 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOriented Boxes for Accurate Instance Segmentation
Nov 27, 2019
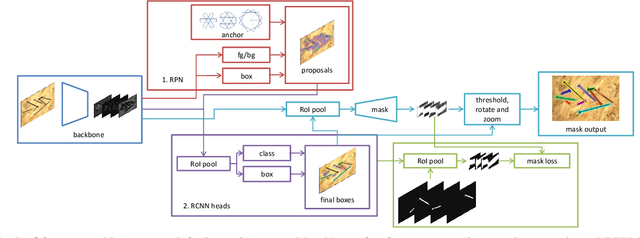

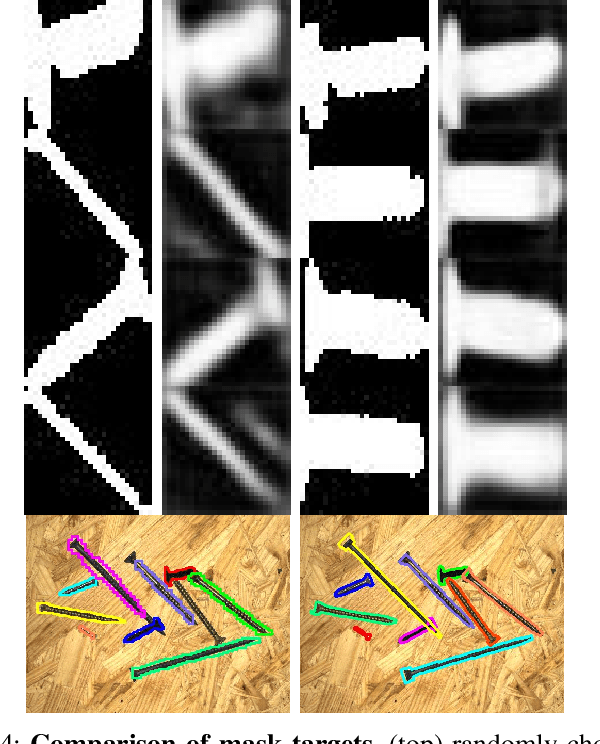
State-of-the-art instance-aware semantic segmentation algorithms use axis-aligned bounding boxes as an intermediate processing step to infer the final instance mask output. This leads to coarse and inaccurate mask proposals due to the following reasons: Axis-aligned boxes have a high background to foreground pixel-ratio, there is a strong variation of mask targets with respect to the underlying box, and neighboring instances frequently reach into the axis-aligned bounding box of the instance mask of interest. In this work, we overcome these problems and propose using oriented boxes as the basis to infer instance masks. We show that oriented instance segmentation leads to very accurate mask predictions, especially when objects are diagonally aligned, touching, or overlapping each other. We evaluate our model on the D2S and Screws datasets and show that we can significantly improve the mask accuracy by 7% and 11% mAP (14.9% and 27.5% relative improvement), respectively.
MVTec D2S: Densely Segmented Supermarket Dataset
Jul 25, 2018
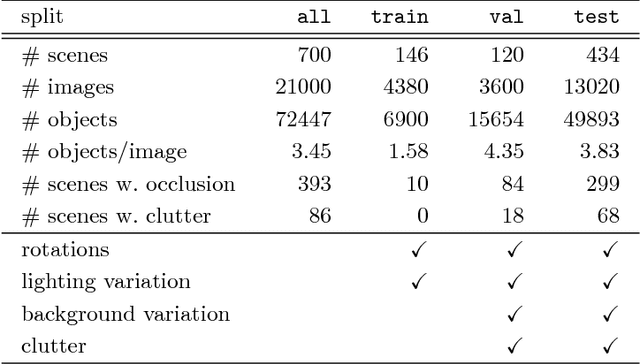

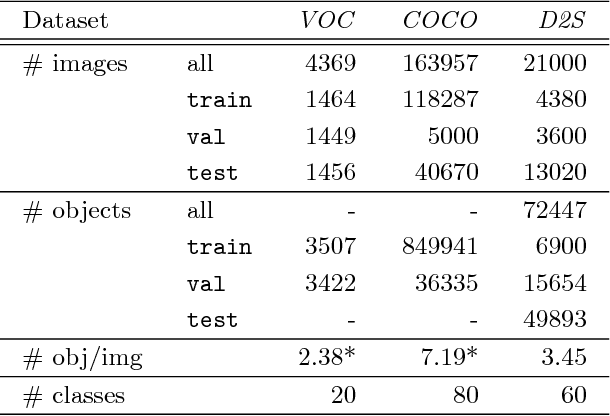
We introduce the Densely Segmented Supermarket (D2S) dataset, a novel benchmark for instance-aware semantic segmentation in an industrial domain. It contains 21,000 high-resolution images with pixel-wise labels of all object instances. The objects comprise groceries and everyday products from 60 categories. The benchmark is designed such that it resembles the real-world setting of an automatic checkout, inventory, or warehouse system. The training images only contain objects of a single class on a homogeneous background, while the validation and test sets are much more complex and diverse. To further benchmark the robustness of instance segmentation methods, the scenes are acquired with different lightings, rotations, and backgrounds. We ensure that there are no ambiguities in the labels and that every instance is labeled comprehensively. The annotations are pixel-precise and allow using crops of single instances for articial data augmentation. The dataset covers several challenges highly relevant in the field, such as a limited amount of training data and a high diversity in the test and validation sets. The evaluation of state-of-the-art object detection and instance segmentation methods on D2S reveals significant room for improvement.
Acquire, Augment, Segment & Enjoy: Weakly Supervised Instance Segmentation of Supermarket Products
Jul 06, 2018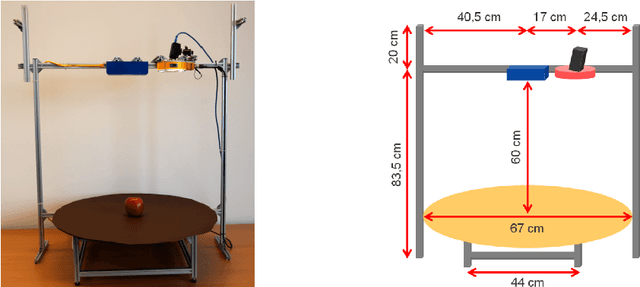
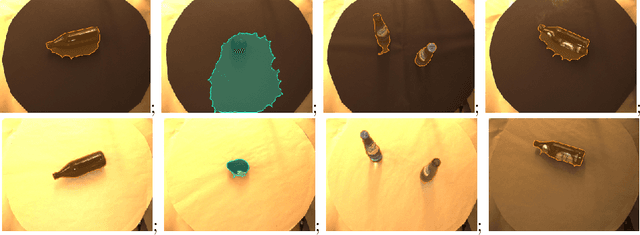

Grocery stores have thousands of products that are usually identified using barcodes with a human in the loop. For automated checkout systems, it is necessary to count and classify the groceries efficiently and robustly. One possibility is to use a deep learning algorithm for instance-aware semantic segmentation. Such methods achieve high accuracies but require a large amount of annotated training data. We propose a system to generate the training annotations in a weakly supervised manner, drastically reducing the labeling effort. We assume that for each training image, only the object class is known. The system automatically segments the corresponding object from the background. The obtained training data is augmented to simulate variations similar to those seen in real-world setups.
Learning to See the Invisible: End-to-End Trainable Amodal Instance Segmentation
Apr 24, 2018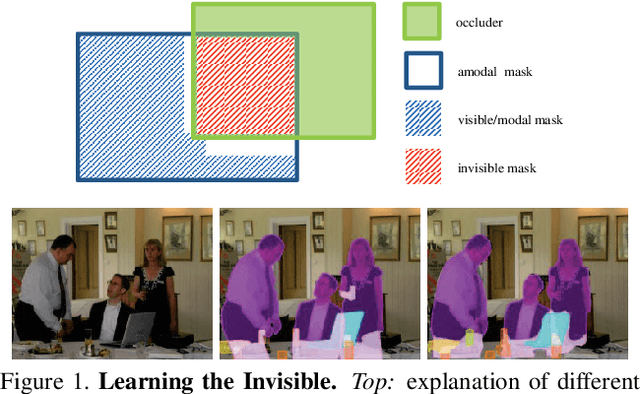
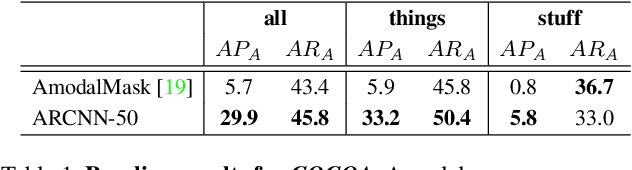
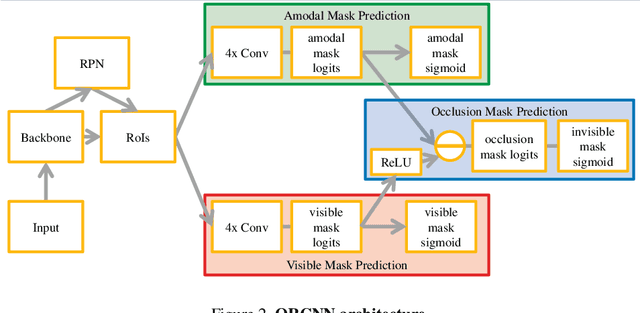
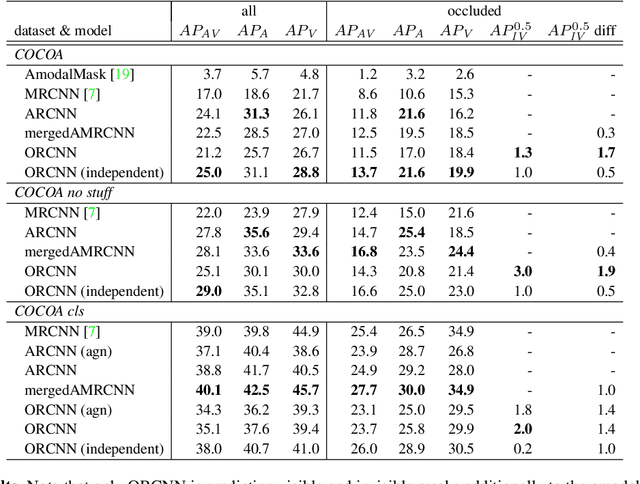
Semantic amodal segmentation is a recently proposed extension to instance-aware segmentation that includes the prediction of the invisible region of each object instance. We present the first all-in-one end-to-end trainable model for semantic amodal segmentation that predicts the amodal instance masks as well as their visible and invisible part in a single forward pass. In a detailed analysis, we provide experiments to show which architecture choices are beneficial for an all-in-one amodal segmentation model. On the COCO amodal dataset, our model outperforms the current baseline for amodal segmentation by a large margin. To further evaluate our model, we provide two new datasets with ground truth for semantic amodal segmentation, D2S amodal and COCOA cls. For both datasets, our model provides a strong baseline performance. Using special data augmentation techniques, we show that amodal segmentation on D2S amodal is possible with reasonable performance, even without providing amodal training data.
Measuring the Accuracy of Object Detectors and Trackers
Apr 24, 2017
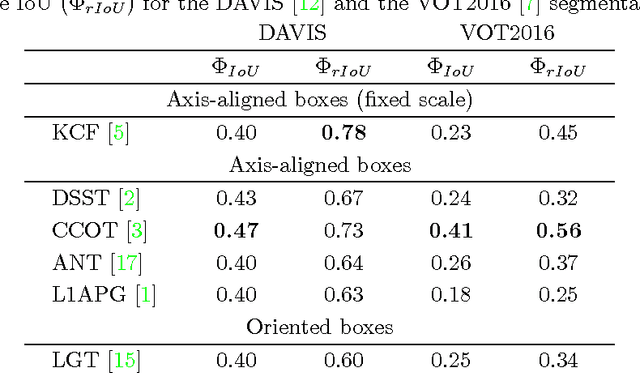
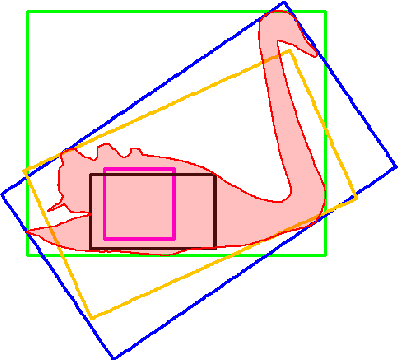
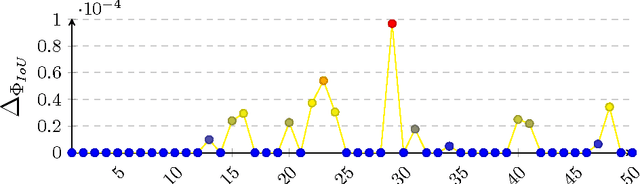
The accuracy of object detectors and trackers is most commonly evaluated by the Intersection over Union (IoU) criterion. To date, most approaches are restricted to axis-aligned or oriented boxes and, as a consequence, many datasets are only labeled with boxes. Nevertheless, axis-aligned or oriented boxes cannot accurately capture an object's shape. To address this, a number of densely segmented datasets has started to emerge in both the object detection and the object tracking communities. However, evaluating the accuracy of object detectors and trackers that are restricted to boxes on densely segmented data is not straightforward. To close this gap, we introduce the relative Intersection over Union (rIoU) accuracy measure. The measure normalizes the IoU with the optimal box for the segmentation to generate an accuracy measure that ranges between 0 and 1 and allows a more precise measurement of accuracies. Furthermore, it enables an efficient and easy way to understand scenes and the strengths and weaknesses of an object detection or tracking approach. We display how the new measure can be efficiently calculated and present an easy-to-use evaluation framework. The framework is tested on the DAVIS and the VOT2016 segmentations and has been made available to the community.