 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal MelGAN: A Robust Neural Vocoder for High-Fidelity Waveform Generation in Multiple Domains
Paper and Code
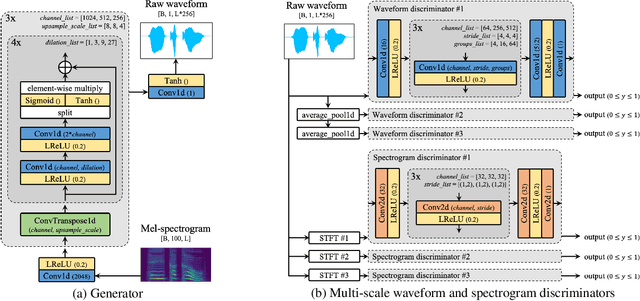
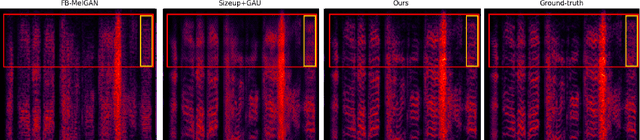
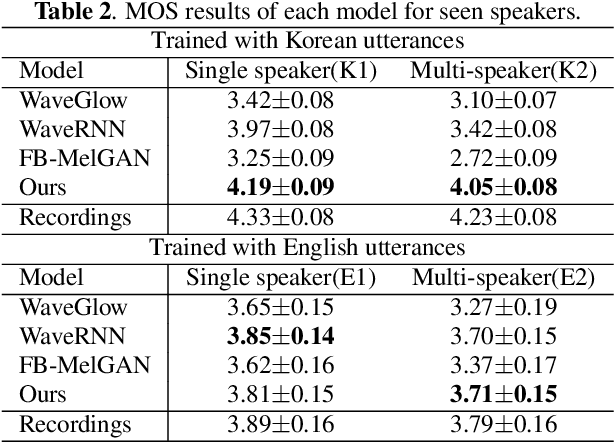
We propose Universal MelGAN, a vocoder that synthesizes high-fidelity speech in multiple domains. To preserve sound quality when the MelGAN-based structure is trained with a dataset of hundreds of speakers, we added multi-resolution spectrogram discriminators to sharpen the spectral resolution of the generated waveforms. This enables the model to generate realistic waveforms of multi-speakers, by alleviating the over-smoothing problem in the high frequency band of the large footprint model. Our structure generates signals close to ground-truth data without reducing the inference speed, by discriminating the waveform and spectrogram during training. The model achieved the best mean opinion score (MOS) in most scenarios using ground-truth mel-spectrogram as an input. Especially, it showed superior performance in unseen domains with regard of speaker, emotion, and language. Moreover, in a multi-speaker text-to-speech scenario using mel-spectrogram generated by a transformer model, it synthesized high-fidelity speech of 4.22 MOS. These results, achieved without external domain information, highlight the potential of the proposed model as a universal vocoder.