 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFastFit: Towards Real-Time Iterative Neural Vocoder by Replacing U-Net Encoder With Multiple STFTs
May 18, 2023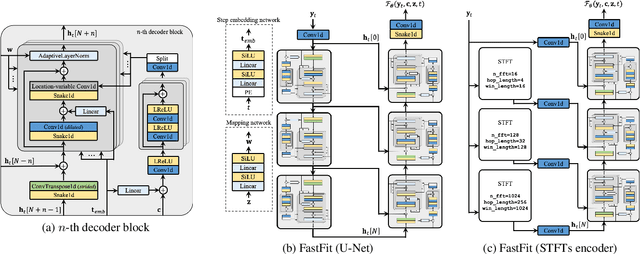


This paper presents FastFit, a novel neural vocoder architecture that replaces the U-Net encoder with multiple short-time Fourier transforms (STFTs) to achieve faster generation rates without sacrificing sample quality. We replaced each encoder block with an STFT, with parameters equal to the temporal resolution of each decoder block, leading to the skip connection. FastFit reduces the number of parameters and the generation time of the model by almost half while maintaining high fidelity. Through objective and subjective evaluations, we demonstrated that the proposed model achieves nearly twice the generation speed of baseline iteration-based vocoders while maintaining high sound quality. We further showed that FastFit produces sound qualities similar to those of other baselines in text-to-speech evaluation scenarios, including multi-speaker and zero-shot text-to-speech.
JETS: Jointly Training FastSpeech2 and HiFi-GAN for End to End Text to Speech
Mar 31, 2022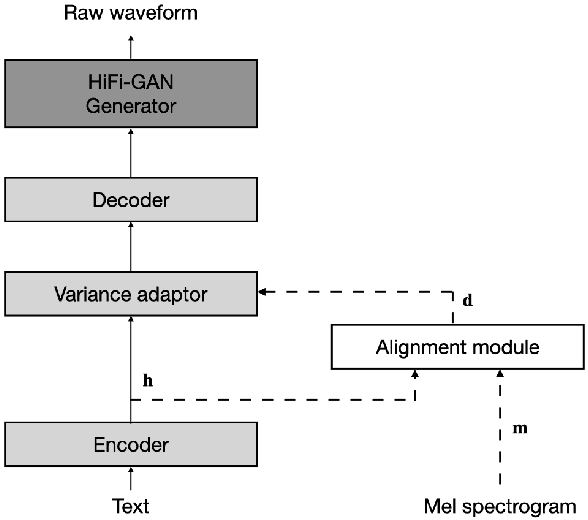
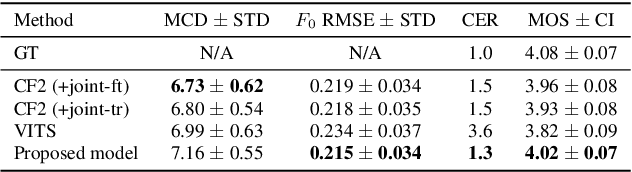
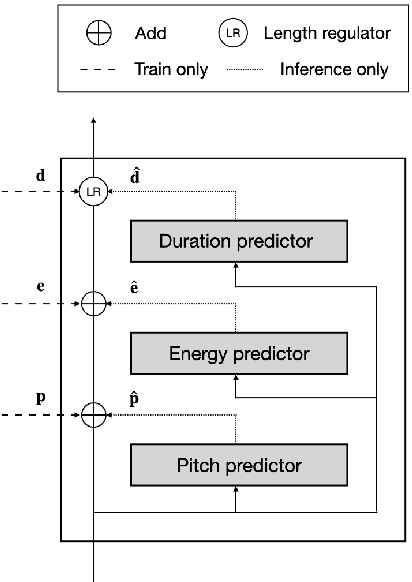
In neural text-to-speech (TTS), two-stage system or a cascade of separately learned models have shown synthesis quality close to human speech. For example, FastSpeech2 transforms an input text to a mel-spectrogram and then HiFi-GAN generates a raw waveform from a mel-spectogram where they are called an acoustic feature generator and a neural vocoder respectively. However, their training pipeline is somewhat cumbersome in that it requires a fine-tuning and an accurate speech-text alignment for optimal performance. In this work, we present end-to-end text-to-speech (E2E-TTS) model which has a simplified training pipeline and outperforms a cascade of separately learned models. Specifically, our proposed model is jointly trained FastSpeech2 and HiFi-GAN with an alignment module. Since there is no acoustic feature mismatch between training and inference, it does not requires fine-tuning. Furthermore, we remove dependency on an external speech-text alignment tool by adopting an alignment learning objective in our joint training framework. Experiments on LJSpeech corpus shows that the proposed model outperforms publicly available, state-of-the-art implementations of ESPNet2-TTS on subjective evaluation (MOS) and some objective evaluations.
UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation
Jun 15, 2021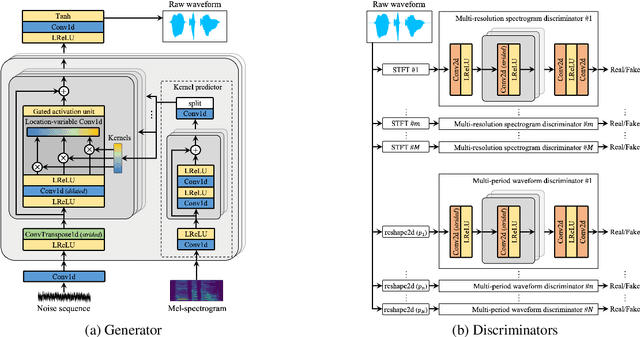
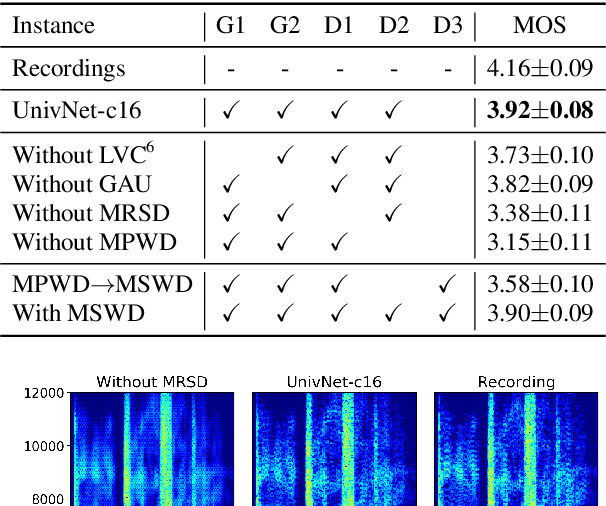
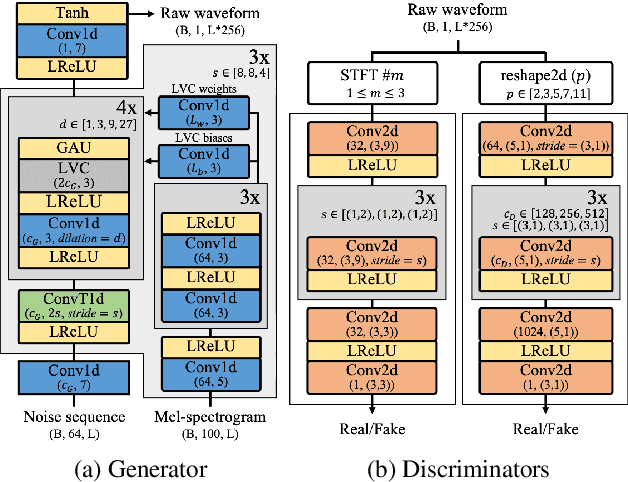
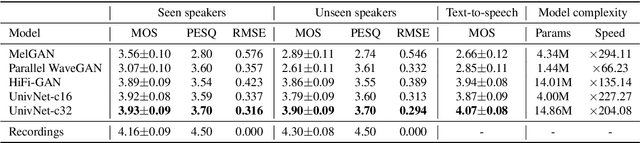
Most neural vocoders employ band-limited mel-spectrograms to generate waveforms. If full-band spectral features are used as the input, the vocoder can be provided with as much acoustic information as possible. However, in some models employing full-band mel-spectrograms, an over-smoothing problem occurs as part of which non-sharp spectrograms are generated. To address this problem, we propose UnivNet, a neural vocoder that synthesizes high-fidelity waveforms in real time. Inspired by works in the field of voice activity detection, we added a multi-resolution spectrogram discriminator that employs multiple linear spectrogram magnitudes computed using various parameter sets. Using full-band mel-spectrograms as input, we expect to generate high-resolution signals by adding a discriminator that employs spectrograms of multiple resolutions as the input. In an evaluation on a dataset containing information on hundreds of speakers, UnivNet obtained the best objective and subjective results among competing models for both seen and unseen speakers. These results, including the best subjective score for text-to-speech, demonstrate the potential for fast adaptation to new speakers without a need for training from scratch.
Universal MelGAN: A Robust Neural Vocoder for High-Fidelity Waveform Generation in Multiple Domains
Nov 19, 2020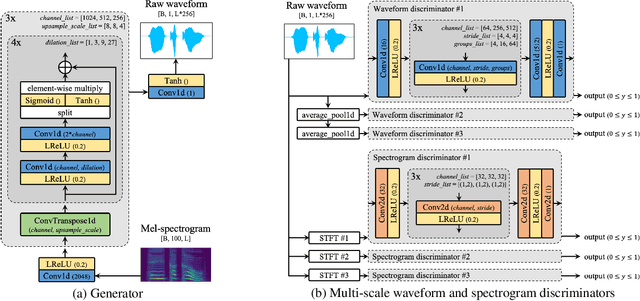
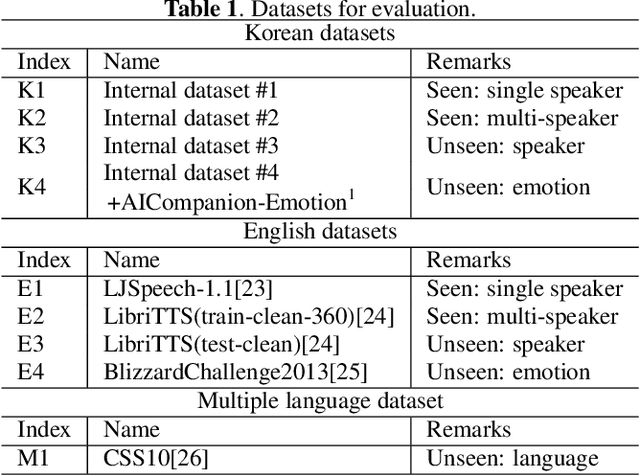
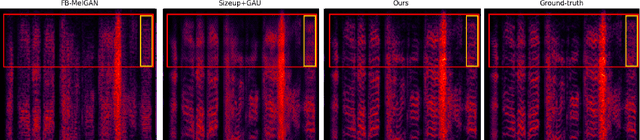
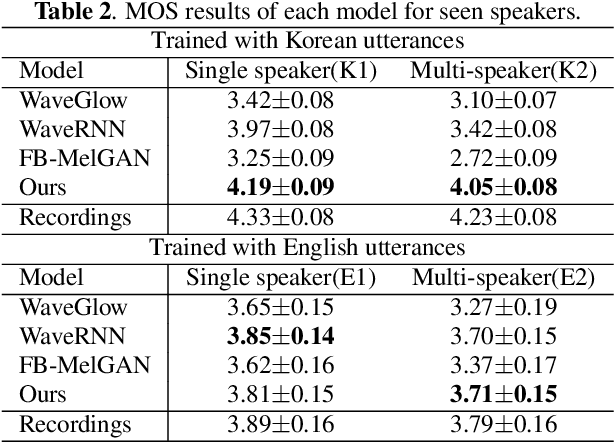
We propose Universal MelGAN, a vocoder that synthesizes high-fidelity speech in multiple domains. To preserve sound quality when the MelGAN-based structure is trained with a dataset of hundreds of speakers, we added multi-resolution spectrogram discriminators to sharpen the spectral resolution of the generated waveforms. This enables the model to generate realistic waveforms of multi-speakers, by alleviating the over-smoothing problem in the high frequency band of the large footprint model. Our structure generates signals close to ground-truth data without reducing the inference speed, by discriminating the waveform and spectrogram during training. The model achieved the best mean opinion score (MOS) in most scenarios using ground-truth mel-spectrogram as an input. Especially, it showed superior performance in unseen domains with regard of speaker, emotion, and language. Moreover, in a multi-speaker text-to-speech scenario using mel-spectrogram generated by a transformer model, it synthesized high-fidelity speech of 4.22 MOS. These results, achieved without external domain information, highlight the potential of the proposed model as a universal vocoder.
JDI-T: Jointly trained Duration Informed Transformer for Text-To-Speech without Explicit Alignment
May 15, 2020
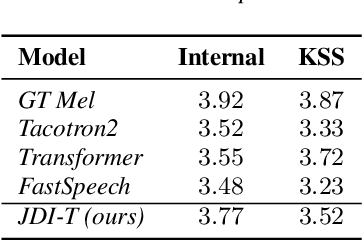
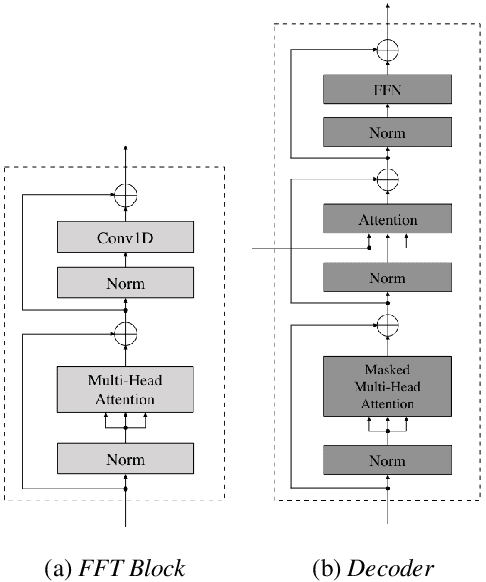
We propose Jointly trained Duration Informed Transformer (JDI-T), a feed-forward Transformer with a duration predictor jointly trained without explicit alignments in order to generate an acoustic feature sequence from an input text. In this work, inspired by the recent success of the duration informed networks such as FastSpeech and DurIAN, we further simplify its sequential, two-stage training pipeline to a single-stage training. Specifically, we extract the phoneme duration from the autoregressive Transformer on the fly during the joint training instead of pretraining the autoregressive model and using it as a phoneme duration extractor. To our best knowledge, it is the first implementation to jointly train the feed-forward Transformer without relying on a pre-trained phoneme duration extractor in a single training pipeline. We evaluate the effectiveness of the proposed model on the publicly available Korean Single speaker Speech (KSS) dataset compared to the baseline text-to-speech (TTS) models trained by ESPnet-TTS.
Convolutional Attention-based Seq2Seq Neural Network for End-to-End ASR
Oct 12, 2017
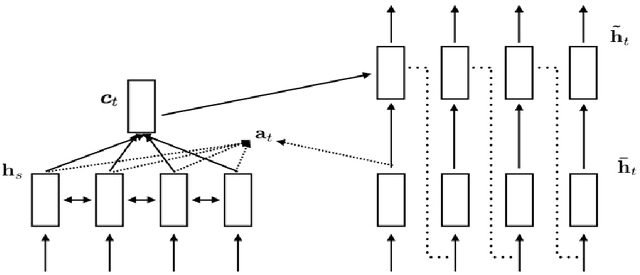
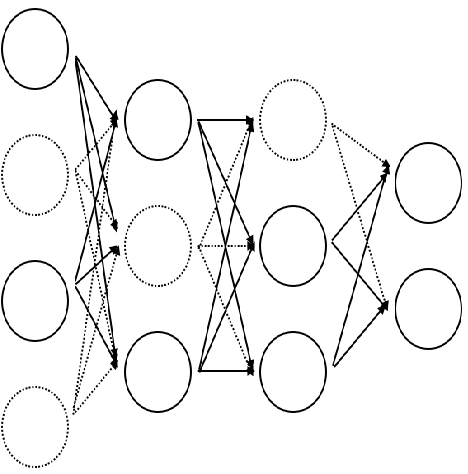
This thesis introduces the sequence to sequence model with Luong's attention mechanism for end-to-end ASR. It also describes various neural network algorithms including Batch normalization, Dropout and Residual network which constitute the convolutional attention-based seq2seq neural network. Finally the proposed model proved its effectiveness for speech recognition achieving 15.8% phoneme error rate on TIMIT dataset.