 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpace-time inverse-scattering of translation-based motion
Dec 12, 2024



In optical diffraction tomography (ODT), a sample's 3D refractive-index (RI) is often reconstructed after illuminating it from multiple angles, with the assumption that the sample remains static throughout data collection. When the sample undergoes dynamic motion during this data-collection process, significant artifacts and distortions compromise the fidelity of the reconstructed images. In this study, we develop a space-time inverse-scattering technique for ODT that compensates for the translational motion of multiple-scattering samples during data collection. Our approach involves formulating a joint optimization problem to simultaneously estimate a scattering sample's translational position at each measurement and its motion-corrected 3D RI distribution. Experimental results demonstrate the technique's effectiveness, yielding reconstructions with reduced artifacts, enhanced spatial resolution, and improved quantitative accuracy for samples undergoing continuous translational motion during imaging.
LMLT: Low-to-high Multi-Level Vision Transformer for Image Super-Resolution
Sep 05, 2024



Recent Vision Transformer (ViT)-based methods for Image Super-Resolution have demonstrated impressive performance. However, they suffer from significant complexity, resulting in high inference times and memory usage. Additionally, ViT models using Window Self-Attention (WSA) face challenges in processing regions outside their windows. To address these issues, we propose the Low-to-high Multi-Level Transformer (LMLT), which employs attention with varying feature sizes for each head. LMLT divides image features along the channel dimension, gradually reduces spatial size for lower heads, and applies self-attention to each head. This approach effectively captures both local and global information. By integrating the results from lower heads into higher heads, LMLT overcomes the window boundary issues in self-attention. Extensive experiments show that our model significantly reduces inference time and GPU memory usage while maintaining or even surpassing the performance of state-of-the-art ViT-based Image Super-Resolution methods. Our codes are availiable at https://github.com/jwgdmkj/LMLT.
Ptychographic lens-less polarization microscopy
Sep 13, 2022

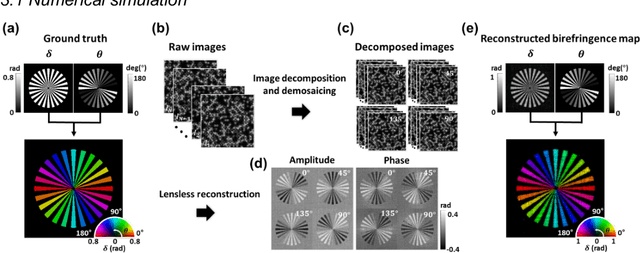

Birefringence, an inherent characteristic of optically anisotropic materials, is widely utilized in various imaging applications ranging from material characterizations to clinical diagnosis. Polarized light microscopy enables high-resolution, high-contrast imaging of optically anisotropic specimens, but it is associated with mechanical rotations of polarizer/analyzer and relatively complex optical designs. Here, we present a novel form of polarization-sensitive microscopy capable of birefringence imaging of transparent objects without an optical lens and any moving parts. Our method exploits an optical mask-modulated polarization image sensor and single-input-state LED illumination design to obtain complex and birefringence images of the object via ptychographic phase retrieval. Using a camera with a pixel resolution of 3.45 um, the method achieves birefringence imaging with a half-pitch resolution of 2.46 um over a 59.74 mm^2 field-of-view, which corresponds to a space-bandwidth product of 9.9 megapixels. We demonstrate the high-resolution, large-area birefringence imaging capability of our method by presenting the birefringence images of various anisotropic objects, including a birefringent resolution target, liquid crystal polymer depolarizer, monosodium urate crystal, and excised mouse eye and heart tissues.
Temporal Flow Mask Attention for Open-Set Long-Tailed Recognition of Wild Animals in Camera-Trap Images
Aug 31, 2022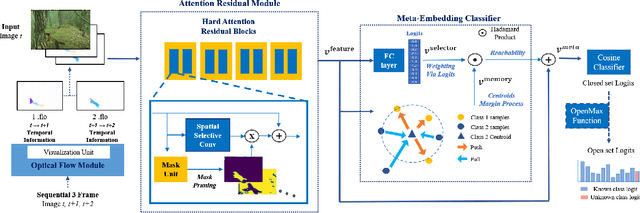
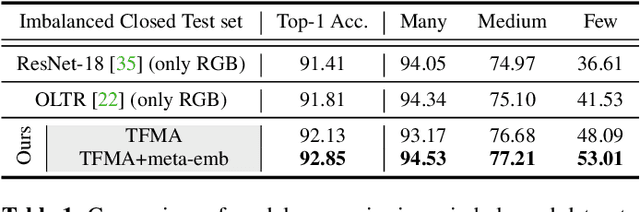
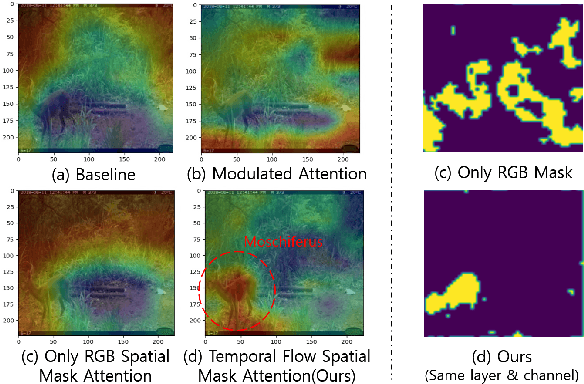
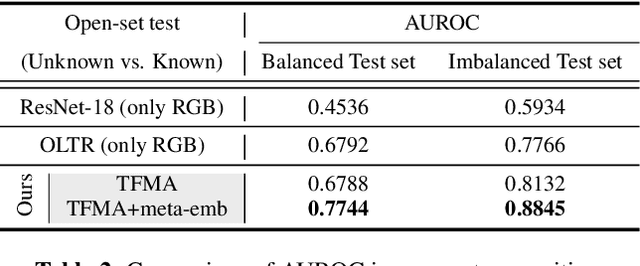
Camera traps, unmanned observation devices, and deep learning-based image recognition systems have greatly reduced human effort in collecting and analyzing wildlife images. However, data collected via above apparatus exhibits 1) long-tailed and 2) open-ended distribution problems. To tackle the open-set long-tailed recognition problem, we propose the Temporal Flow Mask Attention Network that comprises three key building blocks: 1) an optical flow module, 2) an attention residual module, and 3) a meta-embedding classifier. We extract temporal features of sequential frames using the optical flow module and learn informative representation using attention residual blocks. Moreover, we show that applying the meta-embedding technique boosts the performance of the method in open-set long-tailed recognition. We apply this method on a Korean Demilitarized Zone (DMZ) dataset. We conduct extensive experiments, and quantitative and qualitative analyses to prove that our method effectively tackles the open-set long-tailed recognition problem while being robust to unknown classes.
Balancing Domain Experts for Long-Tailed Camera-Trap Recognition
Feb 16, 2022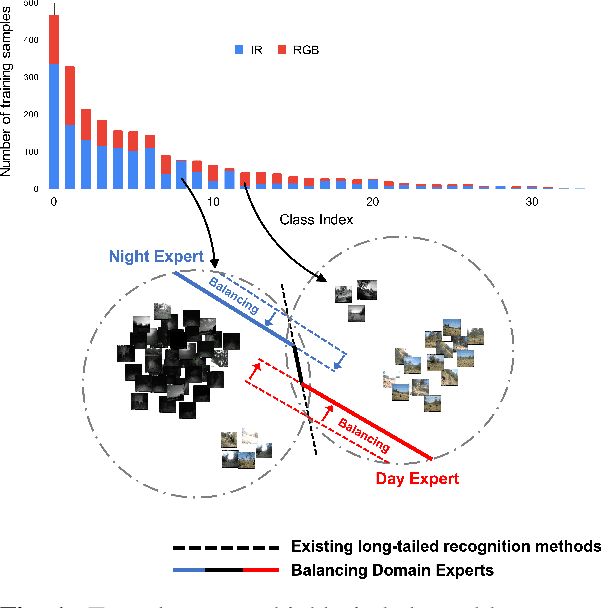
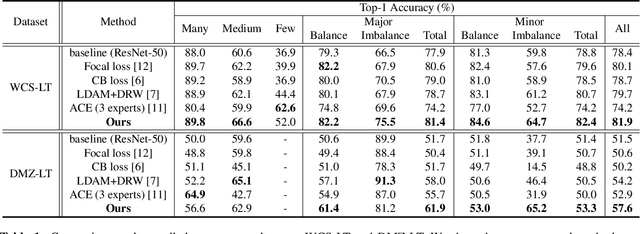
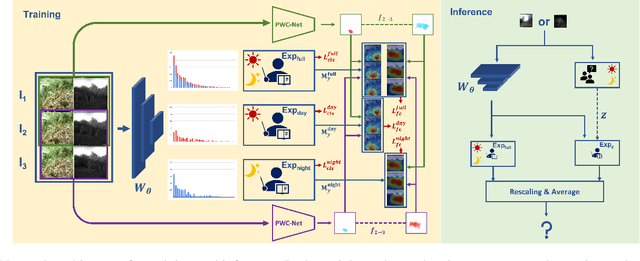
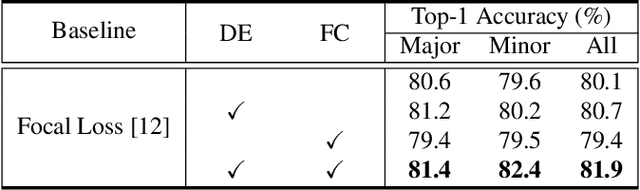
Label distributions in camera-trap images are highly imbalanced and long-tailed, resulting in neural networks tending to be biased towards head-classes that appear frequently. Although long-tail learning has been extremely explored to address data imbalances, few studies have been conducted to consider camera-trap characteristics, such as multi-domain and multi-frame setup. Here, we propose a unified framework and introduce two datasets for long-tailed camera-trap recognition. We first design domain experts, where each expert learns to balance imperfect decision boundaries caused by data imbalances and complement each other to generate domain-balanced decision boundaries. Also, we propose a flow consistency loss to focus on moving objects, expecting class activation maps of multi-frame matches the flow with optical flow maps for input images. Moreover, two long-tailed camera-trap datasets, WCS-LT and DMZ-LT, are introduced to validate our methods. Experimental results show the effectiveness of our framework, and proposed methods outperform previous methods on recessive domain samples.