Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Fast-Converged Acoustic Modeling for Korean Speech Recognition: A Preliminary Study on Time Delay Neural Network
Paper and Code
Jul 11, 2018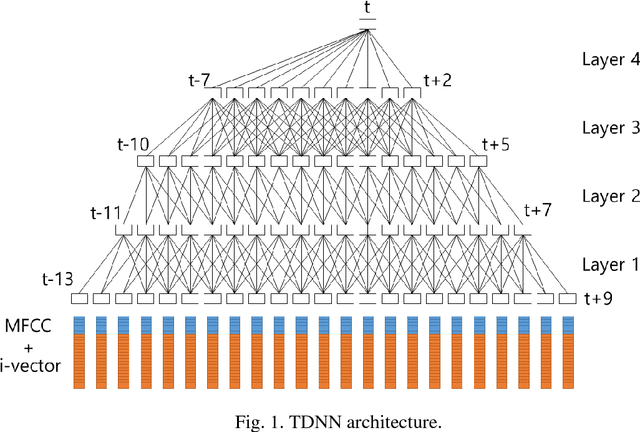

In this paper, a time delay neural network (TDNN) based acoustic model is proposed to implement a fast-converged acoustic modeling for Korean speech recognition. The TDNN has an advantage in fast-convergence where the amount of training data is limited, due to subsampling which excludes duplicated weights. The TDNN showed an absolute improvement of 2.12% in terms of character error rate compared to feed forward neural network (FFNN) based modelling for Korean speech corpora. The proposed model converged 1.67 times faster than a FFNN-based model did.
* 6 pages, 2 figures
View paper on