 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Robustness of Neural Inverse Text Normalization via Data-Augmentation, Semi-Supervised Learning, and Post-Aligning Method
Sep 12, 2023
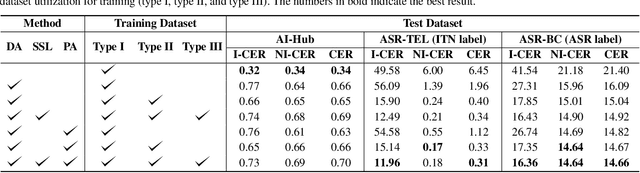
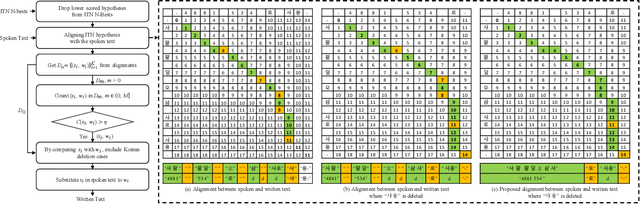
Inverse text normalization (ITN) is crucial for converting spoken-form into written-form, especially in the context of automatic speech recognition (ASR). While most downstream tasks of ASR rely on written-form, ASR systems often output spoken-form, highlighting the necessity for robust ITN in product-level ASR-based applications. Although neural ITN methods have shown promise, they still encounter performance challenges, particularly when dealing with ASR-generated spoken text. These challenges arise from the out-of-domain problem between training data and ASR-generated text. To address this, we propose a direct training approach that utilizes ASR-generated written or spoken text, with pairs augmented through ASR linguistic context emulation and a semi-supervised learning method enhanced by a large language model, respectively. Additionally, we introduce a post-aligning method to manage unpredictable errors, thereby enhancing the reliability of ITN. Our experiments show that our proposed methods remarkably improved ITN performance in various ASR scenarios.
Integration of TensorFlow based Acoustic Model with Kaldi WFST Decoder
Jun 21, 2019


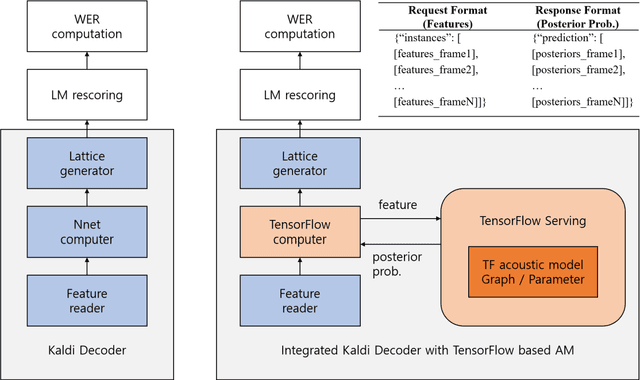
While the Kaldi framework provides state-of-the-art components for speech recognition like feature extraction, deep neural network (DNN)-based acoustic models, and a weighted finite state transducer (WFST)-based decoder, it is difficult to implement a new flexible DNN model. By contrast, a general-purpose deep learning framework, such as TensorFlow, can easily build various types of neural network architectures using a tensor-based computation method, but it is difficult to apply them to WFST-based speech recognition. In this study, a TensorFlow-based acoustic model is integrated with a WFST-based Kaldi decoder to combine the two frameworks. The features and alignments used in Kaldi are converted so they can be trained by the TensorFlow model, and the DNN-based acoustic model is then trained. In the integrated Kaldi decoder, the posterior probabilities are calculated by querying the trained TensorFlow model, and a beam search is performed to generate the lattice. The advantages of the proposed one-pass decoder include the application of various types of neural networks to WFST-based speech recognition and WFST-based online decoding using a TensorFlow-based acoustic model. The TensorFlow based acoustic models trained using the RM, WSJ, and LibriSpeech datasets show the same level of performance as the model trained using the Kaldi framework.
A Fast-Converged Acoustic Modeling for Korean Speech Recognition: A Preliminary Study on Time Delay Neural Network
Jul 11, 2018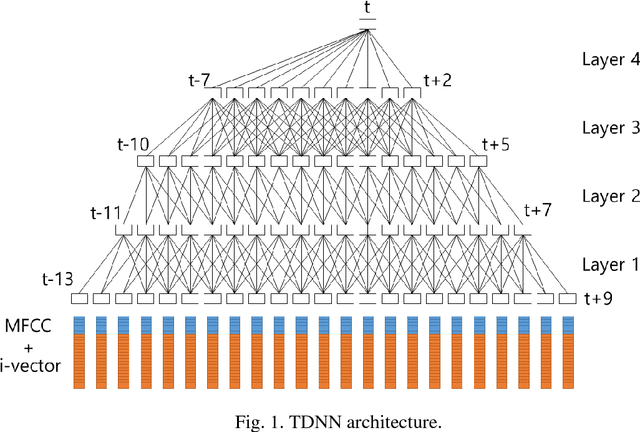

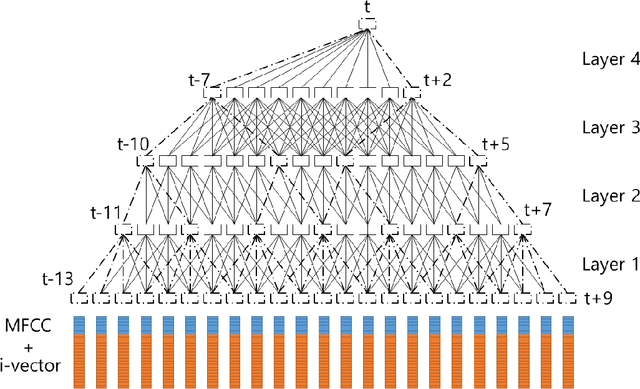
In this paper, a time delay neural network (TDNN) based acoustic model is proposed to implement a fast-converged acoustic modeling for Korean speech recognition. The TDNN has an advantage in fast-convergence where the amount of training data is limited, due to subsampling which excludes duplicated weights. The TDNN showed an absolute improvement of 2.12% in terms of character error rate compared to feed forward neural network (FFNN) based modelling for Korean speech corpora. The proposed model converged 1.67 times faster than a FFNN-based model did.