 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePeeking Into The Future For Contextual Biasing
Dec 19, 2025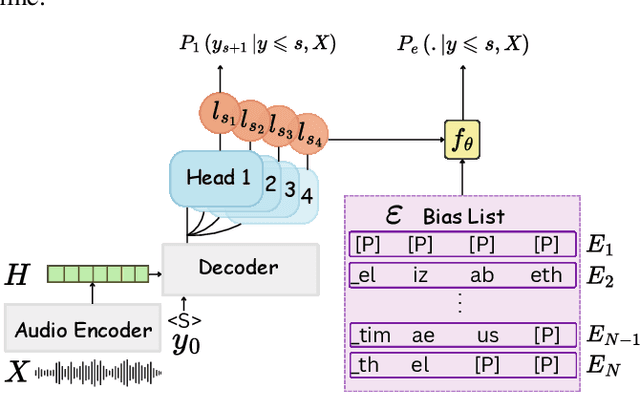
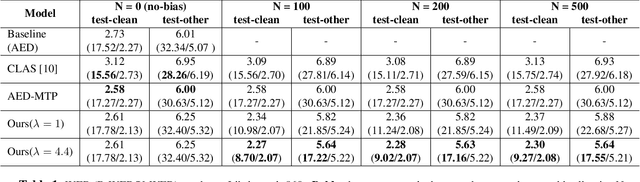
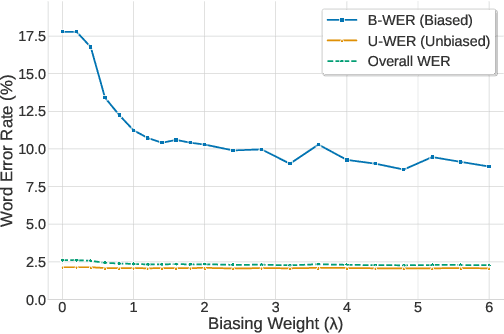
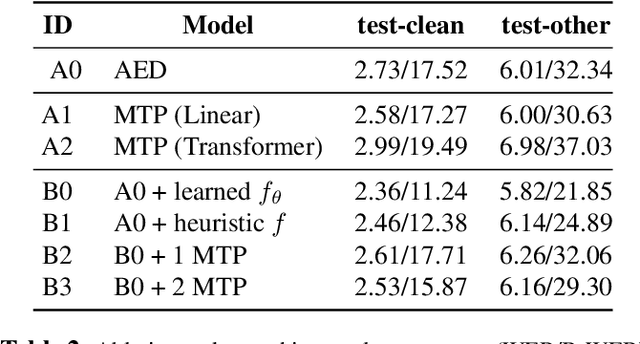
While end-to-end (E2E) automatic speech recognition (ASR) models excel at general transcription, they struggle to recognize rare or unseen named entities (e.g., contact names, locations), which are critical for downstream applications like virtual assistants. In this paper, we propose a contextual biasing method for attention based encoder decoder (AED) models using a list of candidate named entities. Instead of predicting only the next token, we simultaneously predict multiple future tokens, enabling the model to "peek into the future" and score potential candidate entities in the entity list. Moreover, our approach leverages the multi-token prediction logits directly without requiring additional entity encoders or cross-attention layers, significantly reducing architectural complexity. Experiments on Librispeech demonstrate that our approach achieves up to 50.34% relative improvement in named entity word error rate compared to the baseline AED model.
Enhanced Hybrid Transducer and Attention Encoder Decoder with Text Data
Jun 23, 2025A joint speech and text optimization method is proposed for hybrid transducer and attention-based encoder decoder (TAED) modeling to leverage large amounts of text corpus and enhance ASR accuracy. The joint TAED (J-TAED) is trained with both speech and text input modalities together, while it only takes speech data as input during inference. The trained model can unify the internal representations from different modalities, and be further extended to text-based domain adaptation. It can effectively alleviate data scarcity for mismatch domain tasks since no speech data is required. Our experiments show J-TAED successfully integrates speech and linguistic information into one model, and reduce the WER by 5.8 ~12.8% on the Librispeech dataset. The model is also evaluated on two out-of-domain datasets: one is finance and another is named entity focused. The text-based domain adaptation brings 15.3% and 17.8% WER reduction on those two datasets respectively.
Automatic Pronunciation Assessment using Self-Supervised Speech Representation Learning
Apr 08, 2022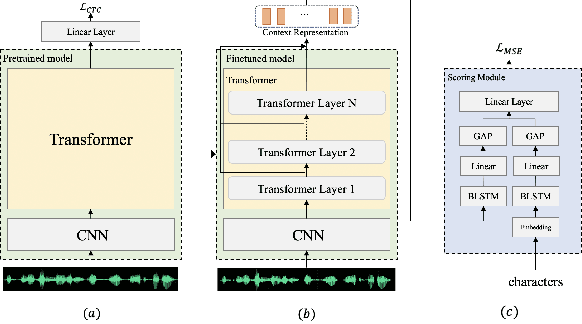
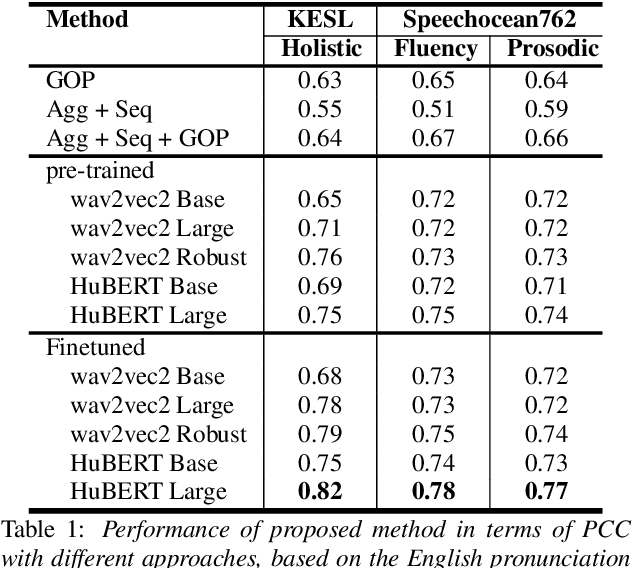
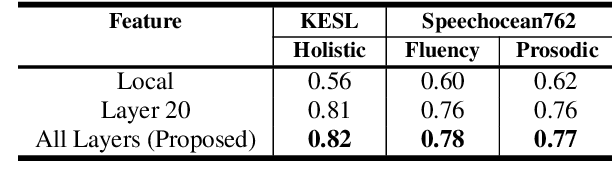
Self-supervised learning (SSL) approaches such as wav2vec 2.0 and HuBERT models have shown promising results in various downstream tasks in the speech community. In particular, speech representations learned by SSL models have been shown to be effective for encoding various speech-related characteristics. In this context, we propose a novel automatic pronunciation assessment method based on SSL models. First, the proposed method fine-tunes the pre-trained SSL models with connectionist temporal classification to adapt the English pronunciation of English-as-a-second-language (ESL) learners in a data environment. Then, the layer-wise contextual representations are extracted from all across the transformer layers of the SSL models. Finally, the automatic pronunciation score is estimated using bidirectional long short-term memory with the layer-wise contextual representations and the corresponding text. We show that the proposed SSL model-based methods outperform the baselines, in terms of the Pearson correlation coefficient, on datasets of Korean ESL learner children and Speechocean762. Furthermore, we analyze how different representations of transformer layers in the SSL model affect the performance of the pronunciation assessment task.
JETS: Jointly Training FastSpeech2 and HiFi-GAN for End to End Text to Speech
Mar 31, 2022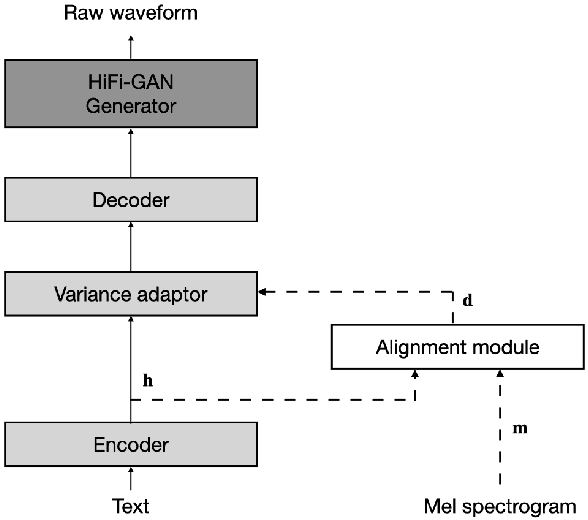
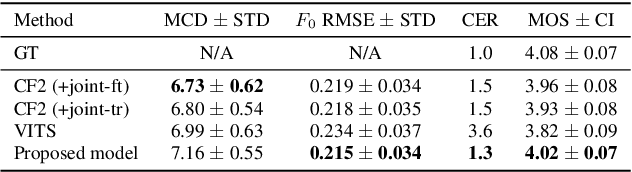
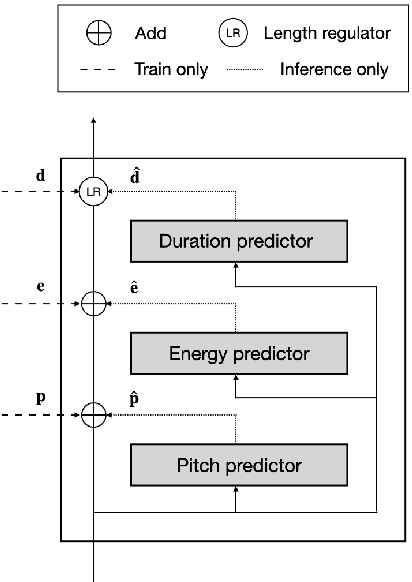
In neural text-to-speech (TTS), two-stage system or a cascade of separately learned models have shown synthesis quality close to human speech. For example, FastSpeech2 transforms an input text to a mel-spectrogram and then HiFi-GAN generates a raw waveform from a mel-spectogram where they are called an acoustic feature generator and a neural vocoder respectively. However, their training pipeline is somewhat cumbersome in that it requires a fine-tuning and an accurate speech-text alignment for optimal performance. In this work, we present end-to-end text-to-speech (E2E-TTS) model which has a simplified training pipeline and outperforms a cascade of separately learned models. Specifically, our proposed model is jointly trained FastSpeech2 and HiFi-GAN with an alignment module. Since there is no acoustic feature mismatch between training and inference, it does not requires fine-tuning. Furthermore, we remove dependency on an external speech-text alignment tool by adopting an alignment learning objective in our joint training framework. Experiments on LJSpeech corpus shows that the proposed model outperforms publicly available, state-of-the-art implementations of ESPNet2-TTS on subjective evaluation (MOS) and some objective evaluations.
Multitask Learning and Joint Optimization for Transformer-RNN-Transducer Speech Recognition
Nov 02, 2020


Recently, several types of end-to-end speech recognition methods named transformer-transducer were introduced. According to those kinds of methods, transcription networks are generally modeled by transformer-based neural networks, while prediction networks could be modeled by either transformers or recurrent neural networks (RNN). This paper explores multitask learning, joint optimization, and joint decoding methods for transformer-RNN-transducer systems. Our proposed methods have the main advantage in that the model can maintain information on the large text corpus. We prove their effectiveness by performing experiments utilizing the well-known ESPNET toolkit for the widely used Librispeech datasets. We also show that the proposed methods can reduce word error rate (WER) by 16.6 % and 13.3 % for test-clean and test-other datasets, respectively, without changing the overall model structure nor exploiting an external LM.