 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFastFit: Towards Real-Time Iterative Neural Vocoder by Replacing U-Net Encoder With Multiple STFTs
May 18, 2023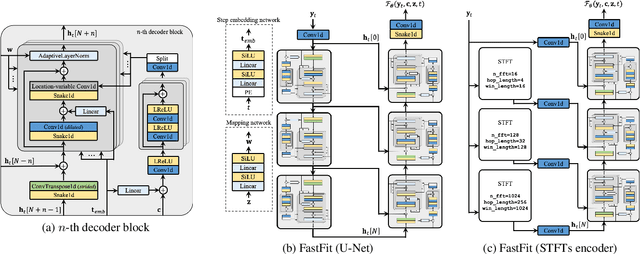


This paper presents FastFit, a novel neural vocoder architecture that replaces the U-Net encoder with multiple short-time Fourier transforms (STFTs) to achieve faster generation rates without sacrificing sample quality. We replaced each encoder block with an STFT, with parameters equal to the temporal resolution of each decoder block, leading to the skip connection. FastFit reduces the number of parameters and the generation time of the model by almost half while maintaining high fidelity. Through objective and subjective evaluations, we demonstrated that the proposed model achieves nearly twice the generation speed of baseline iteration-based vocoders while maintaining high sound quality. We further showed that FastFit produces sound qualities similar to those of other baselines in text-to-speech evaluation scenarios, including multi-speaker and zero-shot text-to-speech.