 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultitask Learning and Joint Optimization for Transformer-RNN-Transducer Speech Recognition
Paper and Code
Nov 02, 2020

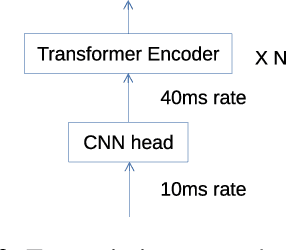

Recently, several types of end-to-end speech recognition methods named transformer-transducer were introduced. According to those kinds of methods, transcription networks are generally modeled by transformer-based neural networks, while prediction networks could be modeled by either transformers or recurrent neural networks (RNN). This paper explores multitask learning, joint optimization, and joint decoding methods for transformer-RNN-transducer systems. Our proposed methods have the main advantage in that the model can maintain information on the large text corpus. We prove their effectiveness by performing experiments utilizing the well-known ESPNET toolkit for the widely used Librispeech datasets. We also show that the proposed methods can reduce word error rate (WER) by 16.6 % and 13.3 % for test-clean and test-other datasets, respectively, without changing the overall model structure nor exploiting an external LM.