 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation
Paper and Code
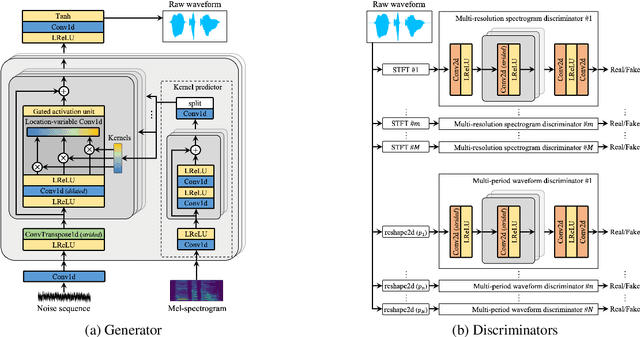
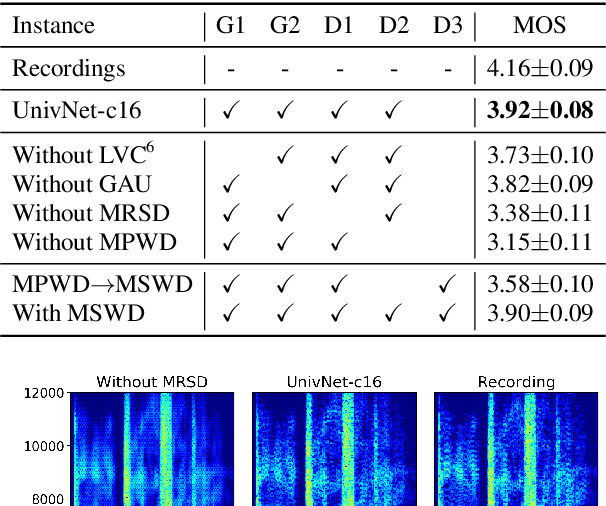
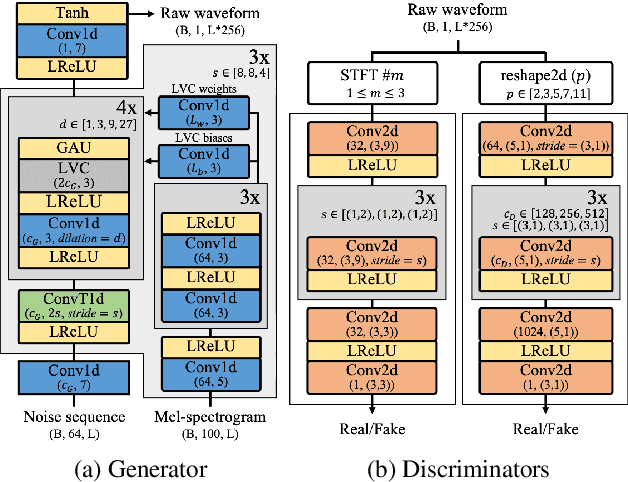
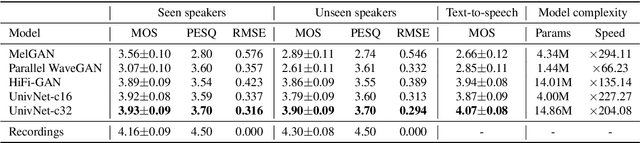
Most neural vocoders employ band-limited mel-spectrograms to generate waveforms. If full-band spectral features are used as the input, the vocoder can be provided with as much acoustic information as possible. However, in some models employing full-band mel-spectrograms, an over-smoothing problem occurs as part of which non-sharp spectrograms are generated. To address this problem, we propose UnivNet, a neural vocoder that synthesizes high-fidelity waveforms in real time. Inspired by works in the field of voice activity detection, we added a multi-resolution spectrogram discriminator that employs multiple linear spectrogram magnitudes computed using various parameter sets. Using full-band mel-spectrograms as input, we expect to generate high-resolution signals by adding a discriminator that employs spectrograms of multiple resolutions as the input. In an evaluation on a dataset containing information on hundreds of speakers, UnivNet obtained the best objective and subjective results among competing models for both seen and unseen speakers. These results, including the best subjective score for text-to-speech, demonstrate the potential for fast adaptation to new speakers without a need for training from scratch.