 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLMLT: Low-to-high Multi-Level Vision Transformer for Image Super-Resolution
Sep 05, 2024



Recent Vision Transformer (ViT)-based methods for Image Super-Resolution have demonstrated impressive performance. However, they suffer from significant complexity, resulting in high inference times and memory usage. Additionally, ViT models using Window Self-Attention (WSA) face challenges in processing regions outside their windows. To address these issues, we propose the Low-to-high Multi-Level Transformer (LMLT), which employs attention with varying feature sizes for each head. LMLT divides image features along the channel dimension, gradually reduces spatial size for lower heads, and applies self-attention to each head. This approach effectively captures both local and global information. By integrating the results from lower heads into higher heads, LMLT overcomes the window boundary issues in self-attention. Extensive experiments show that our model significantly reduces inference time and GPU memory usage while maintaining or even surpassing the performance of state-of-the-art ViT-based Image Super-Resolution methods. Our codes are availiable at https://github.com/jwgdmkj/LMLT.
Relational Self-supervised Distillation with Compact Descriptors for Image Copy Detection
May 29, 2024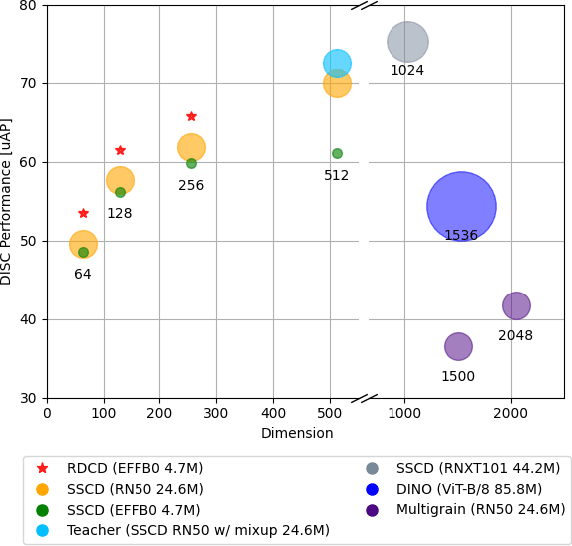
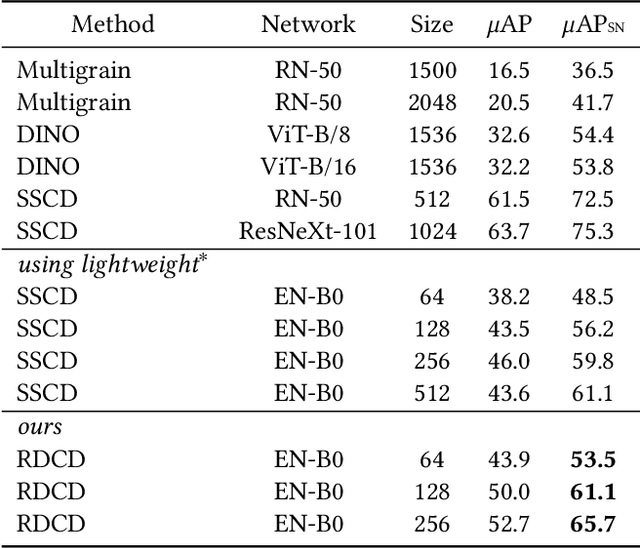
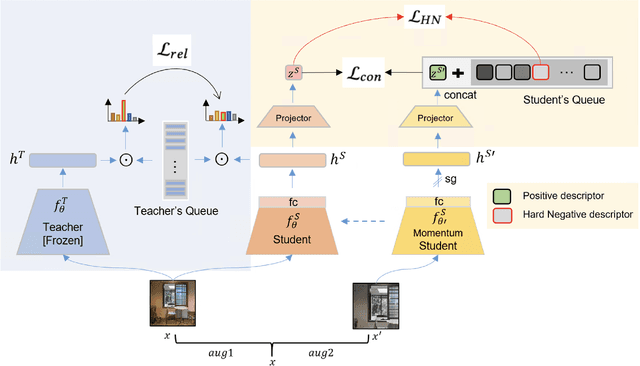

This paper addresses image copy detection, a task in online sharing platforms for copyright protection. While previous approaches have performed exceptionally well, the large size of their networks and descriptors remains a significant disadvantage, complicating their practical application. In this paper, we propose a novel method that achieves a competitive performance by using a lightweight network and compact descriptors. By utilizing relational self-supervised distillation to transfer knowledge from a large network to a small network, we enable the training of lightweight networks with a small descriptor size. Our approach, which we call Relational selfsupervised Distillation with Compact Descriptors (RDCD), introduces relational self-supervised distillation (RSD) for flexible representation in a smaller feature space and applies contrastive learning with a hard negative (HN) loss to prevent dimensional collapse. We demonstrate the effectiveness of our method using the DISC2021, Copydays, and NDEC benchmark datasets, with which our lightweight network with compact descriptors achieves a competitive performance. For the DISC2021 benchmark, ResNet-50/EfficientNet- B0 are used as a teacher and student respectively, the micro average precision improved by 5.0%/4.9%/5.9% for 64/128/256 descriptor sizes compared to the baseline method.
SoccerNet 2023 Challenges Results
Sep 12, 2023



The SoccerNet 2023 challenges were the third annual video understanding challenges organized by the SoccerNet team. For this third edition, the challenges were composed of seven vision-based tasks split into three main themes. The first theme, broadcast video understanding, is composed of three high-level tasks related to describing events occurring in the video broadcasts: (1) action spotting, focusing on retrieving all timestamps related to global actions in soccer, (2) ball action spotting, focusing on retrieving all timestamps related to the soccer ball change of state, and (3) dense video captioning, focusing on describing the broadcast with natural language and anchored timestamps. The second theme, field understanding, relates to the single task of (4) camera calibration, focusing on retrieving the intrinsic and extrinsic camera parameters from images. The third and last theme, player understanding, is composed of three low-level tasks related to extracting information about the players: (5) re-identification, focusing on retrieving the same players across multiple views, (6) multiple object tracking, focusing on tracking players and the ball through unedited video streams, and (7) jersey number recognition, focusing on recognizing the jersey number of players from tracklets. Compared to the previous editions of the SoccerNet challenges, tasks (2-3-7) are novel, including new annotations and data, task (4) was enhanced with more data and annotations, and task (6) now focuses on end-to-end approaches. More information on the tasks, challenges, and leaderboards are available on https://www.soccer-net.org. Baselines and development kits can be found on https://github.com/SoccerNet.
Approach for Video Classification with Multi-label on YouTube-8M Dataset
Oct 14, 2018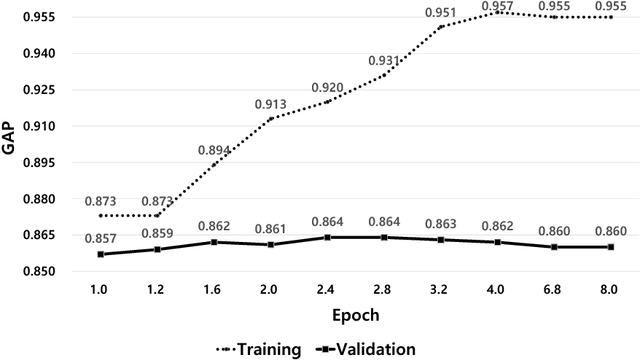

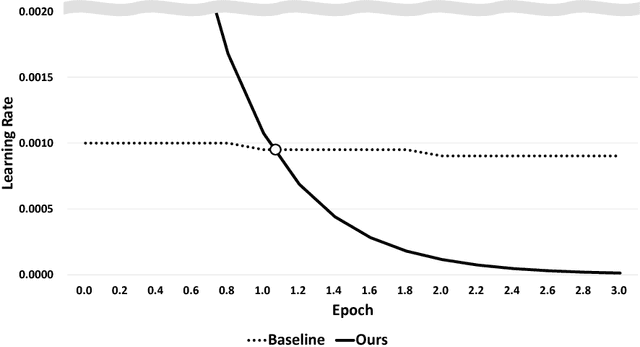

Video traffic is increasing at a considerable rate due to the spread of personal media and advancements in media technology. Accordingly, there is a growing need for techniques to automatically classify moving images. This paper use NetVLAD and NetFV models and the Huber loss function for video classification problem and YouTube-8M dataset to verify the experiment. We tried various attempts according to the dataset and optimize hyperparameters, ultimately obtain a GAP score of 0.8668.