 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Self-Attention for learning graph representation with Transformer
Paper and Code
Jan 30, 2022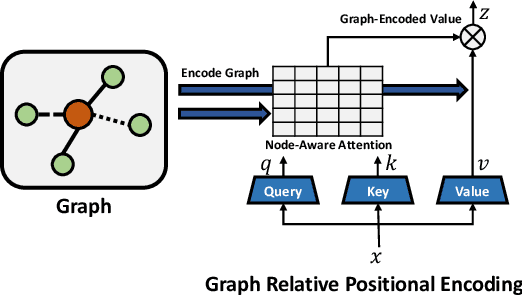

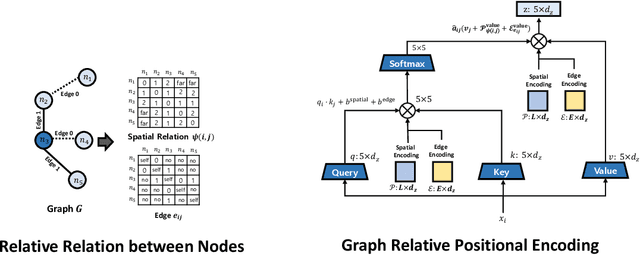
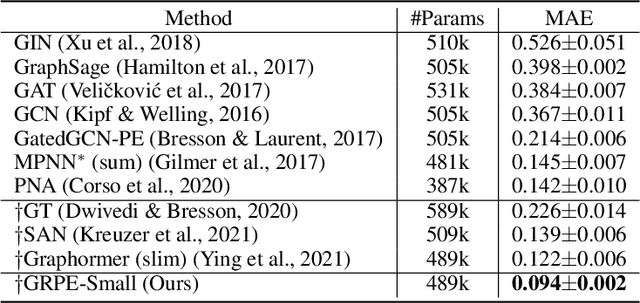
We propose a novel Graph Self-Attention module to enable Transformer models to learn graph representation. We aim to incorporate graph information, on the attention map and hidden representations of Transformer. To this end, we propose context-aware attention which considers the interactions between query, key and graph information. Moreover, we propose graph-embedded value to encode the graph information on the hidden representation. Our extensive experiments and ablation studies validate that our method successfully encodes graph representation on Transformer architecture. Finally, our method achieves state-of-the-art performance on multiple benchmarks of graph representation learning, such as graph classification on images and molecules to graph regression on quantum chemistry.