 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIR-UWB Radar-Based Contactless Silent Speech Recognition of Vowels, Consonants, Words, and Phrases
Dec 15, 2023



Several sensing techniques have been proposed for silent speech recognition (SSR); however, many of these methods require invasive processes or sensor attachment to the skin using adhesive tape or glue, rendering them unsuitable for frequent use in daily life. By contrast, impulse radio ultra-wideband (IR-UWB) radar can operate without physical contact with users' articulators and related body parts, offering several advantages for SSR. These advantages include high range resolution, high penetrability, low power consumption, robustness to external light or sound interference, and the ability to be embedded in space-constrained handheld devices. This study demonstrated IR-UWB radar-based contactless SSR using four types of speech stimuli (vowels, consonants, words, and phrases). To achieve this, a novel speech feature extraction algorithm specifically designed for IR-UWB radar-based SSR is proposed. Each speech stimulus is recognized by applying a classification algorithm to the extracted speech features. Two different algorithms, multidimensional dynamic time warping (MD-DTW) and deep neural network-hidden Markov model (DNN-HMM), were compared for the classification task. Additionally, a favorable radar antenna position, either in front of the user's lips or below the user's chin, was determined to achieve higher recognition accuracy. Experimental results demonstrated the efficacy of the proposed speech feature extraction algorithm combined with DNN-HMM for classifying vowels, consonants, words, and phrases. Notably, this study represents the first demonstration of phoneme-level SSR using contactless radar.
North America Bixby Speaker Diarization System for the VoxCeleb Speaker Recognition Challenge 2021
Sep 28, 2021
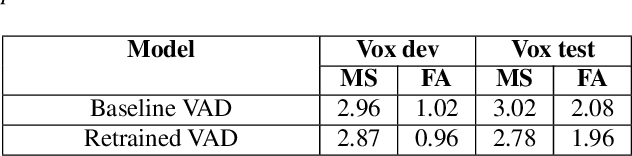
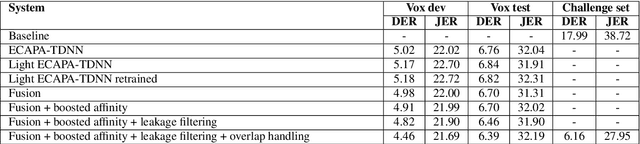
This paper describes the submission to the speaker diarization track of VoxCeleb Speaker Recognition Challenge 2021 done by North America Bixby Lab of Samsung Research America. Our speaker diarization system consists of four main components such as overlap speech detection and speech separation, robust speaker embedding extraction, spectral clustering with fused affinity matrix, and leakage filtering-based postprocessing. We evaluated our system on the VoxConverse dataset and the challenge evaluation set, which contain natural conversations of multiple talkers collected from YouTube. Our system obtained 4.46%, 6.39%, and 6.16% of the diarization error rate on the VoxConverse development, test, and the challenge evaluation set, respectively.
X-Vectors with Multi-Scale Aggregation for Speaker Diarization
May 16, 2021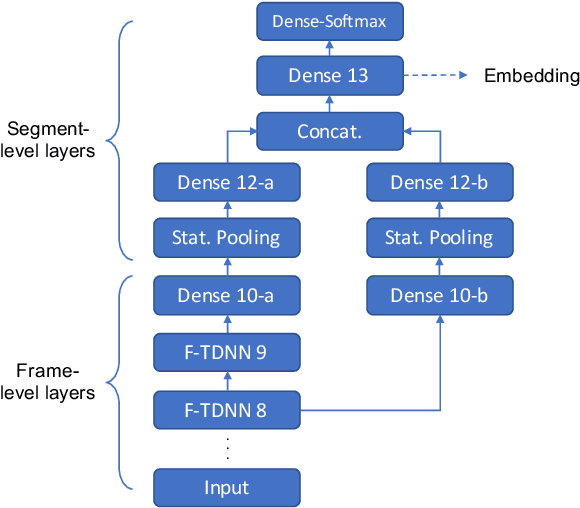
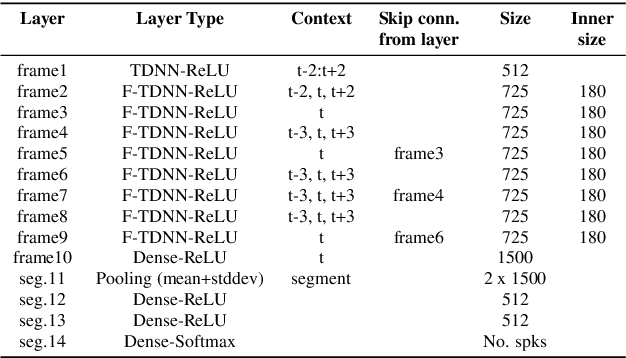


Speaker diarization is the process of labeling different speakers in a speech signal. Deep speaker embeddings are generally extracted from short speech segments and clustered to determine the segments belong to same speaker identity. The x-vector, which embeds segment-level speaker characteristics by statistically pooling frame-level representations, is one of the most widely used deep speaker embeddings in speaker diarization. Multi-scale aggregation, which employs multi-scale representations from different layers, has recently successfully been used in short duration speaker verification. In this paper, we investigate a multi-scale aggregation approach in an x-vector embedding framework for speaker diarization by exploiting multiple statistics pooling layers from different frame-level layers. Thus, it is expected that x-vectors with multi-scale aggregation have the potential to capture meaningful speaker characteristics from short segments, effectively taking advantage of different information at multiple layers. Experimental evaluation on the CALLHOME dataset showed that our approach provides substantial improvement over the baseline x-vectors.