 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Staleness in Asynchronous Pipeline Parallelism via Basis Rotation
Feb 03, 2026Asynchronous pipeline parallelism maximizes hardware utilization by eliminating the pipeline bubbles inherent in synchronous execution, offering a path toward efficient large-scale distributed training. However, this efficiency gain can be compromised by gradient staleness, where the immediate model updates with delayed gradients introduce noise into the optimization process. Crucially, we identify a critical, yet often overlooked, pathology: this delay scales linearly with pipeline depth, fundamentally undermining the very scalability that the method originally intends to provide. In this work, we investigate this inconsistency and bridge the gap by rectifying delayed gradients through basis rotation, restoring scalable asynchronous training while maintaining performance. Specifically, we observe that the deleterious effects of delayed gradients are exacerbated when the Hessian eigenbasis is misaligned with the standard coordinate basis. We demonstrate that this misalignment prevents coordinate-wise adaptive schemes, such as Adam, from effectively leveraging curvature-aware adaptivity. This failure leads to significant oscillations in the optimization trajectory and, consequently, slower convergence. We substantiate these findings through both rigorous theoretical analysis and empirical evaluation. To address this challenge, we propose the use of basis rotation, demonstrating that it effectively mitigates the alignment issue and significantly accelerates convergence in asynchronous settings. For example, our training of a 1B-parameter LLM with basis rotation achieves the same training loss in 76.8% fewer iterations compared to the best-performing asynchronous pipeline parallel training baseline.
Rethinking Pruning Large Language Models: Benefits and Pitfalls of Reconstruction Error Minimization
Jun 21, 2024
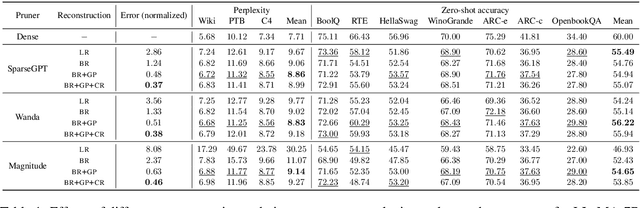


This work suggests fundamentally rethinking the current practice of pruning large language models (LLMs). The way it is done is by divide and conquer: split the model into submodels, sequentially prune them, and reconstruct predictions of the dense counterparts on small calibration data one at a time; the final model is obtained simply by putting the resulting sparse submodels together. While this approach enables pruning under memory constraints, it generates high reconstruction errors. In this work, we first present an array of reconstruction techniques that can significantly reduce this error by more than $90\%$. Unwittingly, however, we discover that minimizing reconstruction error is not always ideal and can overfit the given calibration data, resulting in rather increased language perplexity and poor performance at downstream tasks. We find out that a strategy of self-generating calibration data can mitigate this trade-off between reconstruction and generalization, suggesting new directions in the presence of both benefits and pitfalls of reconstruction for pruning LLMs.
The Effects of Overparameterization on Sharpness-aware Minimization: An Empirical and Theoretical Analysis
Nov 29, 2023
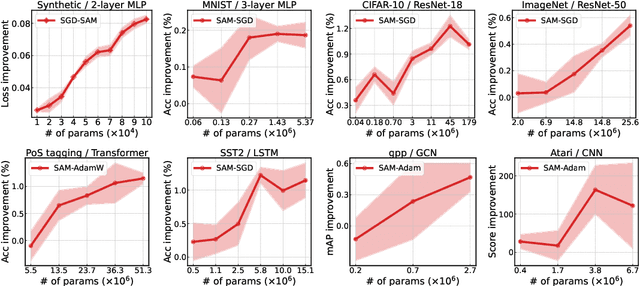
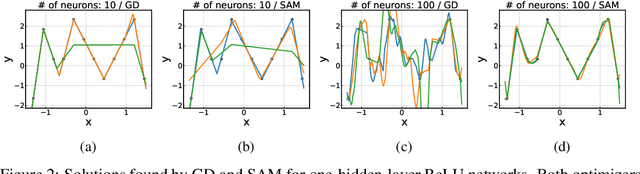

Training an overparameterized neural network can yield minimizers of the same level of training loss and yet different generalization capabilities. With evidence that indicates a correlation between sharpness of minima and their generalization errors, increasing efforts have been made to develop an optimization method to explicitly find flat minima as more generalizable solutions. This sharpness-aware minimization (SAM) strategy, however, has not been studied much yet as to how overparameterization can actually affect its behavior. In this work, we analyze SAM under varying degrees of overparameterization and present both empirical and theoretical results that suggest a critical influence of overparameterization on SAM. Specifically, we first use standard techniques in optimization to prove that SAM can achieve a linear convergence rate under overparameterization in a stochastic setting. We also show that the linearly stable minima found by SAM are indeed flatter and have more uniformly distributed Hessian moments compared to those of SGD. These results are corroborated with our experiments that reveal a consistent trend that the generalization improvement made by SAM continues to increase as the model becomes more overparameterized. We further present that sparsity can open up an avenue for effective overparameterization in practice.
A Closer Look at the Intervention Procedure of Concept Bottleneck Models
Feb 28, 2023Concept bottleneck models (CBMs) are a class of interpretable neural network models that predict the target response of a given input based on its high-level concepts. Unlike the standard end-to-end models, CBMs enable domain experts to intervene on the predicted concepts and rectify any mistakes at test time, so that more accurate task predictions can be made at the end. While such intervenability provides a powerful avenue of control, many aspects of the intervention procedure remain rather unexplored. In this work, we develop various ways of selecting intervening concepts to improve the intervention effectiveness and conduct an array of in-depth analyses as to how they evolve under different circumstances. Specifically, we find that an informed intervention strategy can reduce the task error more than ten times compared to the current baseline under the same amount of intervention counts in realistic settings, and yet, this can vary quite significantly when taking into account different intervention granularity. We verify our findings through comprehensive evaluations, not only on the standard real datasets, but also on synthetic datasets that we generate based on a set of different causal graphs. We further discover some major pitfalls of the current practices which, without a proper addressing, raise concerns on reliability and fairness of the intervention procedure.