 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePeeking Into The Future For Contextual Biasing
Dec 19, 2025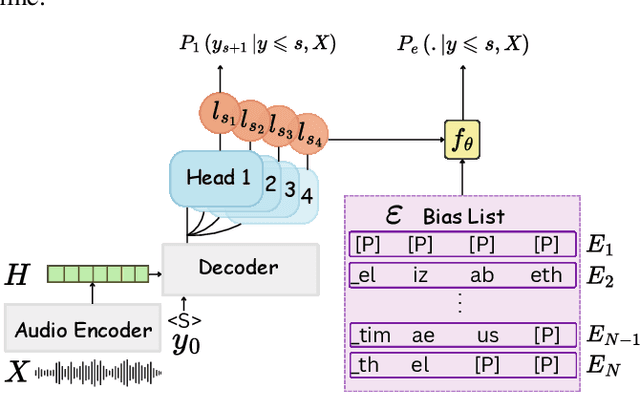
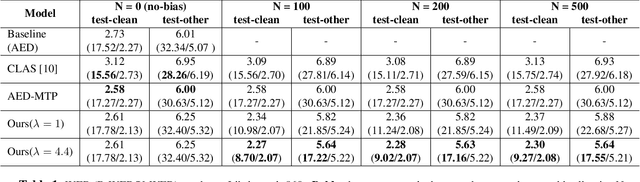
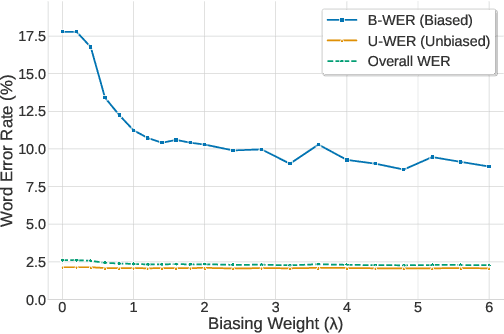
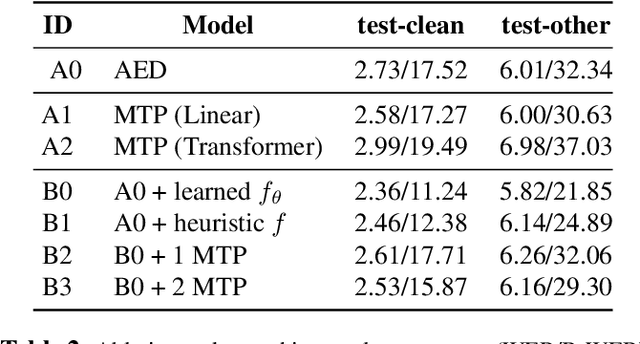
While end-to-end (E2E) automatic speech recognition (ASR) models excel at general transcription, they struggle to recognize rare or unseen named entities (e.g., contact names, locations), which are critical for downstream applications like virtual assistants. In this paper, we propose a contextual biasing method for attention based encoder decoder (AED) models using a list of candidate named entities. Instead of predicting only the next token, we simultaneously predict multiple future tokens, enabling the model to "peek into the future" and score potential candidate entities in the entity list. Moreover, our approach leverages the multi-token prediction logits directly without requiring additional entity encoders or cross-attention layers, significantly reducing architectural complexity. Experiments on Librispeech demonstrate that our approach achieves up to 50.34% relative improvement in named entity word error rate compared to the baseline AED model.
Enhanced Hybrid Transducer and Attention Encoder Decoder with Text Data
Jun 23, 2025A joint speech and text optimization method is proposed for hybrid transducer and attention-based encoder decoder (TAED) modeling to leverage large amounts of text corpus and enhance ASR accuracy. The joint TAED (J-TAED) is trained with both speech and text input modalities together, while it only takes speech data as input during inference. The trained model can unify the internal representations from different modalities, and be further extended to text-based domain adaptation. It can effectively alleviate data scarcity for mismatch domain tasks since no speech data is required. Our experiments show J-TAED successfully integrates speech and linguistic information into one model, and reduce the WER by 5.8 ~12.8% on the Librispeech dataset. The model is also evaluated on two out-of-domain datasets: one is finance and another is named entity focused. The text-based domain adaptation brings 15.3% and 17.8% WER reduction on those two datasets respectively.
Transducer Consistency Regularization for Speech to Text Applications
Oct 09, 2024



Consistency regularization is a commonly used practice to encourage the model to generate consistent representation from distorted input features and improve model generalization. It shows significant improvement on various speech applications that are optimized with cross entropy criterion. However, it is not straightforward to apply consistency regularization for the transducer-based approaches, which are widely adopted for speech applications due to the competitive performance and streaming characteristic. The main challenge is from the vast alignment space of the transducer optimization criterion and not all the alignments within the space contribute to the model optimization equally. In this study, we present Transducer Consistency Regularization (TCR), a consistency regularization method for transducer models. We apply distortions such as spec augmentation and dropout to create different data views and minimize the distribution difference. We utilize occupational probabilities to give different weights on transducer output distributions, thus only alignments close to oracle alignments would contribute to the model learning. Our experiments show the proposed method is superior to other consistency regularization implementations and could effectively reduce word error rate (WER) by 4.3\% relatively comparing with a strong baseline on the \textsc{Librispeech} dataset.
North America Bixby Speaker Diarization System for the VoxCeleb Speaker Recognition Challenge 2021
Sep 28, 2021
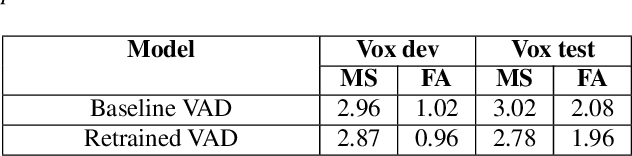
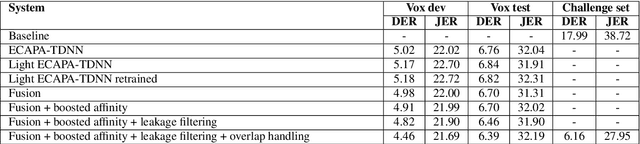
This paper describes the submission to the speaker diarization track of VoxCeleb Speaker Recognition Challenge 2021 done by North America Bixby Lab of Samsung Research America. Our speaker diarization system consists of four main components such as overlap speech detection and speech separation, robust speaker embedding extraction, spectral clustering with fused affinity matrix, and leakage filtering-based postprocessing. We evaluated our system on the VoxConverse dataset and the challenge evaluation set, which contain natural conversations of multiple talkers collected from YouTube. Our system obtained 4.46%, 6.39%, and 6.16% of the diarization error rate on the VoxConverse development, test, and the challenge evaluation set, respectively.
X-Vectors with Multi-Scale Aggregation for Speaker Diarization
May 16, 2021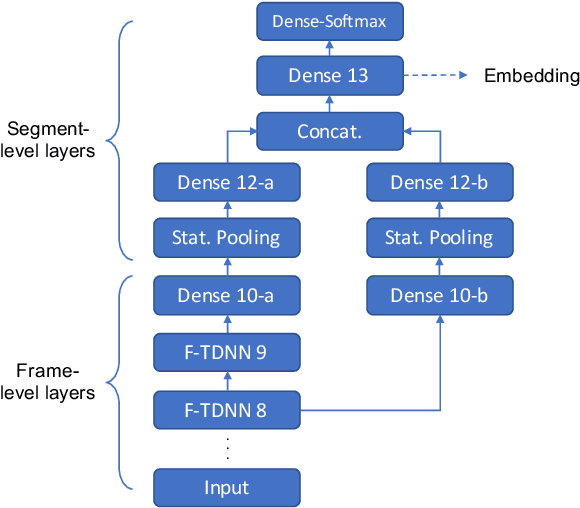
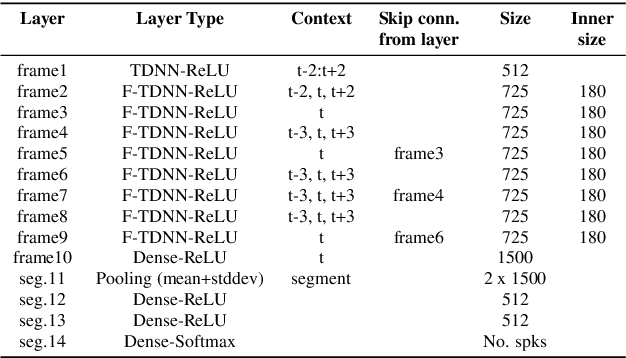


Speaker diarization is the process of labeling different speakers in a speech signal. Deep speaker embeddings are generally extracted from short speech segments and clustered to determine the segments belong to same speaker identity. The x-vector, which embeds segment-level speaker characteristics by statistically pooling frame-level representations, is one of the most widely used deep speaker embeddings in speaker diarization. Multi-scale aggregation, which employs multi-scale representations from different layers, has recently successfully been used in short duration speaker verification. In this paper, we investigate a multi-scale aggregation approach in an x-vector embedding framework for speaker diarization by exploiting multiple statistics pooling layers from different frame-level layers. Thus, it is expected that x-vectors with multi-scale aggregation have the potential to capture meaningful speaker characteristics from short segments, effectively taking advantage of different information at multiple layers. Experimental evaluation on the CALLHOME dataset showed that our approach provides substantial improvement over the baseline x-vectors.