 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDense Hand-Object(HO) GraspNet with Full Grasping Taxonomy and Dynamics
Sep 06, 2024
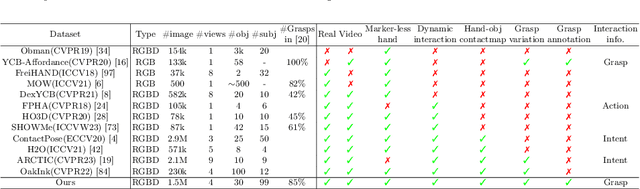
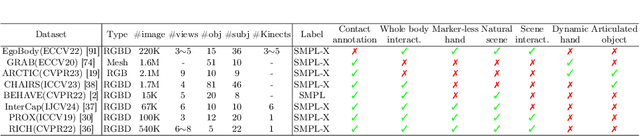
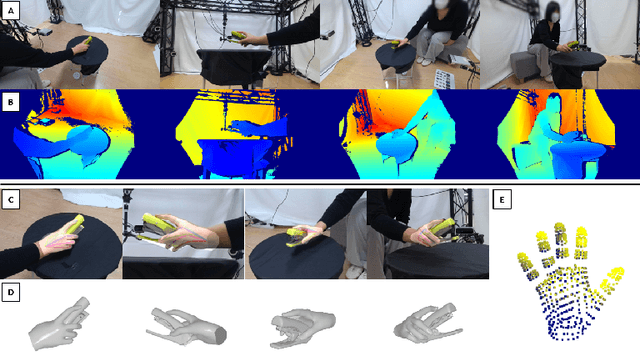
Existing datasets for 3D hand-object interaction are limited either in the data cardinality, data variations in interaction scenarios, or the quality of annotations. In this work, we present a comprehensive new training dataset for hand-object interaction called HOGraspNet. It is the only real dataset that captures full grasp taxonomies, providing grasp annotation and wide intraclass variations. Using grasp taxonomies as atomic actions, their space and time combinatorial can represent complex hand activities around objects. We select 22 rigid objects from the YCB dataset and 8 other compound objects using shape and size taxonomies, ensuring coverage of all hand grasp configurations. The dataset includes diverse hand shapes from 99 participants aged 10 to 74, continuous video frames, and a 1.5M RGB-Depth of sparse frames with annotations. It offers labels for 3D hand and object meshes, 3D keypoints, contact maps, and \emph{grasp labels}. Accurate hand and object 3D meshes are obtained by fitting the hand parametric model (MANO) and the hand implicit function (HALO) to multi-view RGBD frames, with the MoCap system only for objects. Note that HALO fitting does not require any parameter tuning, enabling scalability to the dataset's size with comparable accuracy to MANO. We evaluate HOGraspNet on relevant tasks: grasp classification and 3D hand pose estimation. The result shows performance variations based on grasp type and object class, indicating the potential importance of the interaction space captured by our dataset. The provided data aims at learning universal shape priors or foundation models for 3D hand-object interaction. Our dataset and code are available at https://hograspnet2024.github.io/.
OUR-GAN: One-shot Ultra-high-Resolution Generative Adversarial Networks
Feb 28, 2022


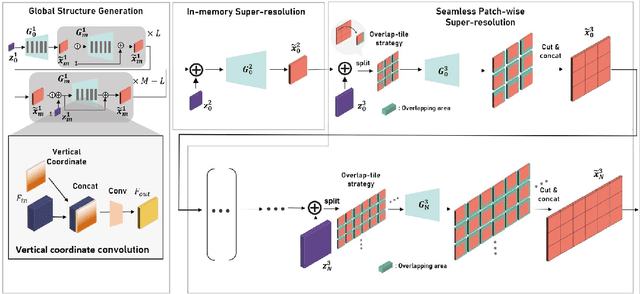
We propose OUR-GAN, the first one-shot ultra-high-resolution (UHR) image synthesis framework that generates non-repetitive images with 4K or higher resolution from a single training image. OUR-GAN generates a visually coherent image at low resolution and then gradually increases the resolution by super-resolution. Since OUR-GAN learns from a real UHR image, it can synthesize large-scale shapes with fine details while maintaining long-range coherence, which is difficult with conventional generative models that generate large images based on the patch distribution learned from relatively small images. OUR-GAN applies seamless subregion-wise super-resolution that synthesizes 4k or higher UHR images with limited memory, preventing discontinuity at the boundary. Additionally, OUR-GAN improves visual coherence maintaining diversity by adding vertical positional embeddings to the feature maps. In experiments on the ST4K and RAISE datasets, OUR-GAN exhibited improved fidelity, visual coherency, and diversity compared with existing methods. The synthesized images are presented at https://anonymous-62348.github.io.