 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasked cross self-attention encoding for deep speaker embedding
Jan 28, 2020
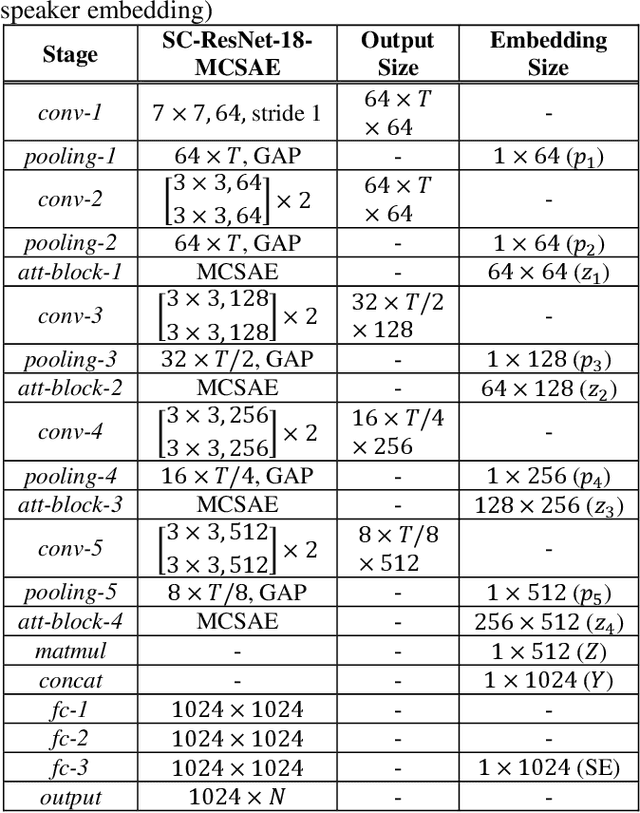
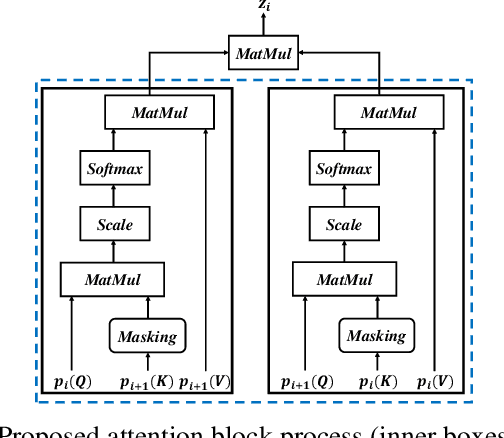
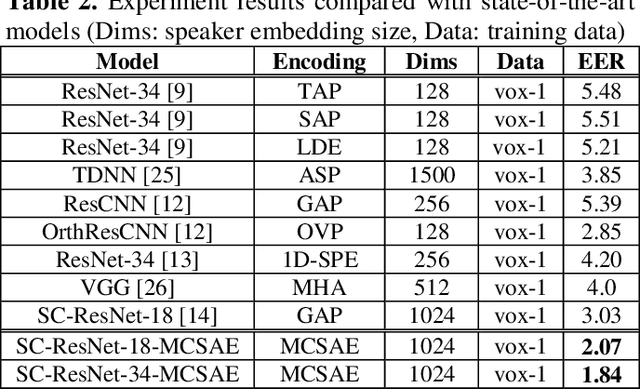
In general, speaker verification tasks require the extraction of speaker embedding from a deep neural network. As speaker embedding may contain additional information such as noise besides speaker information, its variability controlling is needed. Our previous model have used multiple pooling based on shortcut connections to amplify speaker information by deepening the dimension; however, the problem of variability remains. In this paper, we propose a masked cross self-attention encoding (MCSAE) for deep speaker embedding. This method controls the variability of speaker embedding by focusing on each masked output of multiple pooling on each other. The output of the MCSAE is used to construct the deep speaker embedding. Experimental results on VoxCeleb data set demonstrate that the proposed approach improves performance as compared with previous state-of-the-art models.