 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJDI-T: Jointly trained Duration Informed Transformer for Text-To-Speech without Explicit Alignment
May 15, 2020
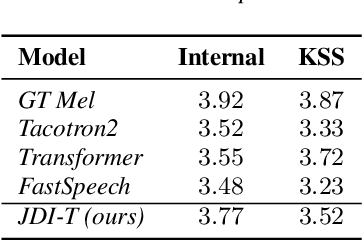
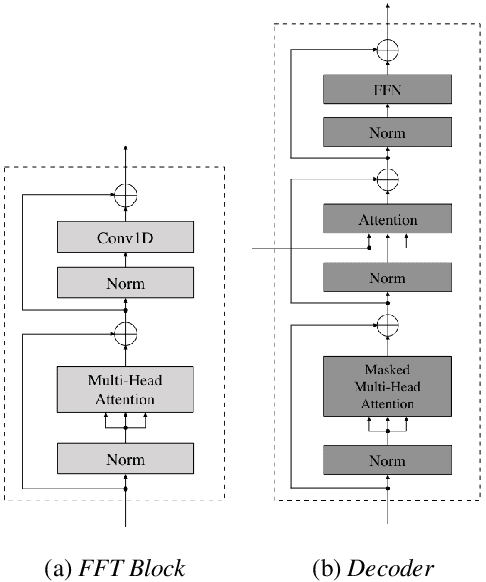
We propose Jointly trained Duration Informed Transformer (JDI-T), a feed-forward Transformer with a duration predictor jointly trained without explicit alignments in order to generate an acoustic feature sequence from an input text. In this work, inspired by the recent success of the duration informed networks such as FastSpeech and DurIAN, we further simplify its sequential, two-stage training pipeline to a single-stage training. Specifically, we extract the phoneme duration from the autoregressive Transformer on the fly during the joint training instead of pretraining the autoregressive model and using it as a phoneme duration extractor. To our best knowledge, it is the first implementation to jointly train the feed-forward Transformer without relying on a pre-trained phoneme duration extractor in a single training pipeline. We evaluate the effectiveness of the proposed model on the publicly available Korean Single speaker Speech (KSS) dataset compared to the baseline text-to-speech (TTS) models trained by ESPnet-TTS.