 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Robustness of Neural Inverse Text Normalization via Data-Augmentation, Semi-Supervised Learning, and Post-Aligning Method
Paper and Code
Sep 12, 2023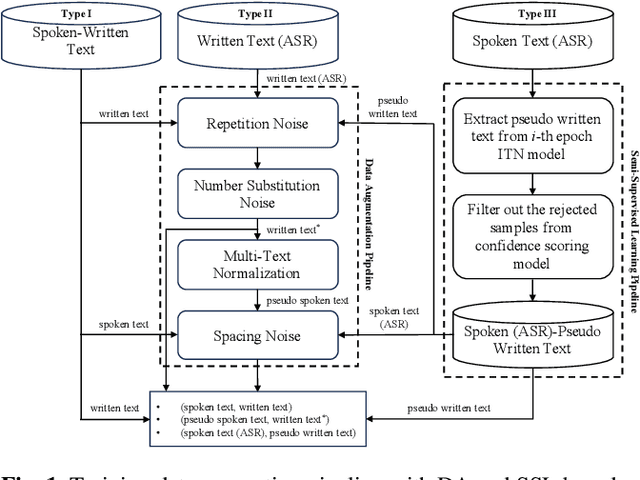
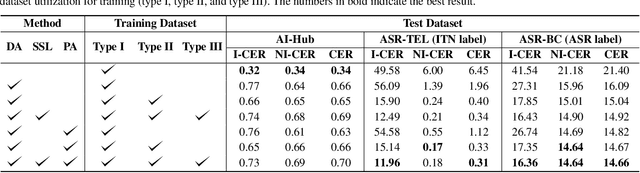
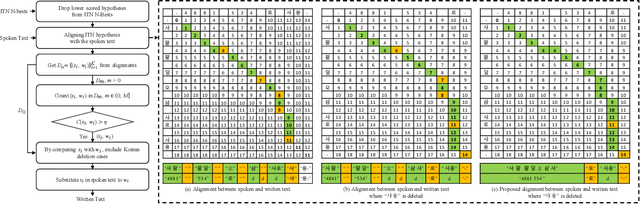
Inverse text normalization (ITN) is crucial for converting spoken-form into written-form, especially in the context of automatic speech recognition (ASR). While most downstream tasks of ASR rely on written-form, ASR systems often output spoken-form, highlighting the necessity for robust ITN in product-level ASR-based applications. Although neural ITN methods have shown promise, they still encounter performance challenges, particularly when dealing with ASR-generated spoken text. These challenges arise from the out-of-domain problem between training data and ASR-generated text. To address this, we propose a direct training approach that utilizes ASR-generated written or spoken text, with pairs augmented through ASR linguistic context emulation and a semi-supervised learning method enhanced by a large language model, respectively. Additionally, we introduce a post-aligning method to manage unpredictable errors, thereby enhancing the reliability of ITN. Our experiments show that our proposed methods remarkably improved ITN performance in various ASR scenarios.