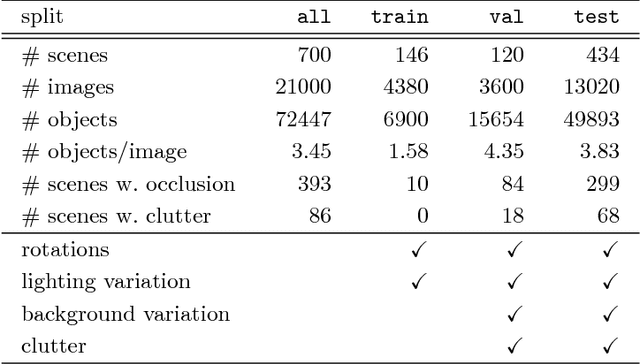

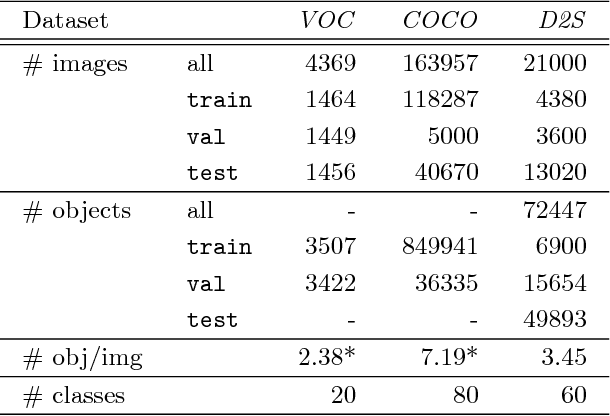
We introduce the Densely Segmented Supermarket (D2S) dataset, a novel benchmark for instance-aware semantic segmentation in an industrial domain. It contains 21,000 high-resolution images with pixel-wise labels of all object instances. The objects comprise groceries and everyday products from 60 categories. The benchmark is designed such that it resembles the real-world setting of an automatic checkout, inventory, or warehouse system. The training images only contain objects of a single class on a homogeneous background, while the validation and test sets are much more complex and diverse. To further benchmark the robustness of instance segmentation methods, the scenes are acquired with different lightings, rotations, and backgrounds. We ensure that there are no ambiguities in the labels and that every instance is labeled comprehensively. The annotations are pixel-precise and allow using crops of single instances for articial data augmentation. The dataset covers several challenges highly relevant in the field, such as a limited amount of training data and a high diversity in the test and validation sets. The evaluation of state-of-the-art object detection and instance segmentation methods on D2S reveals significant room for improvement.
Learning to See the Invisible: End-to-End Trainable Amodal Instance Segmentation
Apr 24, 2018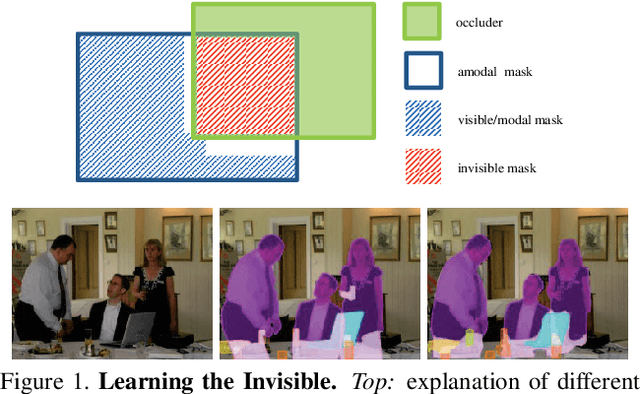
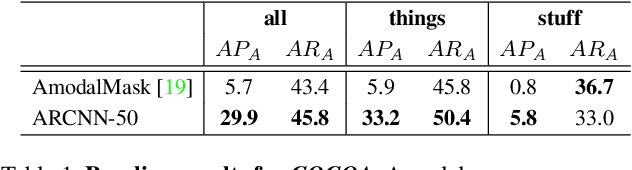
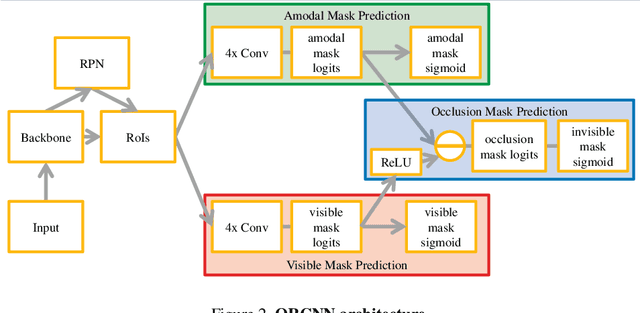
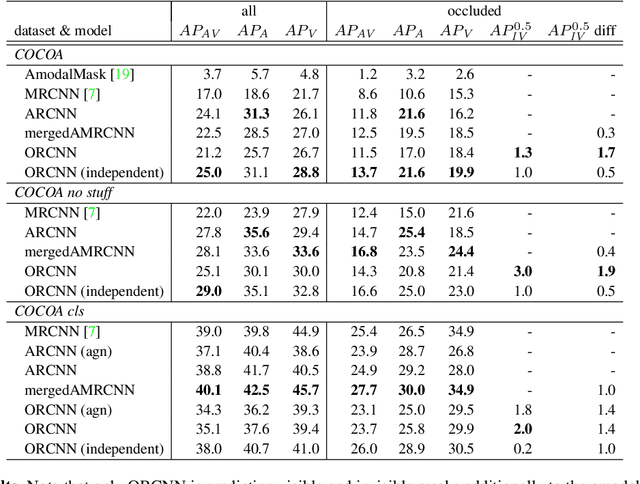
Semantic amodal segmentation is a recently proposed extension to instance-aware segmentation that includes the prediction of the invisible region of each object instance. We present the first all-in-one end-to-end trainable model for semantic amodal segmentation that predicts the amodal instance masks as well as their visible and invisible part in a single forward pass. In a detailed analysis, we provide experiments to show which architecture choices are beneficial for an all-in-one amodal segmentation model. On the COCO amodal dataset, our model outperforms the current baseline for amodal segmentation by a large margin. To further evaluate our model, we provide two new datasets with ground truth for semantic amodal segmentation, D2S amodal and COCOA cls. For both datasets, our model provides a strong baseline performance. Using special data augmentation techniques, we show that amodal segmentation on D2S amodal is possible with reasonable performance, even without providing amodal training data.