 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTailoring Self-Supervision for Supervised Learning
Jul 20, 2022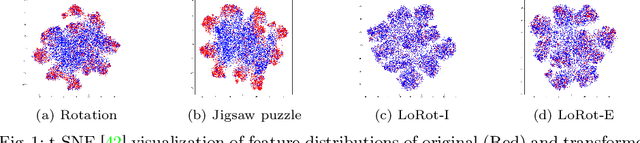

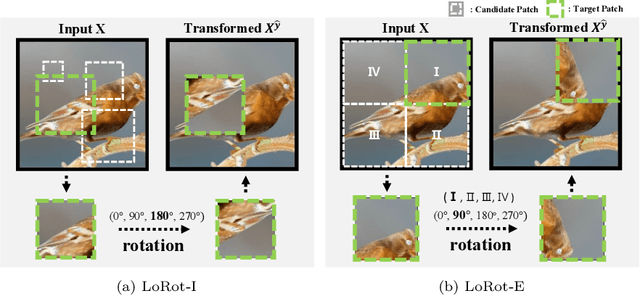

Recently, it is shown that deploying a proper self-supervision is a prospective way to enhance the performance of supervised learning. Yet, the benefits of self-supervision are not fully exploited as previous pretext tasks are specialized for unsupervised representation learning. To this end, we begin by presenting three desirable properties for such auxiliary tasks to assist the supervised objective. First, the tasks need to guide the model to learn rich features. Second, the transformations involved in the self-supervision should not significantly alter the training distribution. Third, the tasks are preferred to be light and generic for high applicability to prior arts. Subsequently, to show how existing pretext tasks can fulfill these and be tailored for supervised learning, we propose a simple auxiliary self-supervision task, predicting localizable rotation (LoRot). Our exhaustive experiments validate the merits of LoRot as a pretext task tailored for supervised learning in terms of robustness and generalization capability. Our code is available at https://github.com/wjun0830/Localizable-Rotation.
Self-Attentive Multi-Layer Aggregation with Feature Recalibration and Normalization for End-to-End Speaker Verification System
Jul 28, 2020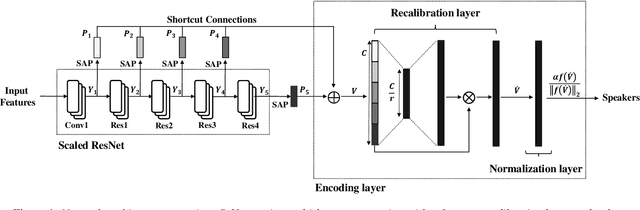
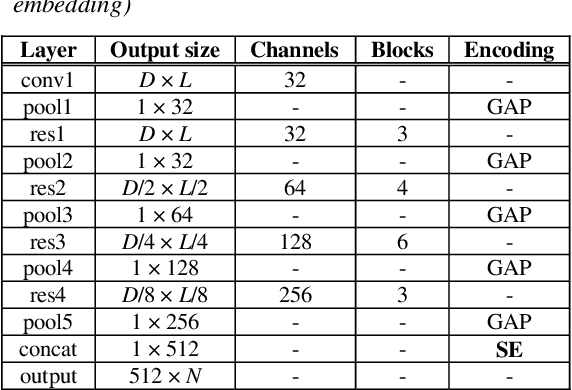
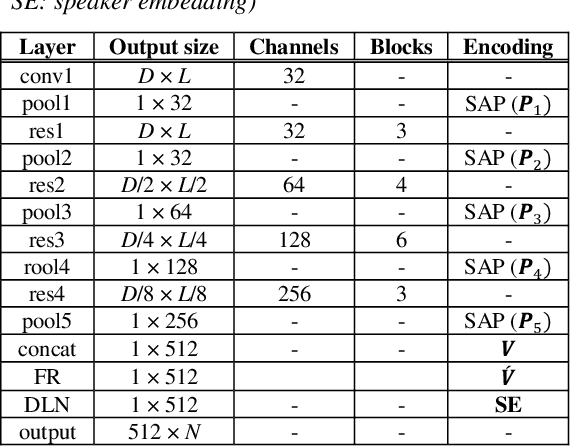

One of the most important parts of an end-to-end speaker verification system is the speaker embedding generation. In our previous paper, we reported that shortcut connections-based multi-layer aggregation improves the representational power of the speaker embedding. However, the number of model parameters is relatively large and the unspecified variations increase in the multi-layer aggregation. Therefore, we propose a self-attentive multi-layer aggregation with feature recalibration and normalization for end-to-end speaker verification system. To reduce the number of model parameters, the ResNet, which scaled channel width and layer depth, is used as a baseline. To control the variability in the training, a self-attention mechanism is applied to perform the multi-layer aggregation with dropout regularizations and batch normalizations. Then, a feature recalibration layer is applied to the aggregated feature using fully-connected layers and nonlinear activation functions. Deep length normalization is also used on a recalibrated feature in the end-to-end training process. Experimental results using the VoxCeleb1 evaluation dataset showed that the performance of the proposed methods was comparable to that of state-of-the-art models (equal error rate of 4.95% and 2.86%, using the VoxCeleb1 and VoxCeleb2 training datasets, respectively).
Masked cross self-attention encoding for deep speaker embedding
Jan 28, 2020
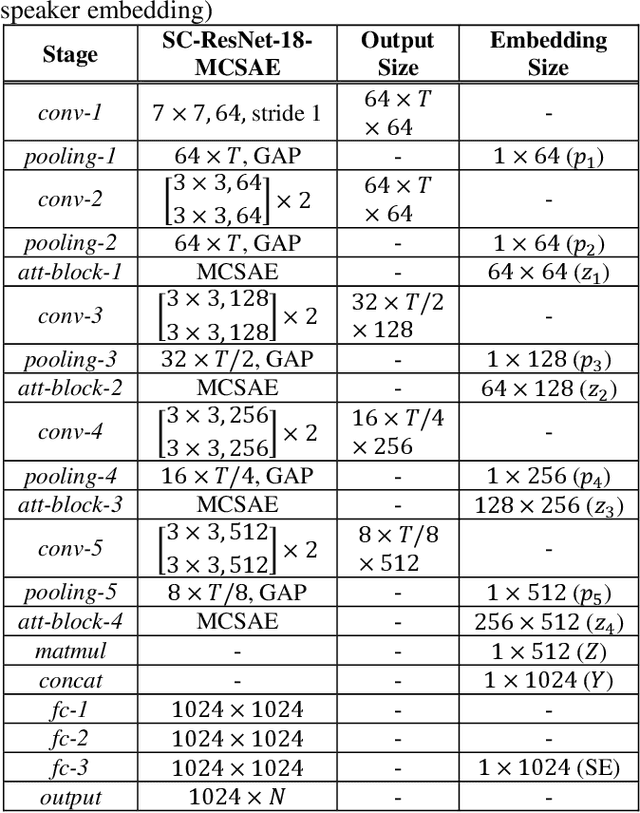
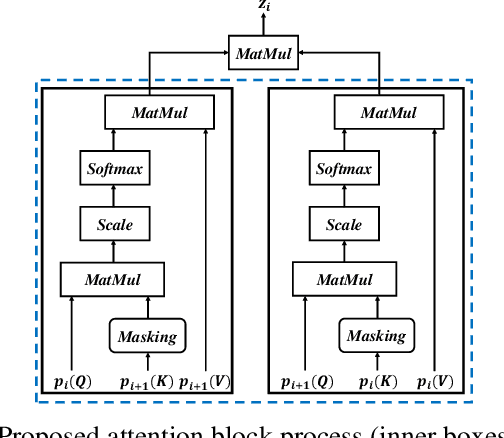
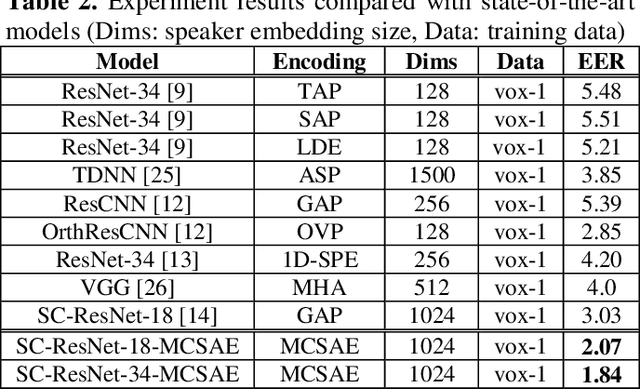
In general, speaker verification tasks require the extraction of speaker embedding from a deep neural network. As speaker embedding may contain additional information such as noise besides speaker information, its variability controlling is needed. Our previous model have used multiple pooling based on shortcut connections to amplify speaker information by deepening the dimension; however, the problem of variability remains. In this paper, we propose a masked cross self-attention encoding (MCSAE) for deep speaker embedding. This method controls the variability of speaker embedding by focusing on each masked output of multiple pooling on each other. The output of the MCSAE is used to construct the deep speaker embedding. Experimental results on VoxCeleb data set demonstrate that the proposed approach improves performance as compared with previous state-of-the-art models.
Integration of TensorFlow based Acoustic Model with Kaldi WFST Decoder
Jun 21, 2019


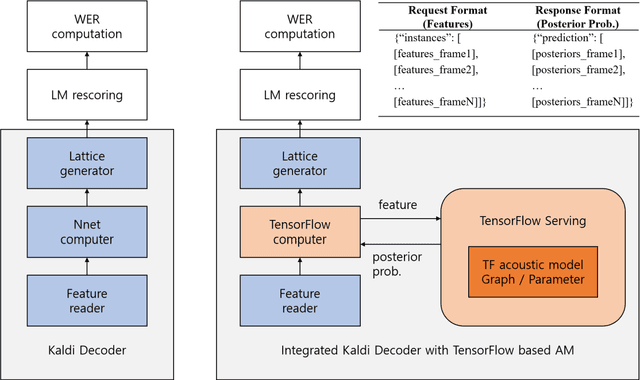
While the Kaldi framework provides state-of-the-art components for speech recognition like feature extraction, deep neural network (DNN)-based acoustic models, and a weighted finite state transducer (WFST)-based decoder, it is difficult to implement a new flexible DNN model. By contrast, a general-purpose deep learning framework, such as TensorFlow, can easily build various types of neural network architectures using a tensor-based computation method, but it is difficult to apply them to WFST-based speech recognition. In this study, a TensorFlow-based acoustic model is integrated with a WFST-based Kaldi decoder to combine the two frameworks. The features and alignments used in Kaldi are converted so they can be trained by the TensorFlow model, and the DNN-based acoustic model is then trained. In the integrated Kaldi decoder, the posterior probabilities are calculated by querying the trained TensorFlow model, and a beam search is performed to generate the lattice. The advantages of the proposed one-pass decoder include the application of various types of neural networks to WFST-based speech recognition and WFST-based online decoding using a TensorFlow-based acoustic model. The TensorFlow based acoustic models trained using the RM, WSJ, and LibriSpeech datasets show the same level of performance as the model trained using the Kaldi framework.
A Fast-Converged Acoustic Modeling for Korean Speech Recognition: A Preliminary Study on Time Delay Neural Network
Jul 11, 2018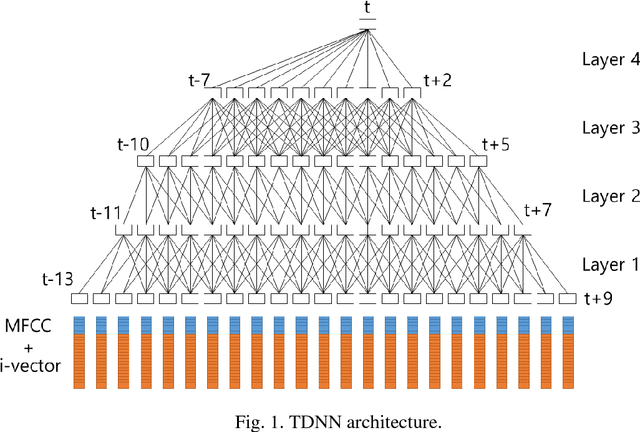

In this paper, a time delay neural network (TDNN) based acoustic model is proposed to implement a fast-converged acoustic modeling for Korean speech recognition. The TDNN has an advantage in fast-convergence where the amount of training data is limited, due to subsampling which excludes duplicated weights. The TDNN showed an absolute improvement of 2.12% in terms of character error rate compared to feed forward neural network (FFNN) based modelling for Korean speech corpora. The proposed model converged 1.67 times faster than a FFNN-based model did.