 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePost-training quantization of vision encoders needs prefixing registers
Oct 06, 2025



Transformer-based vision encoders -- such as CLIP -- are central to multimodal intelligence, powering applications from autonomous web agents to robotic control. Since these applications often demand real-time processing of massive visual data, reducing the inference cost of vision encoders is critical. Post-training quantization offers a practical path, but remains challenging even at 8-bit precision due to massive-scale activations (i.e., outliers). In this work, we propose $\textit{RegCache}$, a training-free algorithm to mitigate outliers in vision encoders, enabling quantization with significantly smaller accuracy drops. The proposed RegCache introduces outlier-prone yet semantically meaningless prefix tokens to the target vision encoder, which prevents other tokens from having outliers. Notably, we observe that outliers in vision encoders behave differently from those in language models, motivating two technical innovations: middle-layer prefixing and token deletion. Experiments show that our method consistently improves the accuracy of quantized models across both text-supervised and self-supervised vision encoders.
GuidedQuant: Large Language Model Quantization via Exploiting End Loss Guidance
May 11, 2025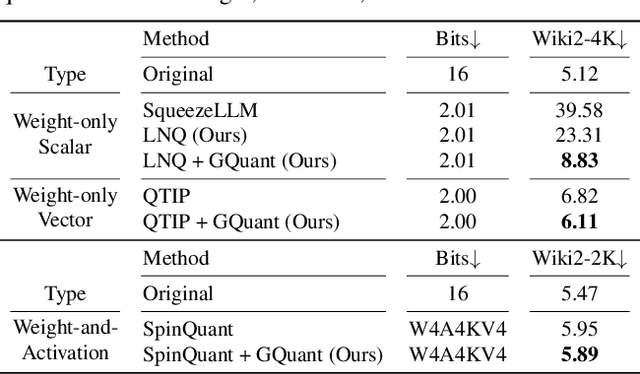
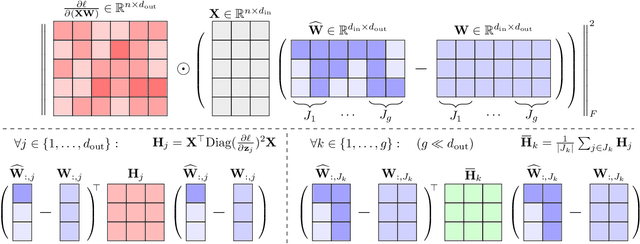
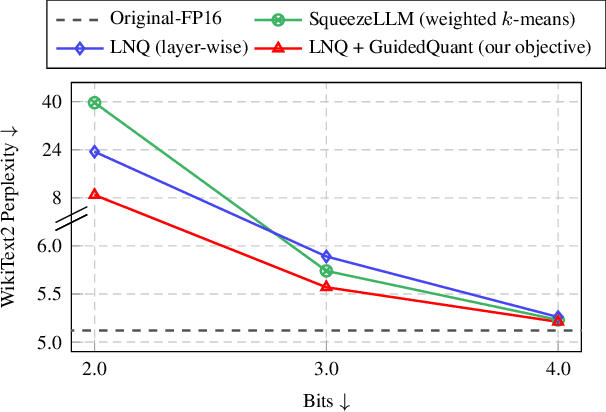
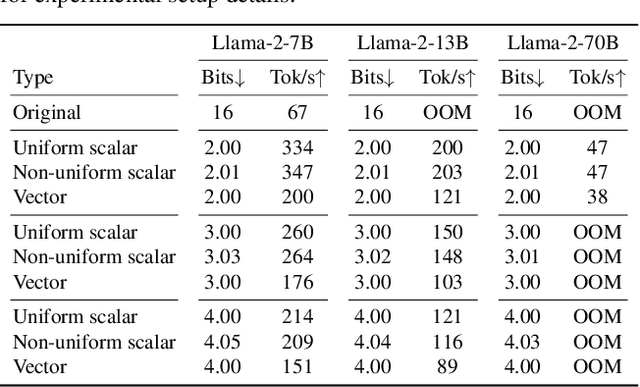
Post-training quantization is a key technique for reducing the memory and inference latency of large language models by quantizing weights and activations without requiring retraining. However, existing methods either (1) fail to account for the varying importance of hidden features to the end loss or, when incorporating end loss, (2) neglect the critical interactions between model weights. To address these limitations, we propose GuidedQuant, a novel quantization approach that integrates gradient information from the end loss into the quantization objective while preserving cross-weight dependencies within output channels. GuidedQuant consistently boosts the performance of state-of-the-art quantization methods across weight-only scalar, weight-only vector, and weight-and-activation quantization. Additionally, we introduce a novel non-uniform scalar quantization algorithm, which is guaranteed to monotonically decrease the quantization objective value, and outperforms existing methods in this category. We release the code at https://github.com/snu-mllab/GuidedQuant.
Compression Scaling Laws:Unifying Sparsity and Quantization
Feb 23, 2025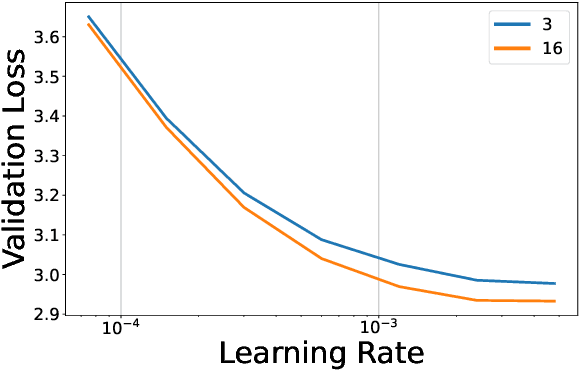
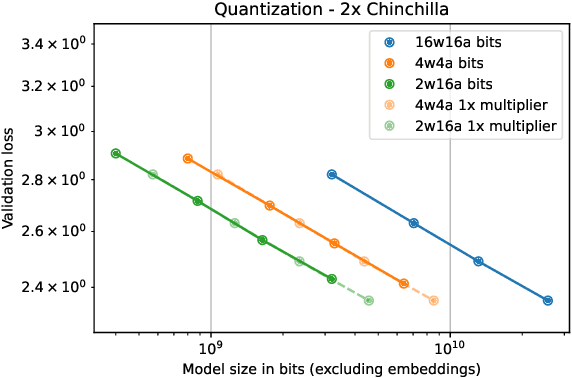
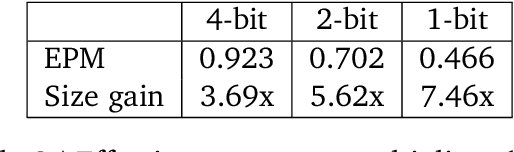
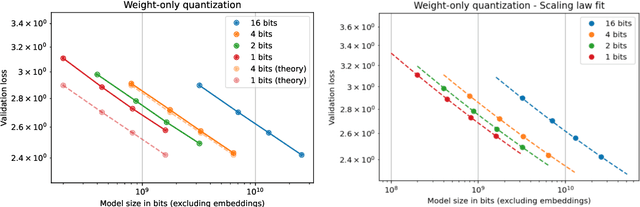
We investigate how different compression techniques -- such as weight and activation quantization, and weight sparsity -- affect the scaling behavior of large language models (LLMs) during pretraining. Building on previous work showing that weight sparsity acts as a constant multiplier on model size in scaling laws, we demonstrate that this "effective parameter" scaling pattern extends to quantization as well. Specifically, we establish that weight-only quantization achieves strong parameter efficiency multipliers, while full quantization of both weights and activations shows diminishing returns at lower bitwidths. Our results suggest that different compression techniques can be unified under a common scaling law framework, enabling principled comparison and combination of these methods.
LCIRC: A Recurrent Compression Approach for Efficient Long-form Context and Query Dependent Modeling in LLMs
Feb 10, 2025



While large language models (LLMs) excel in generating coherent and contextually rich outputs, their capacity to efficiently handle long-form contexts is limited by fixed-length position embeddings. Additionally, the computational cost of processing long sequences increases quadratically, making it challenging to extend context length. To address these challenges, we propose Long-form Context Injection with Recurrent Compression (LCIRC), a method that enables the efficient processing long-form sequences beyond the model's length limit through recurrent compression without retraining the entire model. We further introduce query dependent context modeling, which selectively compresses query-relevant information, ensuring that the model retains the most pertinent content. Our empirical results demonstrate that Query Dependent LCIRC (QD-LCIRC) significantly improves LLM's ability to manage extended contexts, making it well-suited for tasks that require both comprehensive context understanding and query relevance.
Rethinking Pruning Large Language Models: Benefits and Pitfalls of Reconstruction Error Minimization
Jun 21, 2024
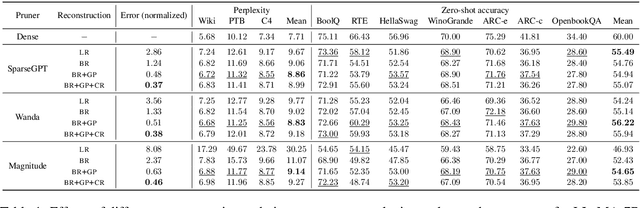


This work suggests fundamentally rethinking the current practice of pruning large language models (LLMs). The way it is done is by divide and conquer: split the model into submodels, sequentially prune them, and reconstruct predictions of the dense counterparts on small calibration data one at a time; the final model is obtained simply by putting the resulting sparse submodels together. While this approach enables pruning under memory constraints, it generates high reconstruction errors. In this work, we first present an array of reconstruction techniques that can significantly reduce this error by more than $90\%$. Unwittingly, however, we discover that minimizing reconstruction error is not always ideal and can overfit the given calibration data, resulting in rather increased language perplexity and poor performance at downstream tasks. We find out that a strategy of self-generating calibration data can mitigate this trade-off between reconstruction and generalization, suggesting new directions in the presence of both benefits and pitfalls of reconstruction for pruning LLMs.
Prefixing Attention Sinks can Mitigate Activation Outliers for Large Language Model Quantization
Jun 17, 2024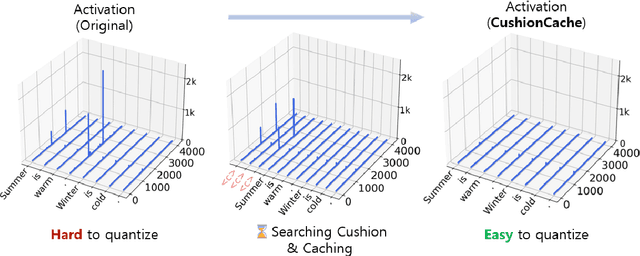
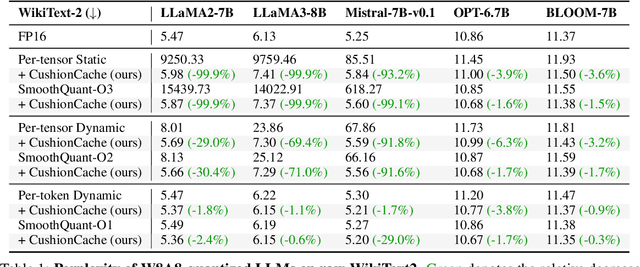
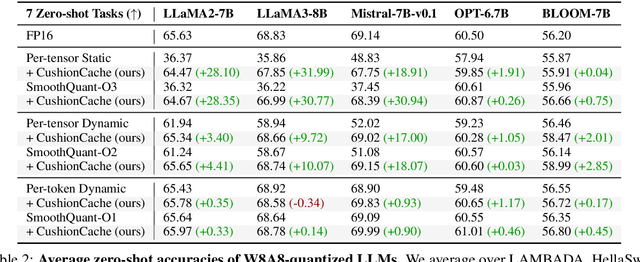
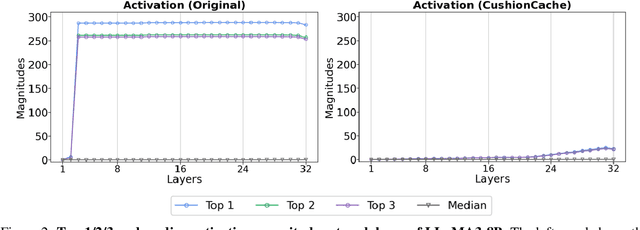
Despite recent advances in LLM quantization, activation quantization remains to be challenging due to the activation outliers. Conventional remedies, e.g., mixing precisions for different channels, introduce extra overhead and reduce the speedup. In this work, we develop a simple yet effective strategy to facilitate per-tensor activation quantization by preventing the generation of problematic tokens. Precisely, we propose a method to find a set of key-value cache, coined CushionCache, which mitigates outliers in subsequent tokens when inserted as a prefix. CushionCache works in two steps: First, we greedily search for a prompt token sequence that minimizes the maximum activation values in subsequent tokens. Then, we further tune the token cache to regularize the activations of subsequent tokens to be more quantization-friendly. The proposed method successfully addresses activation outliers of LLMs, providing a substantial performance boost for per-tensor activation quantization methods. We thoroughly evaluate our method over a wide range of models and benchmarks and find that it significantly surpasses the established baseline of per-tensor W8A8 quantization and can be seamlessly integrated with the recent activation quantization method.
JaxPruner: A concise library for sparsity research
May 02, 2023


This paper introduces JaxPruner, an open-source JAX-based pruning and sparse training library for machine learning research. JaxPruner aims to accelerate research on sparse neural networks by providing concise implementations of popular pruning and sparse training algorithms with minimal memory and latency overhead. Algorithms implemented in JaxPruner use a common API and work seamlessly with the popular optimization library Optax, which, in turn, enables easy integration with existing JAX based libraries. We demonstrate this ease of integration by providing examples in four different codebases: Scenic, t5x, Dopamine and FedJAX and provide baseline experiments on popular benchmarks.
Graph Self-Attention for learning graph representation with Transformer
Jan 30, 2022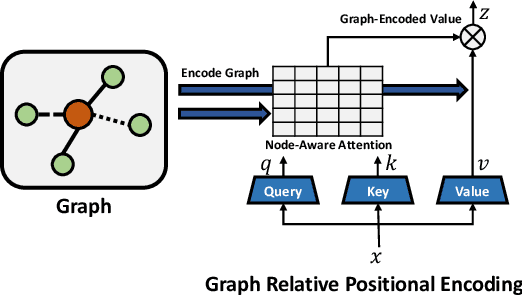

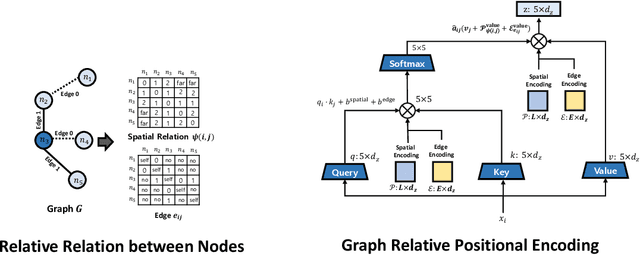
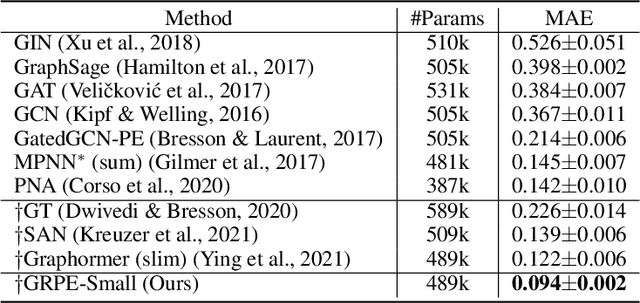
We propose a novel Graph Self-Attention module to enable Transformer models to learn graph representation. We aim to incorporate graph information, on the attention map and hidden representations of Transformer. To this end, we propose context-aware attention which considers the interactions between query, key and graph information. Moreover, we propose graph-embedded value to encode the graph information on the hidden representation. Our extensive experiments and ablation studies validate that our method successfully encodes graph representation on Transformer architecture. Finally, our method achieves state-of-the-art performance on multiple benchmarks of graph representation learning, such as graph classification on images and molecules to graph regression on quantum chemistry.
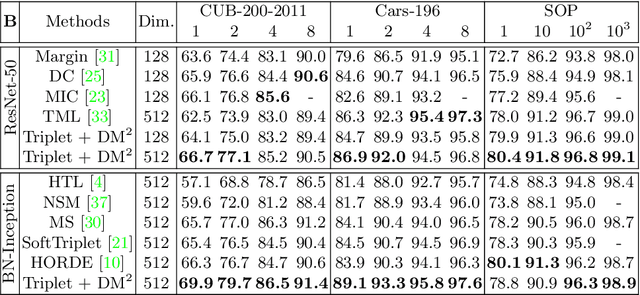
Multi-level Distance Regularization for Deep Metric Learning
Feb 08, 2021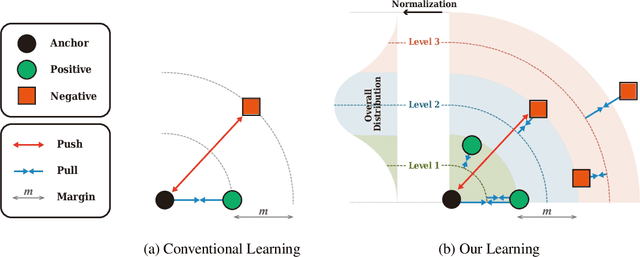
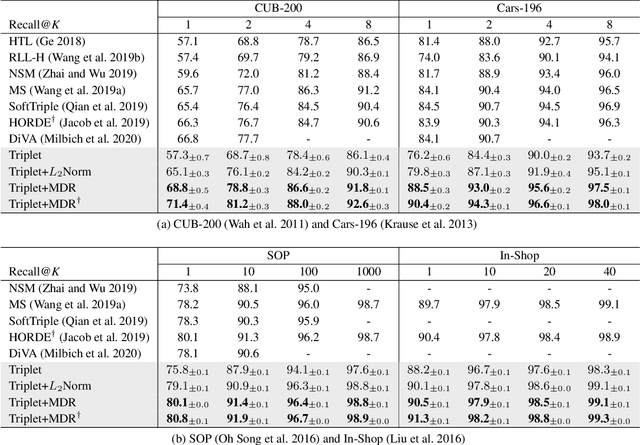
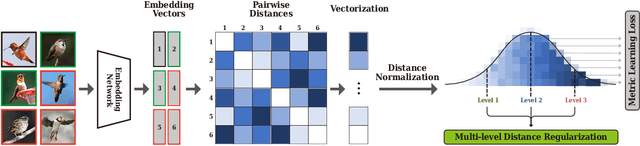
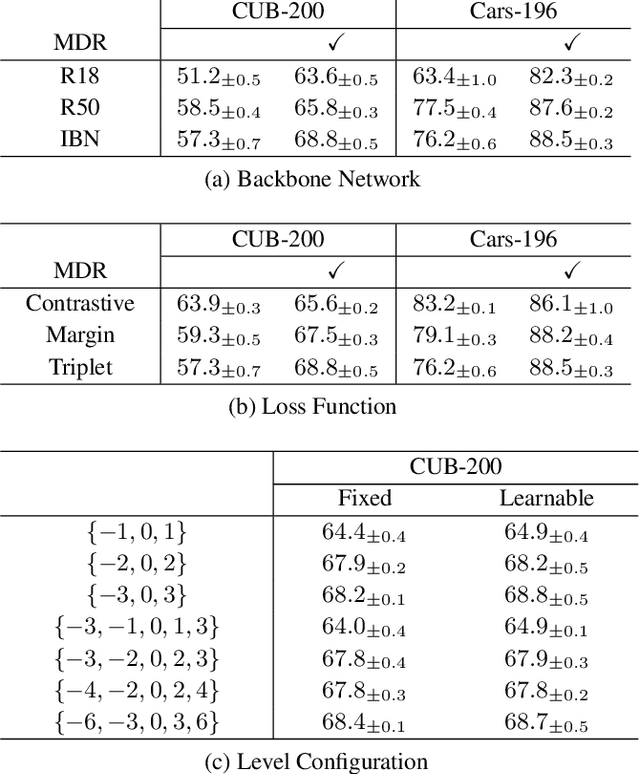
We propose a novel distance-based regularization method for deep metric learning called Multi-level Distance Regularization (MDR). MDR explicitly disturbs a learning procedure by regularizing pairwise distances between embedding vectors into multiple levels that represents a degree of similarity between a pair. In the training stage, the model is trained with both MDR and an existing loss function of deep metric learning, simultaneously; the two losses interfere with the objective of each other, and it makes the learning process difficult. Moreover, MDR prevents some examples from being ignored or overly influenced in the learning process. These allow the parameters of the embedding network to be settle on a local optima with better generalization. Without bells and whistles, MDR with simple Triplet loss achieves the-state-of-the-art performance in various benchmark datasets: CUB-200-2011, Cars-196, Stanford Online Products, and In-Shop Clothes Retrieval. We extensively perform ablation studies on its behaviors to show the effectiveness of MDR. By easily adopting our MDR, the previous approaches can be improved in performance and generalization ability.
Diversified Mutual Learning for Deep Metric Learning
Sep 09, 2020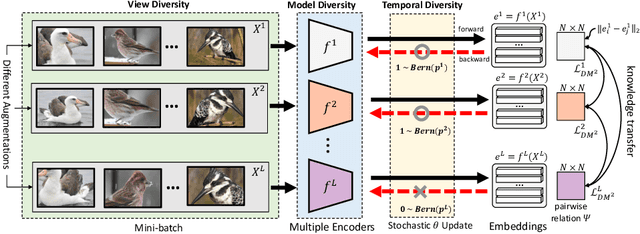
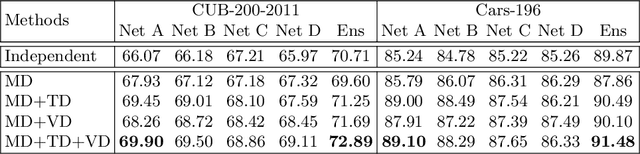
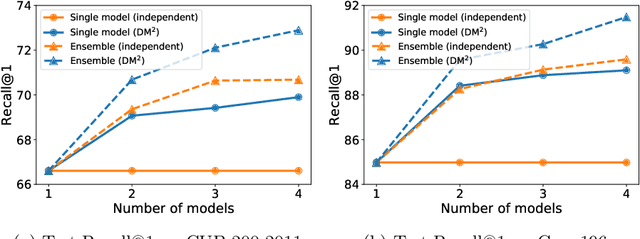
Mutual learning is an ensemble training strategy to improve generalization by transferring individual knowledge to each other while simultaneously training multiple models. In this work, we propose an effective mutual learning method for deep metric learning, called Diversified Mutual Metric Learning, which enhances embedding models with diversified mutual learning. We transfer relational knowledge for deep metric learning by leveraging three kinds of diversities in mutual learning: (1) model diversity from different initializations of models, (2) temporal diversity from different frequencies of parameter update, and (3) view diversity from different augmentations of inputs. Our method is particularly adequate for inductive transfer learning at the lack of large-scale data, where the embedding model is initialized with a pretrained model and then fine-tuned on a target dataset. Extensive experiments show that our method significantly improves individual models as well as their ensemble. Finally, the proposed method with a conventional triplet loss achieves the state-of-the-art performance of Recall@1 on standard datasets: 69.9 on CUB-200-2011 and 89.1 on CARS-196.