 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelational Self-supervised Distillation with Compact Descriptors for Image Copy Detection
May 29, 2024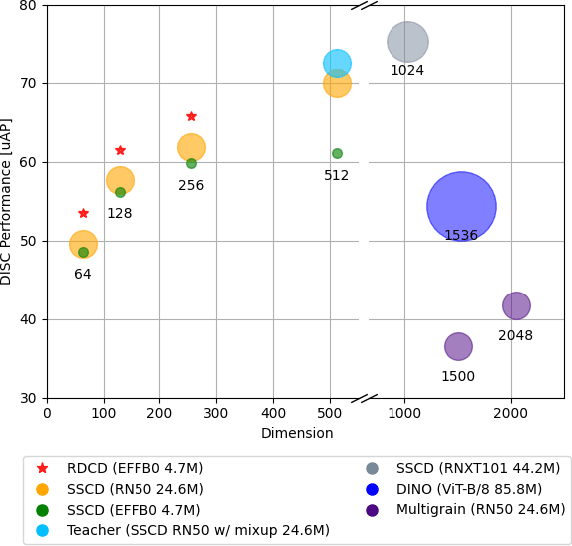
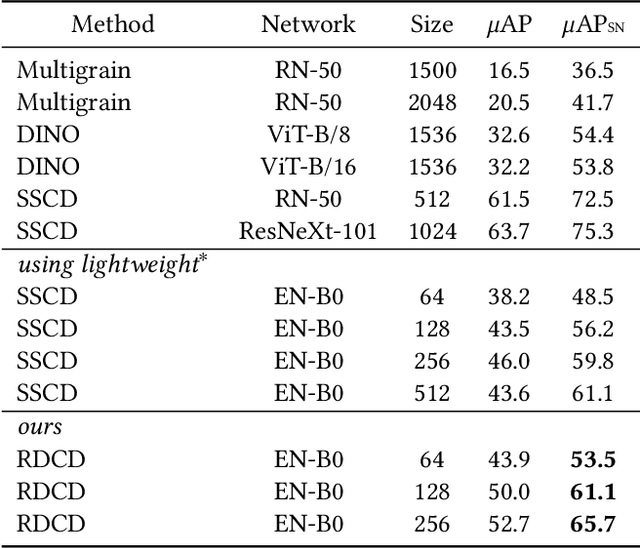
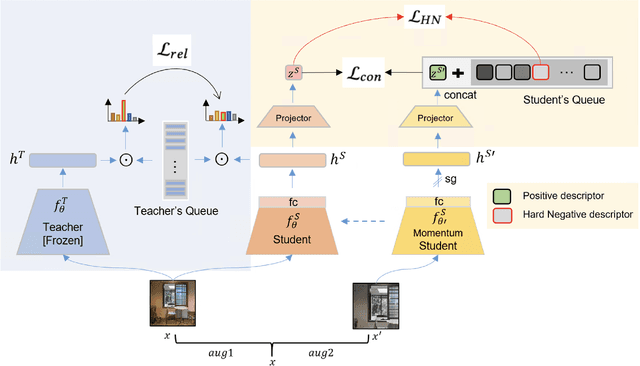

This paper addresses image copy detection, a task in online sharing platforms for copyright protection. While previous approaches have performed exceptionally well, the large size of their networks and descriptors remains a significant disadvantage, complicating their practical application. In this paper, we propose a novel method that achieves a competitive performance by using a lightweight network and compact descriptors. By utilizing relational self-supervised distillation to transfer knowledge from a large network to a small network, we enable the training of lightweight networks with a small descriptor size. Our approach, which we call Relational selfsupervised Distillation with Compact Descriptors (RDCD), introduces relational self-supervised distillation (RSD) for flexible representation in a smaller feature space and applies contrastive learning with a hard negative (HN) loss to prevent dimensional collapse. We demonstrate the effectiveness of our method using the DISC2021, Copydays, and NDEC benchmark datasets, with which our lightweight network with compact descriptors achieves a competitive performance. For the DISC2021 benchmark, ResNet-50/EfficientNet- B0 are used as a teacher and student respectively, the micro average precision improved by 5.0%/4.9%/5.9% for 64/128/256 descriptor sizes compared to the baseline method.
Problem-Solving Guide: Predicting the Algorithm Tags and Difficulty for Competitive Programming Problems
Oct 09, 2023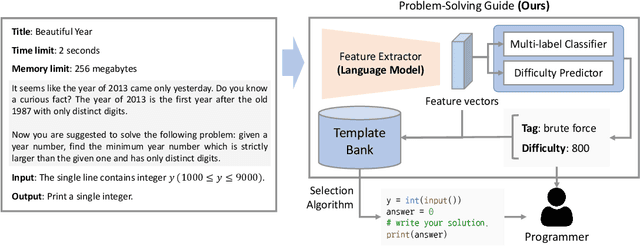
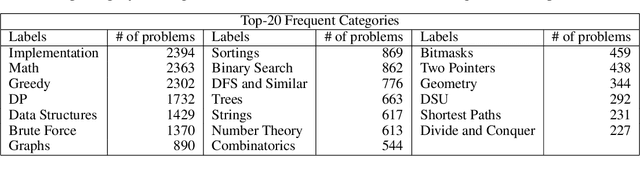
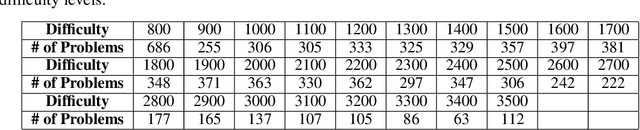
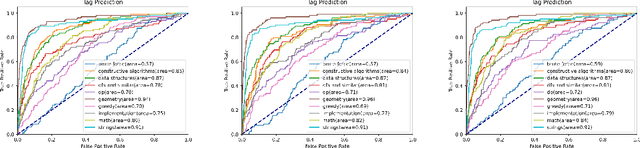
The recent program development industries have required problem-solving abilities for engineers, especially application developers. However, AI-based education systems to help solve computer algorithm problems have not yet attracted attention, while most big tech companies require the ability to solve algorithm problems including Google, Meta, and Amazon. The most useful guide to solving algorithm problems might be guessing the category (tag) of the facing problems. Therefore, our study addresses the task of predicting the algorithm tag as a useful tool for engineers and developers. Moreover, we also consider predicting the difficulty levels of algorithm problems, which can be used as useful guidance to calculate the required time to solve that problem. In this paper, we present a real-world algorithm problem multi-task dataset, AMT, by mainly collecting problem samples from the most famous and large competitive programming website Codeforces. To the best of our knowledge, our proposed dataset is the most large-scale dataset for predicting algorithm tags compared to previous studies. Moreover, our work is the first to address predicting the difficulty levels of algorithm problems. We present a deep learning-based novel method for simultaneously predicting algorithm tags and the difficulty levels of an algorithm problem given. All datasets and source codes are available at https://github.com/sronger/PSG_Predicting_Algorithm_Tags_and_Difficulty.
SoccerNet 2023 Challenges Results
Sep 12, 2023



The SoccerNet 2023 challenges were the third annual video understanding challenges organized by the SoccerNet team. For this third edition, the challenges were composed of seven vision-based tasks split into three main themes. The first theme, broadcast video understanding, is composed of three high-level tasks related to describing events occurring in the video broadcasts: (1) action spotting, focusing on retrieving all timestamps related to global actions in soccer, (2) ball action spotting, focusing on retrieving all timestamps related to the soccer ball change of state, and (3) dense video captioning, focusing on describing the broadcast with natural language and anchored timestamps. The second theme, field understanding, relates to the single task of (4) camera calibration, focusing on retrieving the intrinsic and extrinsic camera parameters from images. The third and last theme, player understanding, is composed of three low-level tasks related to extracting information about the players: (5) re-identification, focusing on retrieving the same players across multiple views, (6) multiple object tracking, focusing on tracking players and the ball through unedited video streams, and (7) jersey number recognition, focusing on recognizing the jersey number of players from tracklets. Compared to the previous editions of the SoccerNet challenges, tasks (2-3-7) are novel, including new annotations and data, task (4) was enhanced with more data and annotations, and task (6) now focuses on end-to-end approaches. More information on the tasks, challenges, and leaderboards are available on https://www.soccer-net.org. Baselines and development kits can be found on https://github.com/SoccerNet.
Improving Robustness of Neural Inverse Text Normalization via Data-Augmentation, Semi-Supervised Learning, and Post-Aligning Method
Sep 12, 2023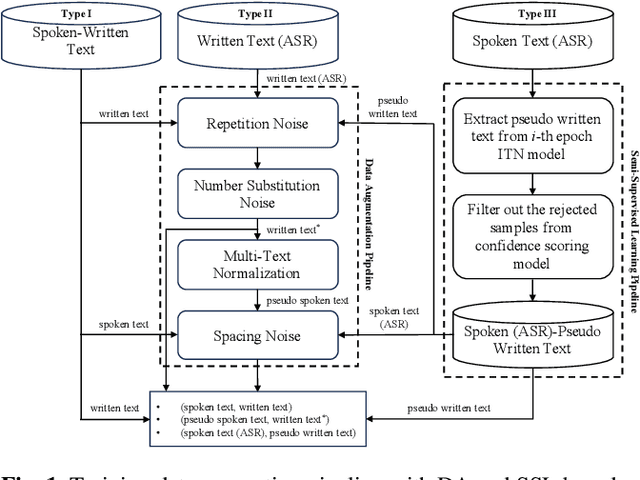
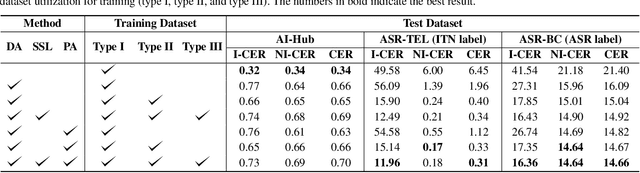
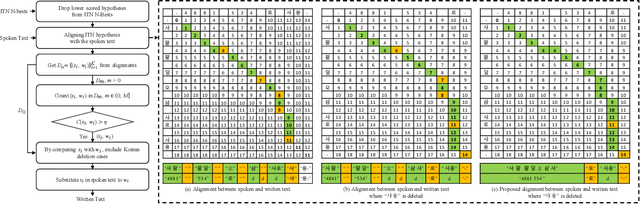
Inverse text normalization (ITN) is crucial for converting spoken-form into written-form, especially in the context of automatic speech recognition (ASR). While most downstream tasks of ASR rely on written-form, ASR systems often output spoken-form, highlighting the necessity for robust ITN in product-level ASR-based applications. Although neural ITN methods have shown promise, they still encounter performance challenges, particularly when dealing with ASR-generated spoken text. These challenges arise from the out-of-domain problem between training data and ASR-generated text. To address this, we propose a direct training approach that utilizes ASR-generated written or spoken text, with pairs augmented through ASR linguistic context emulation and a semi-supervised learning method enhanced by a large language model, respectively. Additionally, we introduce a post-aligning method to manage unpredictable errors, thereby enhancing the reliability of ITN. Our experiments show that our proposed methods remarkably improved ITN performance in various ASR scenarios.
Guiding Users to Where to Give Color Hints for Efficient Interactive Sketch Colorization via Unsupervised Region Prioritization
Oct 25, 2022



Existing deep interactive colorization models have focused on ways to utilize various types of interactions, such as point-wise color hints, scribbles, or natural-language texts, as methods to reflect a user's intent at runtime. However, another approach, which actively informs the user of the most effective regions to give hints for sketch image colorization, has been under-explored. This paper proposes a novel model-guided deep interactive colorization framework that reduces the required amount of user interactions, by prioritizing the regions in a colorization model. Our method, called GuidingPainter, prioritizes these regions where the model most needs a color hint, rather than just relying on the user's manual decision on where to give a color hint. In our extensive experiments, we show that our approach outperforms existing interactive colorization methods in terms of the conventional metrics, such as PSNR and FID, and reduces required amount of interactions.
Phase-Aware Spoof Speech Detection Based on Res2Net with Phase Network
Mar 21, 2022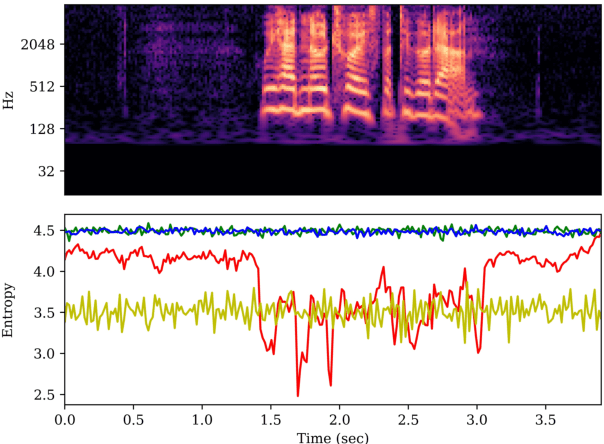
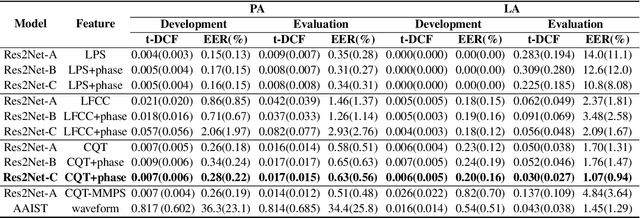
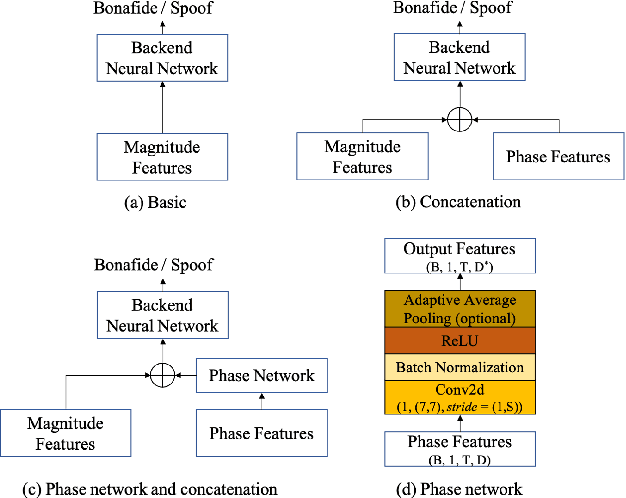

The spoof speech detection (SSD) is the essential countermeasure for automatic speaker verification systems. Although SSD with magnitude features in the frequency domain has shown promising results, the phase information also can be important to capture the artefacts of certain types of spoofing attacks. Thus, both magnitude and phase features must be considered to ensure the generalization ability to diverse types of spoofing attacks. In this paper, we investigate the failure reason of feature-level fusion of the previous works through the entropy analysis from which we found that the randomness difference between magnitude and phase features is large, which can interrupt the feature-level fusion via backend neural network; thus, we propose a phase network to reduce that difference. Our SSD system: phase network equipped Res2Net achieved significant performance improvement, specifically in the spoofing attack for which the phase information is considered to be important. Also, we demonstrate our SSD system in both known- and unknown-kind SSD scenarios for practical applications.
Graph Self-Attention for learning graph representation with Transformer
Jan 30, 2022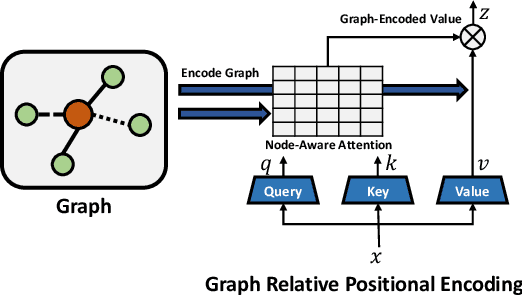

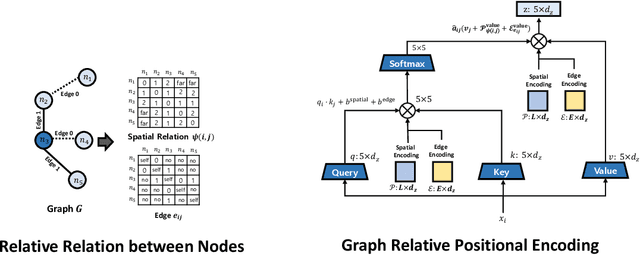
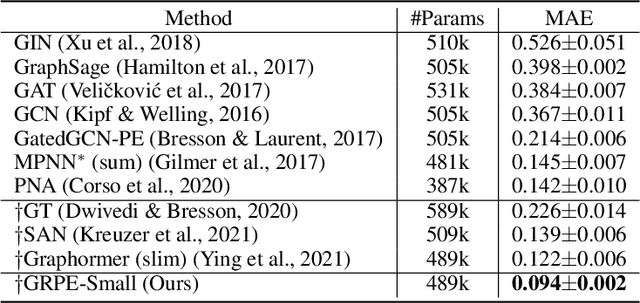
We propose a novel Graph Self-Attention module to enable Transformer models to learn graph representation. We aim to incorporate graph information, on the attention map and hidden representations of Transformer. To this end, we propose context-aware attention which considers the interactions between query, key and graph information. Moreover, we propose graph-embedded value to encode the graph information on the hidden representation. Our extensive experiments and ablation studies validate that our method successfully encodes graph representation on Transformer architecture. Finally, our method achieves state-of-the-art performance on multiple benchmarks of graph representation learning, such as graph classification on images and molecules to graph regression on quantum chemistry.
Generalizing RNN-Transducer to Out-Domain Audio via Sparse Self-Attention Layers
Aug 22, 2021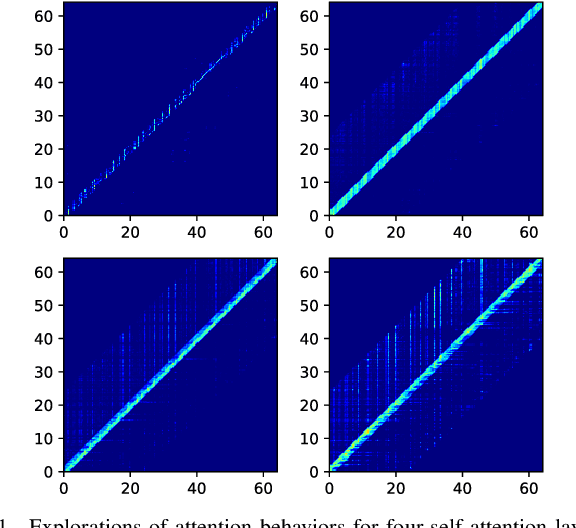
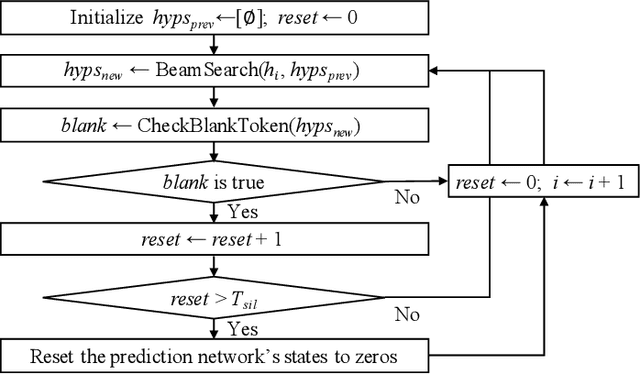
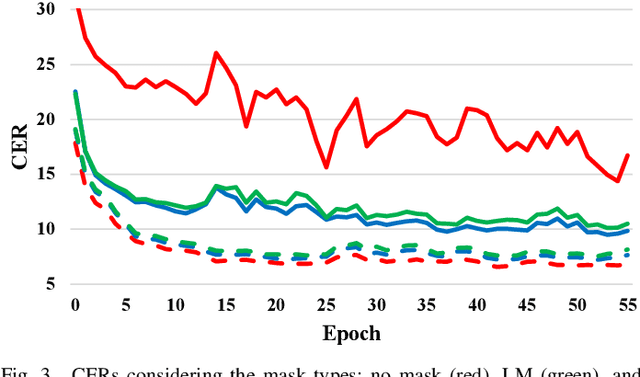

Recurrent neural network transducers (RNN-T) are a promising end-to-end speech recognition framework that transduces input acoustic frames into a character sequence. The state-of-the-art encoder network for RNN-T is the Conformer, which can effectively model the local-global context information via its convolution and self-attention layers. Although Conformer RNN-T has shown outstanding performance (measured by word error rate (WER) in general), most studies have been verified in the setting where the train and test data are drawn from the same domain. The domain mismatch problem for Conformer RNN-T has not been intensively investigated yet, which is an important issue for the product-level speech recognition system. In this study, we identified that fully connected self-attention layers in the Conformer caused high deletion errors, specifically in the long-form out-domain utterances. To address this problem, we introduce sparse self-attention layers for Conformer-based encoder networks, which can exploit local and generalized global information by pruning most of the in-domain fitted global connections. Further, we propose a state reset method for the generalization of the prediction network to cope with long-form utterances. Applying proposed methods to an out-domain test, we obtained 24.6\% and 6.5\% relative character error rate (CER) reduction compared to the fully connected and local self-attention layer-based Conformers, respectively.
UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation
Jun 15, 2021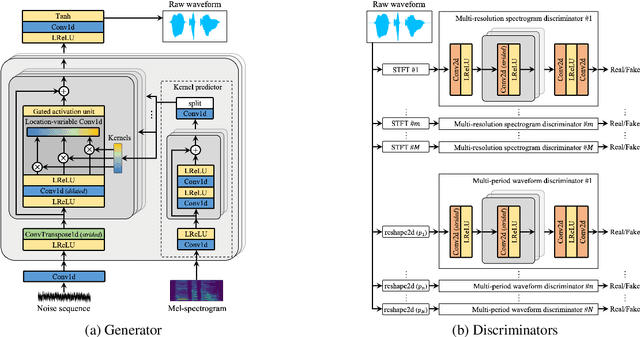
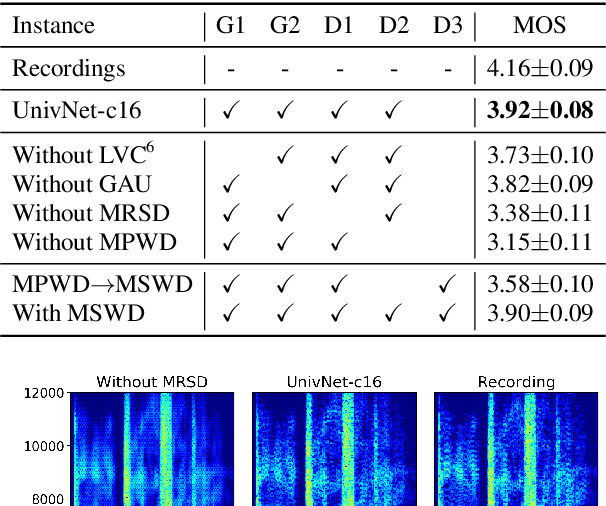
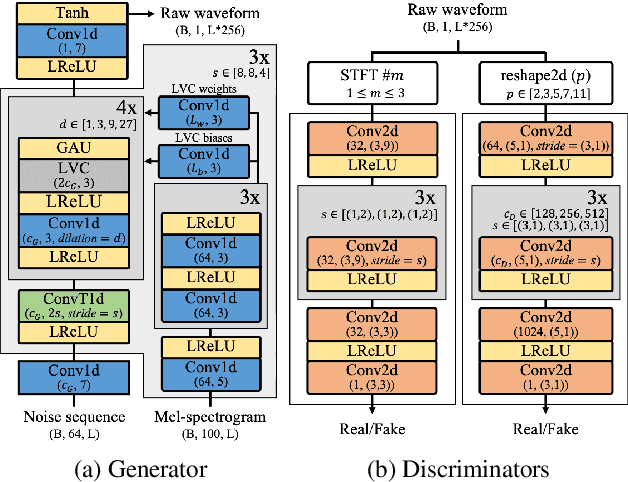
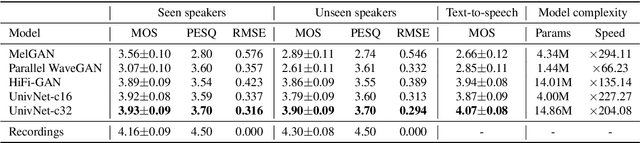
Most neural vocoders employ band-limited mel-spectrograms to generate waveforms. If full-band spectral features are used as the input, the vocoder can be provided with as much acoustic information as possible. However, in some models employing full-band mel-spectrograms, an over-smoothing problem occurs as part of which non-sharp spectrograms are generated. To address this problem, we propose UnivNet, a neural vocoder that synthesizes high-fidelity waveforms in real time. Inspired by works in the field of voice activity detection, we added a multi-resolution spectrogram discriminator that employs multiple linear spectrogram magnitudes computed using various parameter sets. Using full-band mel-spectrograms as input, we expect to generate high-resolution signals by adding a discriminator that employs spectrograms of multiple resolutions as the input. In an evaluation on a dataset containing information on hundreds of speakers, UnivNet obtained the best objective and subjective results among competing models for both seen and unseen speakers. These results, including the best subjective score for text-to-speech, demonstrate the potential for fast adaptation to new speakers without a need for training from scratch.
Accelerating RNN Transducer Inference via One-Step Constrained Beam Search
Feb 10, 2020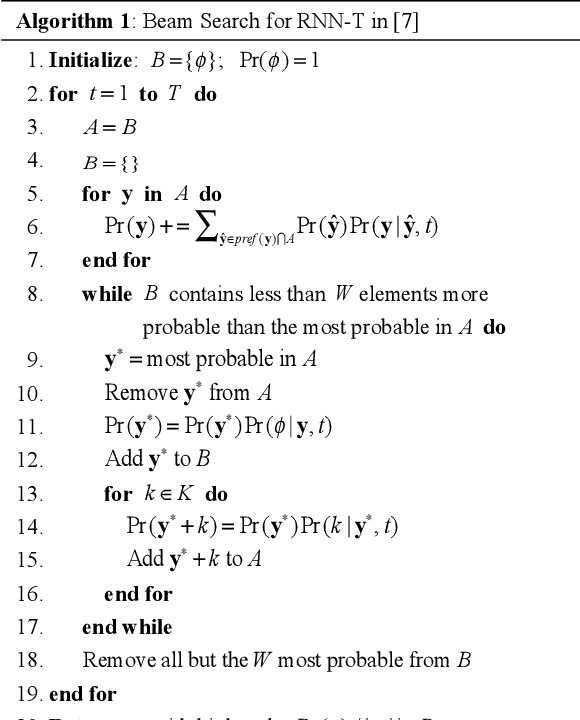
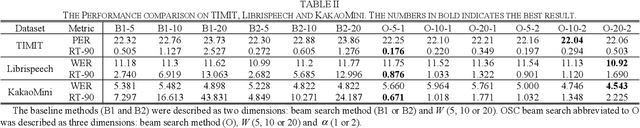
We propose a one-step constrained (OSC) beam search to accelerate recurrent neural network (RNN) transducer (RNN-T) inference. The original RNN-T beam search has a while-loop leading to speed down of the decoding process. The OSC beam search eliminates this while-loop by vectorizing multiple hypotheses. This vectorization is nontrivial as the expansion of the hypotheses within the original RNN-T beam search can be different from each other. However, we found that the hypotheses expanded only once at each decoding step in most cases; thus, we constrained the maximum expansion number to one, thereby allowing vectorization of the hypotheses. For further acceleration, we assign constraints to the prefixes of the hypotheses to prune the redundant search space. In addition, OSC beam search has duplication check among hypotheses during the decoding process as duplication can undesirably shrink the search space. We achieved significant speedup compared with other RNN-T beam search methods with lower phoneme and word error rate.