 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMPMAvatar: Learning 3D Gaussian Avatars with Accurate and Robust Physics-Based Dynamics
Oct 02, 2025While there has been significant progress in the field of 3D avatar creation from visual observations, modeling physically plausible dynamics of humans with loose garments remains a challenging problem. Although a few existing works address this problem by leveraging physical simulation, they suffer from limited accuracy or robustness to novel animation inputs. In this work, we present MPMAvatar, a framework for creating 3D human avatars from multi-view videos that supports highly realistic, robust animation, as well as photorealistic rendering from free viewpoints. For accurate and robust dynamics modeling, our key idea is to use a Material Point Method-based simulator, which we carefully tailor to model garments with complex deformations and contact with the underlying body by incorporating an anisotropic constitutive model and a novel collision handling algorithm. We combine this dynamics modeling scheme with our canonical avatar that can be rendered using 3D Gaussian Splatting with quasi-shadowing, enabling high-fidelity rendering for physically realistic animations. In our experiments, we demonstrate that MPMAvatar significantly outperforms the existing state-of-the-art physics-based avatar in terms of (1) dynamics modeling accuracy, (2) rendering accuracy, and (3) robustness and efficiency. Additionally, we present a novel application in which our avatar generalizes to unseen interactions in a zero-shot manner-which was not achievable with previous learning-based methods due to their limited simulation generalizability. Our project page is at: https://KAISTChangmin.github.io/MPMAvatar/
Cascaded Diffusion Framework for Probabilistic Coarse-to-Fine Hand Pose Estimation
Oct 01, 2025



Deterministic models for 3D hand pose reconstruction, whether single-staged or cascaded, struggle with pose ambiguities caused by self-occlusions and complex hand articulations. Existing cascaded approaches refine predictions in a coarse-to-fine manner but remain deterministic and cannot capture pose uncertainties. Recent probabilistic methods model pose distributions yet are restricted to single-stage estimation, which often fails to produce accurate 3D reconstructions without refinement. To address these limitations, we propose a coarse-to-fine cascaded diffusion framework that combines probabilistic modeling with cascaded refinement. The first stage is a joint diffusion model that samples diverse 3D joint hypotheses, and the second stage is a Mesh Latent Diffusion Model (Mesh LDM) that reconstructs a 3D hand mesh conditioned on a joint sample. By training Mesh LDM with diverse joint hypotheses in a learned latent space, our framework learns distribution-aware joint-mesh relationships and robust hand priors. Furthermore, the cascaded design mitigates the difficulty of directly mapping 2D images to dense 3D poses, enhancing accuracy through sequential refinement. Experiments on FreiHAND and HO3Dv2 demonstrate that our method achieves state-of-the-art performance while effectively modeling pose distributions.
REWIND: Real-Time Egocentric Whole-Body Motion Diffusion with Exemplar-Based Identity Conditioning
Apr 08, 2025We present REWIND (Real-Time Egocentric Whole-Body Motion Diffusion), a one-step diffusion model for real-time, high-fidelity human motion estimation from egocentric image inputs. While an existing method for egocentric whole-body (i.e., body and hands) motion estimation is non-real-time and acausal due to diffusion-based iterative motion refinement to capture correlations between body and hand poses, REWIND operates in a fully causal and real-time manner. To enable real-time inference, we introduce (1) cascaded body-hand denoising diffusion, which effectively models the correlation between egocentric body and hand motions in a fast, feed-forward manner, and (2) diffusion distillation, which enables high-quality motion estimation with a single denoising step. Our denoising diffusion model is based on a modified Transformer architecture, designed to causally model output motions while enhancing generalizability to unseen motion lengths. Additionally, REWIND optionally supports identity-conditioned motion estimation when identity prior is available. To this end, we propose a novel identity conditioning method based on a small set of pose exemplars of the target identity, which further enhances motion estimation quality. Through extensive experiments, we demonstrate that REWIND significantly outperforms the existing baselines both with and without exemplar-based identity conditioning.
Body-Hand Modality Expertized Networks with Cross-attention for Fine-grained Skeleton Action Recognition
Mar 19, 2025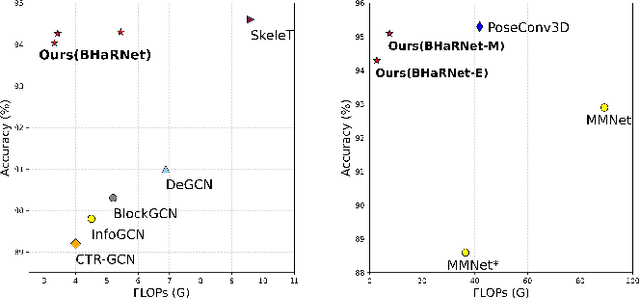
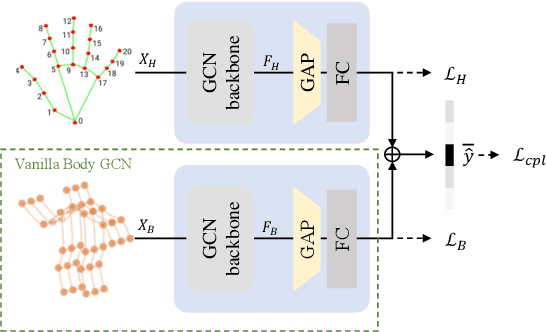
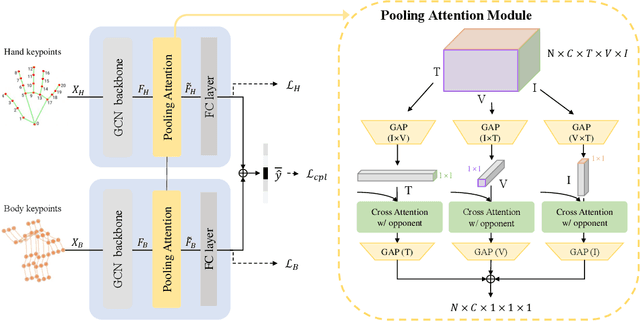
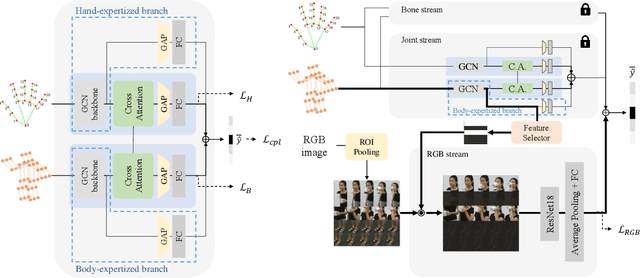
Skeleton-based Human Action Recognition (HAR) is a vital technology in robotics and human-robot interaction. However, most existing methods concentrate primarily on full-body movements and often overlook subtle hand motions that are critical for distinguishing fine-grained actions. Recent work leverages a unified graph representation that combines body, hand, and foot keypoints to capture detailed body dynamics. Yet, these models often blur fine hand details due to the disparity between body and hand action characteristics and the loss of subtle features during the spatial-pooling. In this paper, we propose BHaRNet (Body-Hand action Recognition Network), a novel framework that augments a typical body-expert model with a hand-expert model. Our model jointly trains both streams with an ensemble loss that fosters cooperative specialization, functioning in a manner reminiscent of a Mixture-of-Experts (MoE). Moreover, cross-attention is employed via an expertized branch method and a pooling-attention module to enable feature-level interactions and selectively fuse complementary information. Inspired by MMNet, we also demonstrate the applicability of our approach to multi-modal tasks by leveraging RGB information, where body features guide RGB learning to capture richer contextual cues. Experiments on large-scale benchmarks (NTU RGB+D 60, NTU RGB+D 120, PKU-MMD, and Northwestern-UCLA) demonstrate that BHaRNet achieves SOTA accuracies -- improving from 86.4\% to 93.0\% in hand-intensive actions -- while maintaining fewer GFLOPs and parameters than the relevant unified methods.
MGHanD: Multi-modal Guidance for authentic Hand Diffusion
Mar 11, 2025

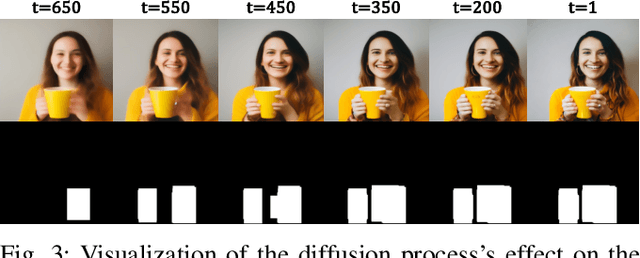

Diffusion-based methods have achieved significant successes in T2I generation, providing realistic images from text prompts. Despite their capabilities, these models face persistent challenges in generating realistic human hands, often producing images with incorrect finger counts and structurally deformed hands. MGHanD addresses this challenge by applying multi-modal guidance during the inference process. For visual guidance, we employ a discriminator trained on a dataset comprising paired real and generated images with captions, derived from various hand-in-the-wild datasets. We also employ textual guidance with LoRA adapter, which learns the direction from `hands' towards more detailed prompts such as `natural hands', and `anatomically correct fingers' at the latent level. A cumulative hand mask which is gradually enlarged in the assigned time step is applied to the added guidance, allowing the hand to be refined while maintaining the rich generative capabilities of the pre-trained model. In the experiments, our method achieves superior hand generation qualities, without any specific conditions or priors. We carry out both quantitative and qualitative evaluations, along with user studies, to showcase the benefits of our approach in producing high-quality hand images.
BP-SGCN: Behavioral Pseudo-Label Informed Sparse Graph Convolution Network for Pedestrian and Heterogeneous Trajectory Prediction
Feb 21, 2025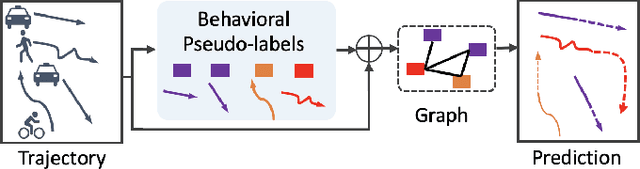
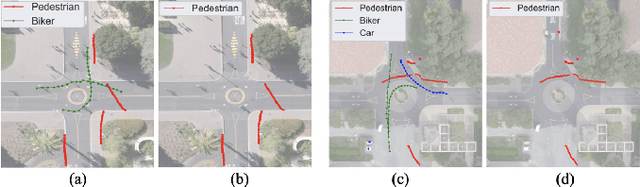
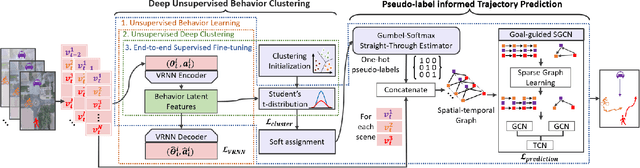

Trajectory prediction allows better decision-making in applications of autonomous vehicles or surveillance by predicting the short-term future movement of traffic agents. It is classified into pedestrian or heterogeneous trajectory prediction. The former exploits the relatively consistent behavior of pedestrians, but is limited in real-world scenarios with heterogeneous traffic agents such as cyclists and vehicles. The latter typically relies on extra class label information to distinguish the heterogeneous agents, but such labels are costly to annotate and cannot be generalized to represent different behaviors within the same class of agents. In this work, we introduce the behavioral pseudo-labels that effectively capture the behavior distributions of pedestrians and heterogeneous agents solely based on their motion features, significantly improving the accuracy of trajectory prediction. To implement the framework, we propose the Behavioral Pseudo-Label Informed Sparse Graph Convolution Network (BP-SGCN) that learns pseudo-labels and informs to a trajectory predictor. For optimization, we propose a cascaded training scheme, in which we first learn the pseudo-labels in an unsupervised manner, and then perform end-to-end fine-tuning on the labels in the direction of increasing the trajectory prediction accuracy. Experiments show that our pseudo-labels effectively model different behavior clusters and improve trajectory prediction. Our proposed BP-SGCN outperforms existing methods using both pedestrian (ETH/UCY, pedestrian-only SDD) and heterogeneous agent datasets (SDD, Argoverse 1).
Prompt Augmentation for Self-supervised Text-guided Image Manipulation
Dec 17, 2024
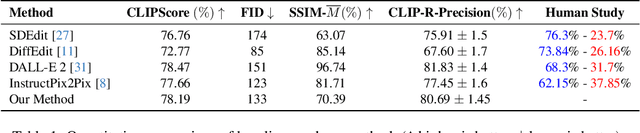
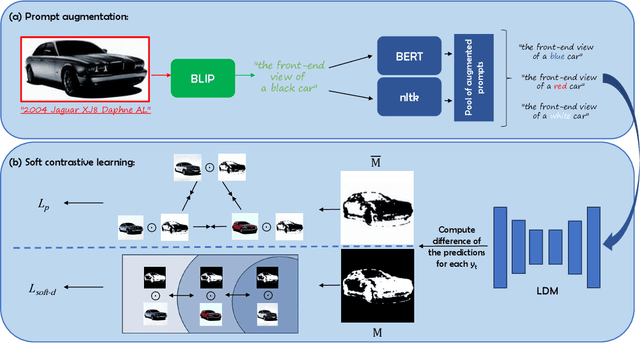
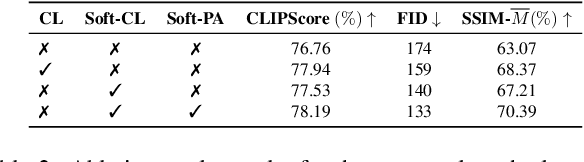
Text-guided image editing finds applications in various creative and practical fields. While recent studies in image generation have advanced the field, they often struggle with the dual challenges of coherent image transformation and context preservation. In response, our work introduces prompt augmentation, a method amplifying a single input prompt into several target prompts, strengthening textual context and enabling localised image editing. Specifically, we use the augmented prompts to delineate the intended manipulation area. We propose a Contrastive Loss tailored to driving effective image editing by displacing edited areas and drawing preserved regions closer. Acknowledging the continuous nature of image manipulations, we further refine our approach by incorporating the similarity concept, creating a Soft Contrastive Loss. The new losses are incorporated to the diffusion model, demonstrating improved or competitive image editing results on public datasets and generated images over state-of-the-art approaches.
TDDSR: Single-Step Diffusion with Two Discriminators for Super Resolution
Oct 10, 2024



Super-resolution methods are increasingly being specialized for both real-world and face-specific tasks. However, many existing approaches rely on simplistic degradation models, which limits their ability to handle complex and unknown degradation patterns effectively. While diffusion-based super-resolution techniques have recently shown impressive results, they are still constrained by the need for numerous inference steps. To address this, we propose TDDSR, an efficient single-step diffusion-based super-resolution method. Our method, distilled from a pre-trained teacher model and based on a diffusion network, performs super-resolution in a single step. It integrates a learnable downsampler to capture diverse degradation patterns and employs two discriminators, one for high-resolution and one for low-resolution images, to enhance the overall performance. Experimental results demonstrate its effectiveness across real-world and face-specific SR tasks, achieving performance comparable to, or even surpassing, another single-step method, previous state-of-the-art models, and the teacher model.
Multi-hypotheses Conditioned Point Cloud Diffusion for 3D Human Reconstruction from Occluded Images
Sep 27, 2024



3D human shape reconstruction under severe occlusion due to human-object or human-human interaction is a challenging problem. Parametric models i.e., SMPL(-X), which are based on the statistics across human shapes, can represent whole human body shapes but are limited to minimally-clothed human shapes. Implicit-function-based methods extract features from the parametric models to employ prior knowledge of human bodies and can capture geometric details such as clothing and hair. However, they often struggle to handle misaligned parametric models and inpaint occluded regions given a single RGB image. In this work, we propose a novel pipeline, MHCDIFF, Multi-hypotheses Conditioned Point Cloud Diffusion, composed of point cloud diffusion conditioned on probabilistic distributions for pixel-aligned detailed 3D human reconstruction under occlusion. Compared to previous implicit-function-based methods, the point cloud diffusion model can capture the global consistent features to generate the occluded regions, and the denoising process corrects the misaligned SMPL meshes. The core of MHCDIFF is extracting local features from multiple hypothesized SMPL(-X) meshes and aggregating the set of features to condition the diffusion model. In the experiments on CAPE and MultiHuman datasets, the proposed method outperforms various SOTA methods based on SMPL, implicit functions, point cloud diffusion, and their combined, under synthetic and real occlusions.
Hand-object reconstruction via interaction-aware graph attention mechanism
Sep 26, 2024



Estimating the poses of both a hand and an object has become an important area of research due to the growing need for advanced vision computing. The primary challenge involves understanding and reconstructing how hands and objects interact, such as contact and physical plausibility. Existing approaches often adopt a graph neural network to incorporate spatial information of hand and object meshes. However, these approaches have not fully exploited the potential of graphs without modification of edges within and between hand- and object-graphs. We propose a graph-based refinement method that incorporates an interaction-aware graph-attention mechanism to account for hand-object interactions. Using edges, we establish connections among closely correlated nodes, both within individual graphs and across different graphs. Experiments demonstrate the effectiveness of our proposed method with notable improvements in the realm of physical plausibility.