 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Effects of Overparameterization on Sharpness-aware Minimization: An Empirical and Theoretical Analysis
Paper and Code

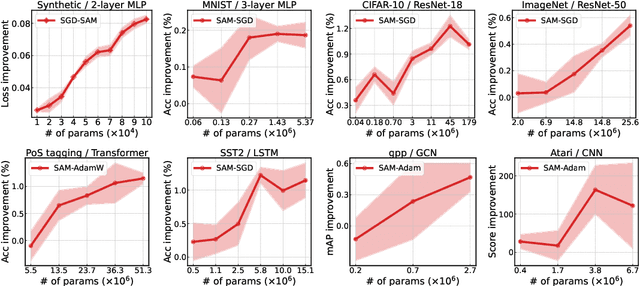
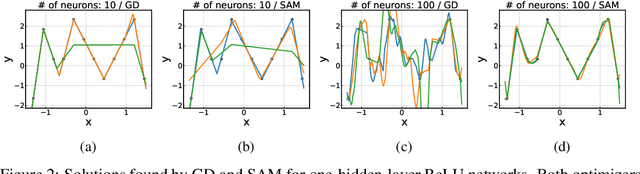

Training an overparameterized neural network can yield minimizers of the same level of training loss and yet different generalization capabilities. With evidence that indicates a correlation between sharpness of minima and their generalization errors, increasing efforts have been made to develop an optimization method to explicitly find flat minima as more generalizable solutions. This sharpness-aware minimization (SAM) strategy, however, has not been studied much yet as to how overparameterization can actually affect its behavior. In this work, we analyze SAM under varying degrees of overparameterization and present both empirical and theoretical results that suggest a critical influence of overparameterization on SAM. Specifically, we first use standard techniques in optimization to prove that SAM can achieve a linear convergence rate under overparameterization in a stochastic setting. We also show that the linearly stable minima found by SAM are indeed flatter and have more uniformly distributed Hessian moments compared to those of SGD. These results are corroborated with our experiments that reveal a consistent trend that the generalization improvement made by SAM continues to increase as the model becomes more overparameterized. We further present that sparsity can open up an avenue for effective overparameterization in practice.