 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwitchLight: Co-design of Physics-driven Architecture and Pre-training Framework for Human Portrait Relighting
Feb 29, 2024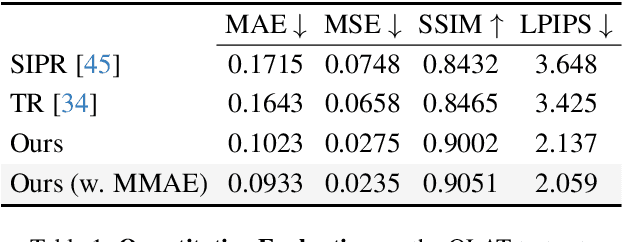

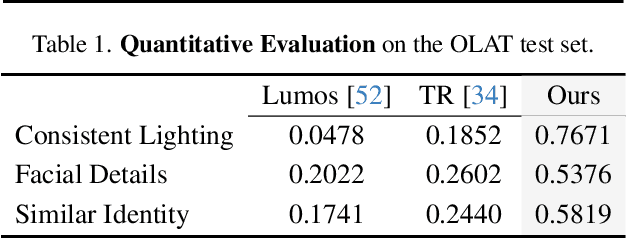

We introduce a co-designed approach for human portrait relighting that combines a physics-guided architecture with a pre-training framework. Drawing on the Cook-Torrance reflectance model, we have meticulously configured the architecture design to precisely simulate light-surface interactions. Furthermore, to overcome the limitation of scarce high-quality lightstage data, we have developed a self-supervised pre-training strategy. This novel combination of accurate physical modeling and expanded training dataset establishes a new benchmark in relighting realism.
Automatic Pronunciation Assessment using Self-Supervised Speech Representation Learning
Apr 08, 2022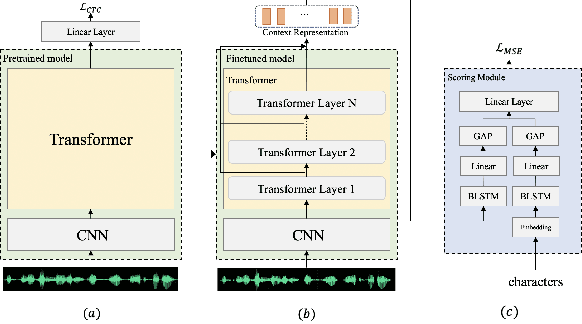
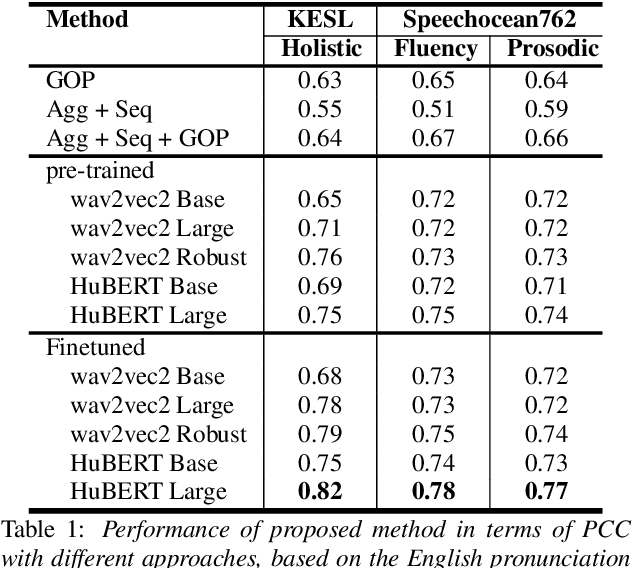
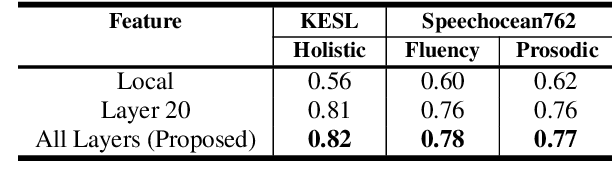
Self-supervised learning (SSL) approaches such as wav2vec 2.0 and HuBERT models have shown promising results in various downstream tasks in the speech community. In particular, speech representations learned by SSL models have been shown to be effective for encoding various speech-related characteristics. In this context, we propose a novel automatic pronunciation assessment method based on SSL models. First, the proposed method fine-tunes the pre-trained SSL models with connectionist temporal classification to adapt the English pronunciation of English-as-a-second-language (ESL) learners in a data environment. Then, the layer-wise contextual representations are extracted from all across the transformer layers of the SSL models. Finally, the automatic pronunciation score is estimated using bidirectional long short-term memory with the layer-wise contextual representations and the corresponding text. We show that the proposed SSL model-based methods outperform the baselines, in terms of the Pearson correlation coefficient, on datasets of Korean ESL learner children and Speechocean762. Furthermore, we analyze how different representations of transformer layers in the SSL model affect the performance of the pronunciation assessment task.