 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntelli-Z: Toward Intelligible Zero-Shot TTS
Jan 25, 2024Although numerous recent studies have suggested new frameworks for zero-shot TTS using large-scale, real-world data, studies that focus on the intelligibility of zero-shot TTS are relatively scarce. Zero-shot TTS demands additional efforts to ensure clear pronunciation and speech quality due to its inherent requirement of replacing a core parameter (speaker embedding or acoustic prompt) with a new one at the inference stage. In this study, we propose a zero-shot TTS model focused on intelligibility, which we refer to as Intelli-Z. Intelli-Z learns speaker embeddings by using multi-speaker TTS as its teacher and is trained with a cycle-consistency loss to include mismatched text-speech pairs for training. Additionally, it selectively aggregates speaker embeddings along the temporal dimension to minimize the interference of the text content of reference speech at the inference stage. We substantiate the effectiveness of the proposed methods with an ablation study. The Mean Opinion Score (MOS) increases by 9% for unseen speakers when the first two methods are applied, and it further improves by 16% when selective temporal aggregation is applied.
UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation
Jun 15, 2021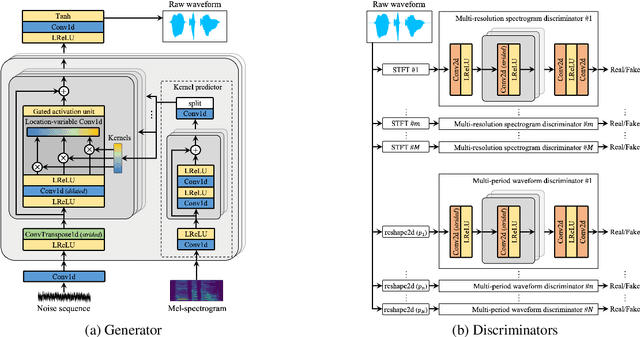
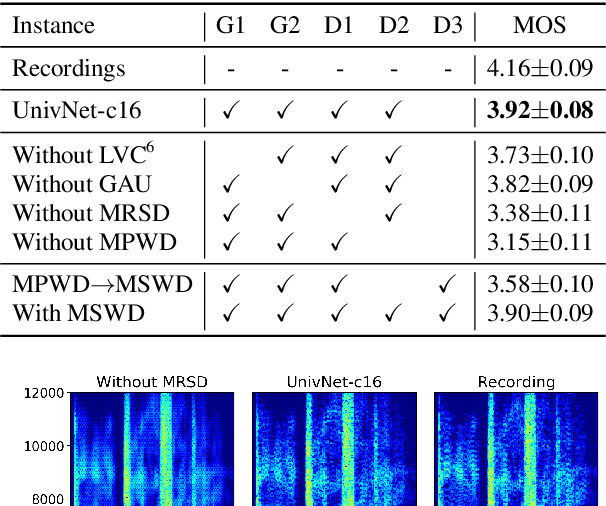
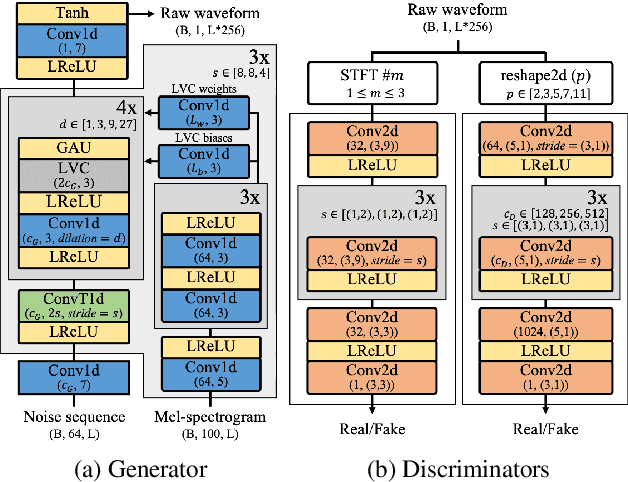
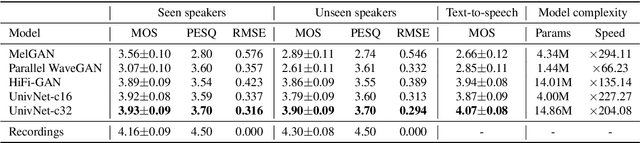
Most neural vocoders employ band-limited mel-spectrograms to generate waveforms. If full-band spectral features are used as the input, the vocoder can be provided with as much acoustic information as possible. However, in some models employing full-band mel-spectrograms, an over-smoothing problem occurs as part of which non-sharp spectrograms are generated. To address this problem, we propose UnivNet, a neural vocoder that synthesizes high-fidelity waveforms in real time. Inspired by works in the field of voice activity detection, we added a multi-resolution spectrogram discriminator that employs multiple linear spectrogram magnitudes computed using various parameter sets. Using full-band mel-spectrograms as input, we expect to generate high-resolution signals by adding a discriminator that employs spectrograms of multiple resolutions as the input. In an evaluation on a dataset containing information on hundreds of speakers, UnivNet obtained the best objective and subjective results among competing models for both seen and unseen speakers. These results, including the best subjective score for text-to-speech, demonstrate the potential for fast adaptation to new speakers without a need for training from scratch.
Universal MelGAN: A Robust Neural Vocoder for High-Fidelity Waveform Generation in Multiple Domains
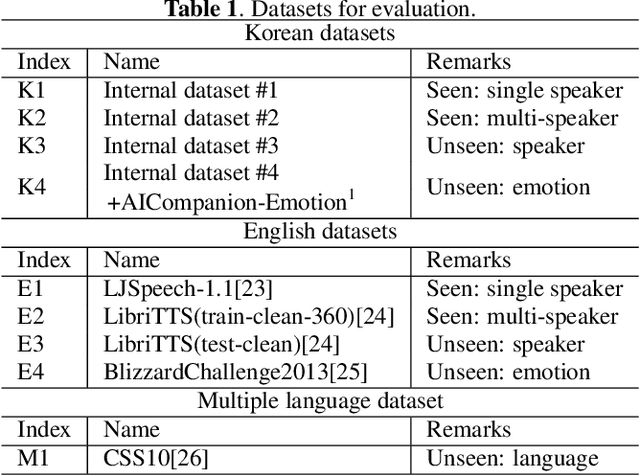
Nov 19, 2020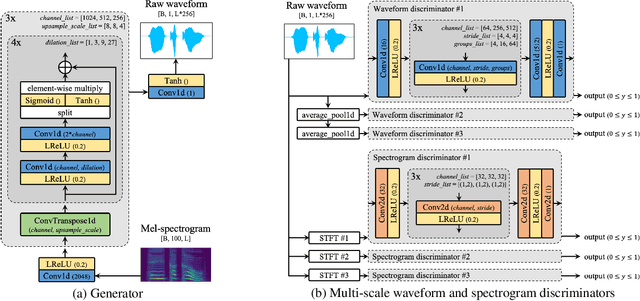
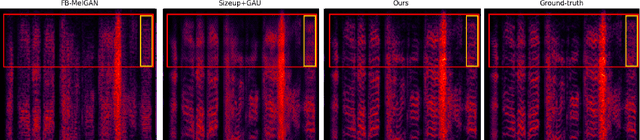
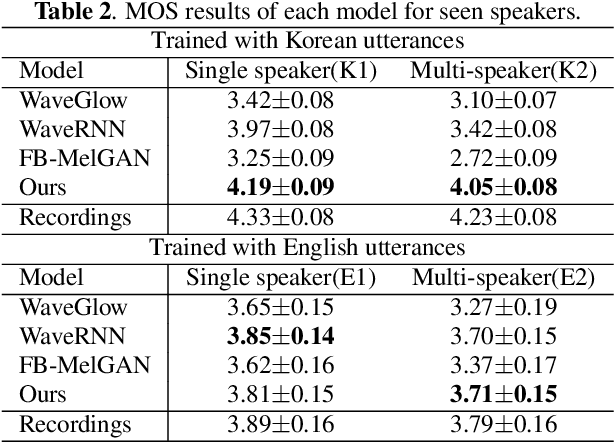
We propose Universal MelGAN, a vocoder that synthesizes high-fidelity speech in multiple domains. To preserve sound quality when the MelGAN-based structure is trained with a dataset of hundreds of speakers, we added multi-resolution spectrogram discriminators to sharpen the spectral resolution of the generated waveforms. This enables the model to generate realistic waveforms of multi-speakers, by alleviating the over-smoothing problem in the high frequency band of the large footprint model. Our structure generates signals close to ground-truth data without reducing the inference speed, by discriminating the waveform and spectrogram during training. The model achieved the best mean opinion score (MOS) in most scenarios using ground-truth mel-spectrogram as an input. Especially, it showed superior performance in unseen domains with regard of speaker, emotion, and language. Moreover, in a multi-speaker text-to-speech scenario using mel-spectrogram generated by a transformer model, it synthesized high-fidelity speech of 4.22 MOS. These results, achieved without external domain information, highlight the potential of the proposed model as a universal vocoder.