 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOUR-GAN: One-shot Ultra-high-Resolution Generative Adversarial Networks
Feb 28, 2022


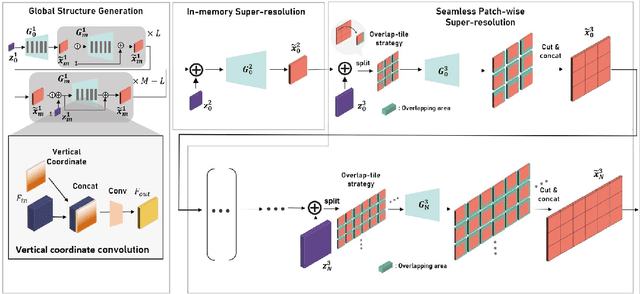
We propose OUR-GAN, the first one-shot ultra-high-resolution (UHR) image synthesis framework that generates non-repetitive images with 4K or higher resolution from a single training image. OUR-GAN generates a visually coherent image at low resolution and then gradually increases the resolution by super-resolution. Since OUR-GAN learns from a real UHR image, it can synthesize large-scale shapes with fine details while maintaining long-range coherence, which is difficult with conventional generative models that generate large images based on the patch distribution learned from relatively small images. OUR-GAN applies seamless subregion-wise super-resolution that synthesizes 4k or higher UHR images with limited memory, preventing discontinuity at the boundary. Additionally, OUR-GAN improves visual coherence maintaining diversity by adding vertical positional embeddings to the feature maps. In experiments on the ST4K and RAISE datasets, OUR-GAN exhibited improved fidelity, visual coherency, and diversity compared with existing methods. The synthesized images are presented at https://anonymous-62348.github.io.
Masked cross self-attention encoding for deep speaker embedding
Jan 28, 2020
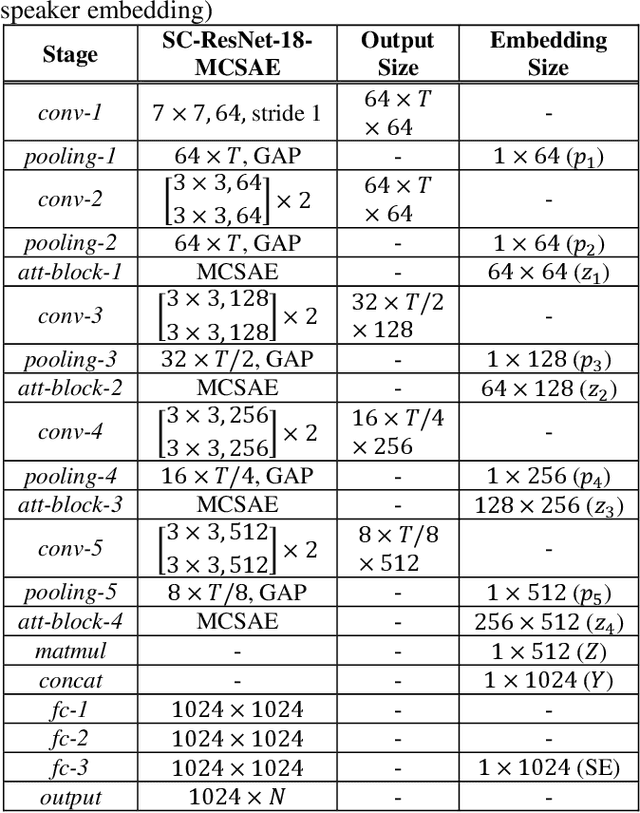
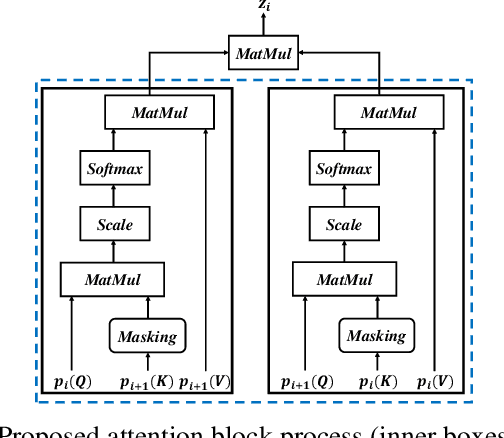
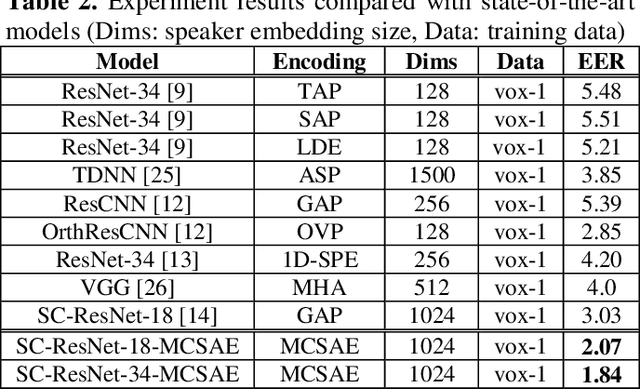
In general, speaker verification tasks require the extraction of speaker embedding from a deep neural network. As speaker embedding may contain additional information such as noise besides speaker information, its variability controlling is needed. Our previous model have used multiple pooling based on shortcut connections to amplify speaker information by deepening the dimension; however, the problem of variability remains. In this paper, we propose a masked cross self-attention encoding (MCSAE) for deep speaker embedding. This method controls the variability of speaker embedding by focusing on each masked output of multiple pooling on each other. The output of the MCSAE is used to construct the deep speaker embedding. Experimental results on VoxCeleb data set demonstrate that the proposed approach improves performance as compared with previous state-of-the-art models.