 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeX-Vectors with Multi-Scale Aggregation for Speaker Diarization
Paper and Code
May 16, 2021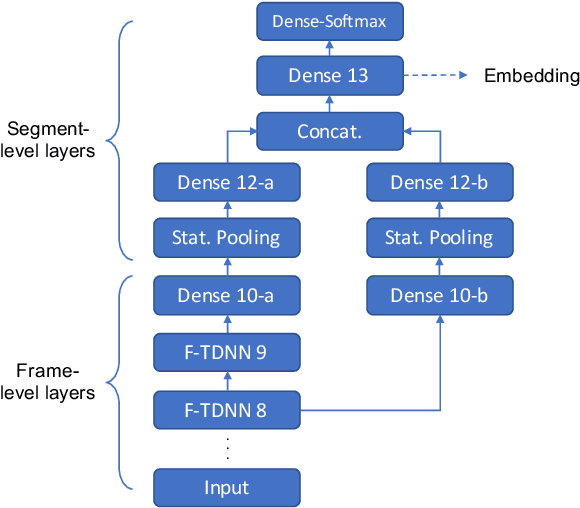
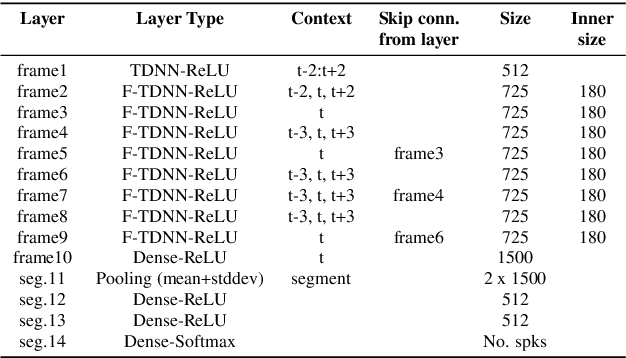


Speaker diarization is the process of labeling different speakers in a speech signal. Deep speaker embeddings are generally extracted from short speech segments and clustered to determine the segments belong to same speaker identity. The x-vector, which embeds segment-level speaker characteristics by statistically pooling frame-level representations, is one of the most widely used deep speaker embeddings in speaker diarization. Multi-scale aggregation, which employs multi-scale representations from different layers, has recently successfully been used in short duration speaker verification. In this paper, we investigate a multi-scale aggregation approach in an x-vector embedding framework for speaker diarization by exploiting multiple statistics pooling layers from different frame-level layers. Thus, it is expected that x-vectors with multi-scale aggregation have the potential to capture meaningful speaker characteristics from short segments, effectively taking advantage of different information at multiple layers. Experimental evaluation on the CALLHOME dataset showed that our approach provides substantial improvement over the baseline x-vectors.