 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo Web Toolkits for Multimodal Piano Performance Dataset Acquisition and Fingering Annotation
Sep 18, 2025Piano performance is a multimodal activity that intrinsically combines physical actions with the acoustic rendition. Despite growing research interest in analyzing the multimodal nature of piano performance, the laborious process of acquiring large-scale multimodal data remains a significant bottleneck, hindering further progress in this field. To overcome this barrier, we present an integrated web toolkit comprising two graphical user interfaces (GUIs): (i) PiaRec, which supports the synchronized acquisition of audio, video, MIDI, and performance metadata. (ii) ASDF, which enables the efficient annotation of performer fingering from the visual data. Collectively, this system can streamline the acquisition of multimodal piano performance datasets.
PianoVAM: A Multimodal Piano Performance Dataset
Sep 10, 2025



The multimodal nature of music performance has driven increasing interest in data beyond the audio domain within the music information retrieval (MIR) community. This paper introduces PianoVAM, a comprehensive piano performance dataset that includes videos, audio, MIDI, hand landmarks, fingering labels, and rich metadata. The dataset was recorded using a Disklavier piano, capturing audio and MIDI from amateur pianists during their daily practice sessions, alongside synchronized top-view videos in realistic and varied performance conditions. Hand landmarks and fingering labels were extracted using a pretrained hand pose estimation model and a semi-automated fingering annotation algorithm. We discuss the challenges encountered during data collection and the alignment process across different modalities. Additionally, we describe our fingering annotation method based on hand landmarks extracted from videos. Finally, we present benchmarking results for both audio-only and audio-visual piano transcription using the PianoVAM dataset and discuss additional potential applications.
Music Arena: Live Evaluation for Text-to-Music
Jul 28, 2025We present Music Arena, an open platform for scalable human preference evaluation of text-to-music (TTM) models. Soliciting human preferences via listening studies is the gold standard for evaluation in TTM, but these studies are expensive to conduct and difficult to compare, as study protocols may differ across systems. Moreover, human preferences might help researchers align their TTM systems or improve automatic evaluation metrics, but an open and renewable source of preferences does not currently exist. We aim to fill these gaps by offering *live* evaluation for TTM. In Music Arena, real-world users input text prompts of their choosing and compare outputs from two TTM systems, and their preferences are used to compile a leaderboard. While Music Arena follows recent evaluation trends in other AI domains, we also design it with key features tailored to music: an LLM-based routing system to navigate the heterogeneous type signatures of TTM systems, and the collection of *detailed* preferences including listening data and natural language feedback. We also propose a rolling data release policy with user privacy guarantees, providing a renewable source of preference data and increasing platform transparency. Through its standardized evaluation protocol, transparent data access policies, and music-specific features, Music Arena not only addresses key challenges in the TTM ecosystem but also demonstrates how live evaluation can be thoughtfully adapted to unique characteristics of specific AI domains. Music Arena is available at: https://music-arena.org
NeoLightning: A Modern Reimagination of Gesture-Based Sound Design
May 15, 2025



This paper introduces NeoLightning, a modern reinterpretation of the Buchla Lightning. NeoLightning preserves the innovative spirit of Don Buchla's "Buchla Lightning" (introduced in the 1990s) while making its gesture-based interaction accessible to contemporary users. While the original Buchla Lightning and many other historical instruments were groundbreaking in their time, they are now largely unsupported, limiting user interaction to indirect experiences. To address this, NeoLightning leverages MediaPipe for deep learning-based gesture recognition and employs Max/MSP and Processing for real-time multimedia processing. The redesigned system offers precise, low-latency gesture recognition and immersive 3D interaction. By merging the creative spirit of the original Lightning with modern advancements, NeoLightning redefines gesture-based musical interaction, expanding possibilities for expressive performance and interactive sound design.
Towards Robust Transcription: Exploring Noise Injection Strategies for Training Data Augmentation
Oct 18, 2024


Recent advancements in Automatic Piano Transcription (APT) have significantly improved system performance, but the impact of noisy environments on the system performance remains largely unexplored. This study investigates the impact of white noise at various Signal-to-Noise Ratio (SNR) levels on state-of-the-art APT models and evaluates the performance of the Onsets and Frames model when trained on noise-augmented data. We hope this research provides valuable insights as preliminary work toward developing transcription models that maintain consistent performance across a range of acoustic conditions.
A Study on the Efficient Product Search Service for the Damaged Image Information
Nov 14, 2021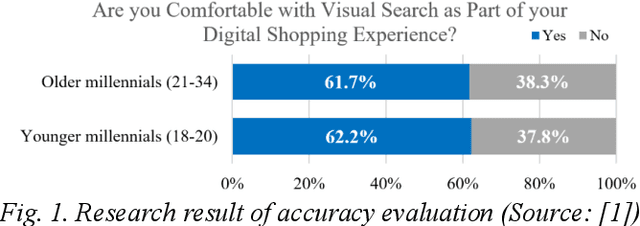
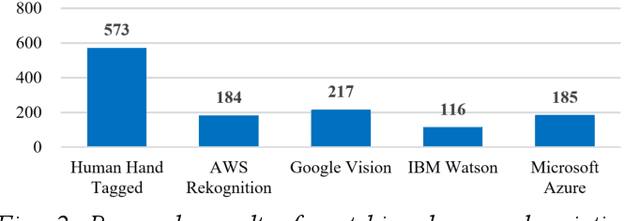
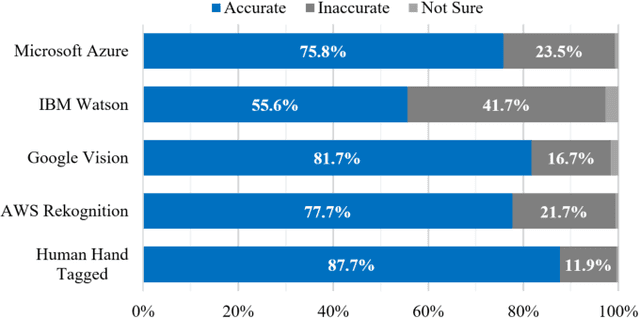

With the development of Information and Communication Technologies and the dissemination of smartphones, especially now that image search is possible through the internet, e-commerce markets are more activating purchasing services for a wide variety of products. However, it often happens that the image of the desired product is impaired and that the search engine does not recognize it properly. The idea of this study is to help search for products through image restoration using an image pre-processing and image inpainting algorithm for damaged images. It helps users easily purchase the items they want by providing a more accurate image search system. Besides, the system has the advantage of efficiently showing information by category, so that enables efficient sales of registered information.
Multi-level Distance Regularization for Deep Metric Learning
Feb 08, 2021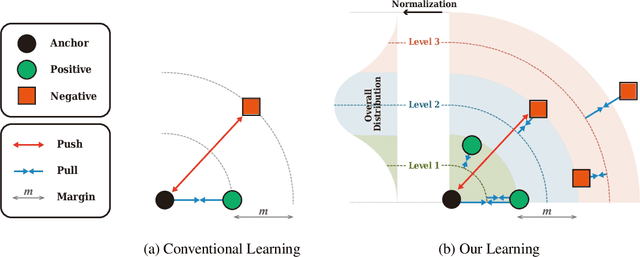
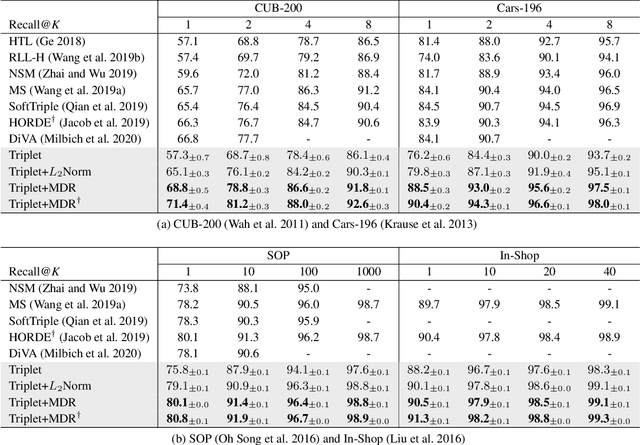
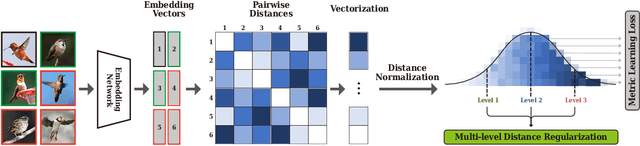
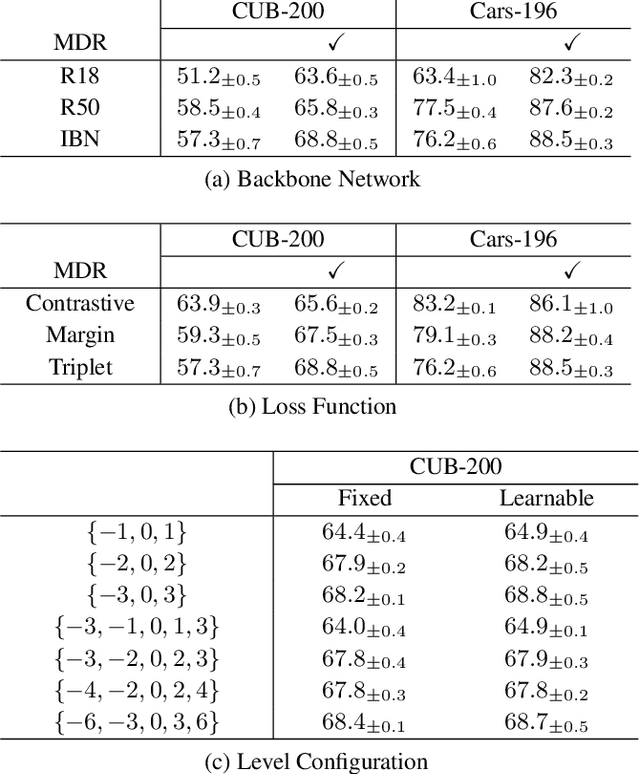
We propose a novel distance-based regularization method for deep metric learning called Multi-level Distance Regularization (MDR). MDR explicitly disturbs a learning procedure by regularizing pairwise distances between embedding vectors into multiple levels that represents a degree of similarity between a pair. In the training stage, the model is trained with both MDR and an existing loss function of deep metric learning, simultaneously; the two losses interfere with the objective of each other, and it makes the learning process difficult. Moreover, MDR prevents some examples from being ignored or overly influenced in the learning process. These allow the parameters of the embedding network to be settle on a local optima with better generalization. Without bells and whistles, MDR with simple Triplet loss achieves the-state-of-the-art performance in various benchmark datasets: CUB-200-2011, Cars-196, Stanford Online Products, and In-Shop Clothes Retrieval. We extensively perform ablation studies on its behaviors to show the effectiveness of MDR. By easily adopting our MDR, the previous approaches can be improved in performance and generalization ability.
Suppressing Spoof-irrelevant Factors for Domain-agnostic Face Anti-spoofing
Dec 02, 2020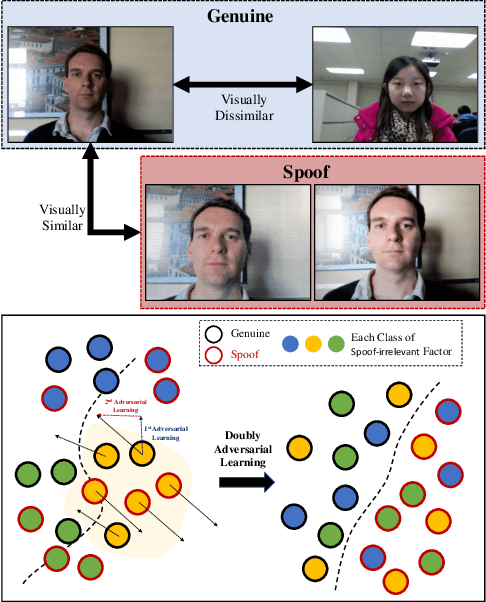
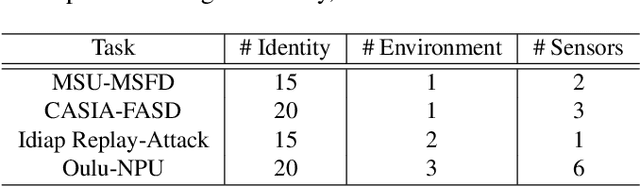
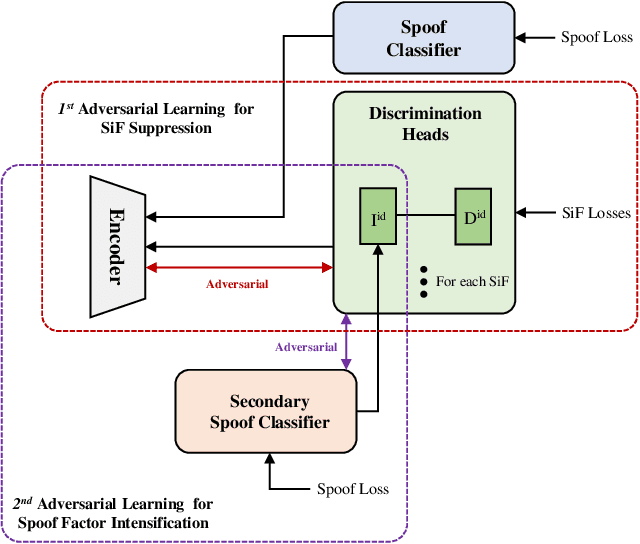
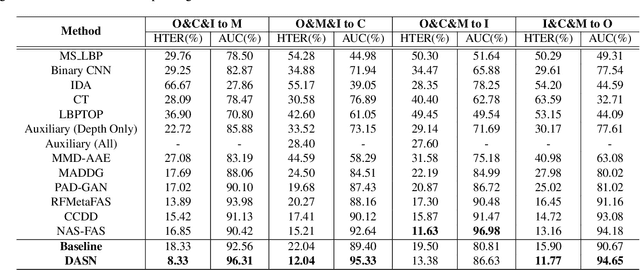
Face anti-spoofing aims to prevent false authentications of face recognition systems by distinguishing whether an image is originated from a human face or a spoof medium. We propose a novel method called Doubly Adversarial Suppression Network (DASN) for domain-agnostic face anti-spoofing; DASN improves the generalization ability to unseen domains by learning to effectively suppress spoof-irrelevant factors (SiFs) (e.g., camera sensors, illuminations). To achieve our goal, we introduce two types of adversarial learning schemes. In the first adversarial learning scheme, multiple SiFs are suppressed by deploying multiple discrimination heads that are trained against an encoder. In the second adversarial learning scheme, each of the discrimination heads is also adversarially trained to suppress a spoof factor, and the group of the secondary spoof classifier and the encoder aims to intensify the spoof factor by overcoming the suppression. We evaluate the proposed method on four public benchmark datasets, and achieve remarkable evaluation results. The results demonstrate the effectiveness of the proposed method.
BroadFace: Looking at Tens of Thousands of People at Once for Face Recognition
Aug 15, 2020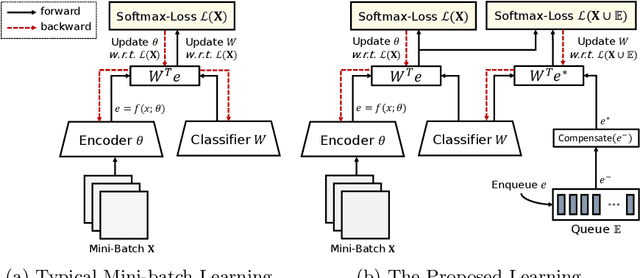
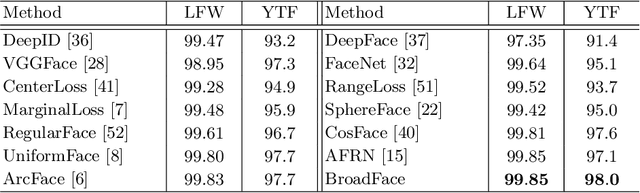
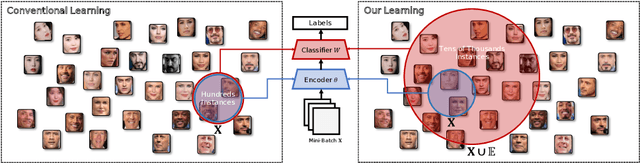
The datasets of face recognition contain an enormous number of identities and instances. However, conventional methods have difficulty in reflecting the entire distribution of the datasets because a mini-batch of small size contains only a small portion of all identities. To overcome this difficulty, we propose a novel method called BroadFace, which is a learning process to consider a massive set of identities, comprehensively. In BroadFace, a linear classifier learns optimal decision boundaries among identities from a large number of embedding vectors accumulated over past iterations. By referring more instances at once, the optimality of the classifier is naturally increased on the entire datasets. Thus, the encoder is also globally optimized by referring the weight matrix of the classifier. Moreover, we propose a novel compensation method to increase the number of referenced instances in the training stage. BroadFace can be easily applied on many existing methods to accelerate a learning process and obtain a significant improvement in accuracy without extra computational burden at inference stage. We perform extensive ablation studies and experiments on various datasets to show the effectiveness of BroadFace, and also empirically prove the validity of our compensation method. BroadFace achieves the state-of-the-art results with significant improvements on nine datasets in 1:1 face verification and 1:N face identification tasks, and is also effective in image retrieval.
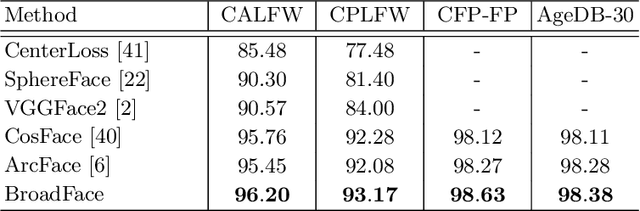
GroupFace: Learning Latent Groups and Constructing Group-based Representations for Face Recognition
May 25, 2020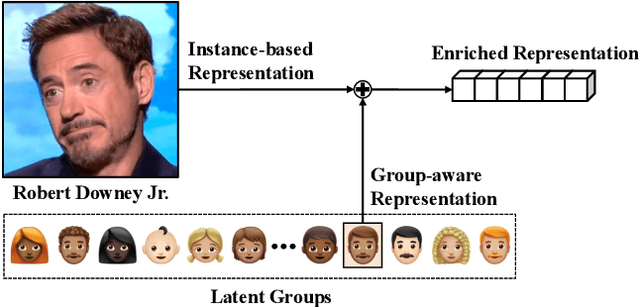
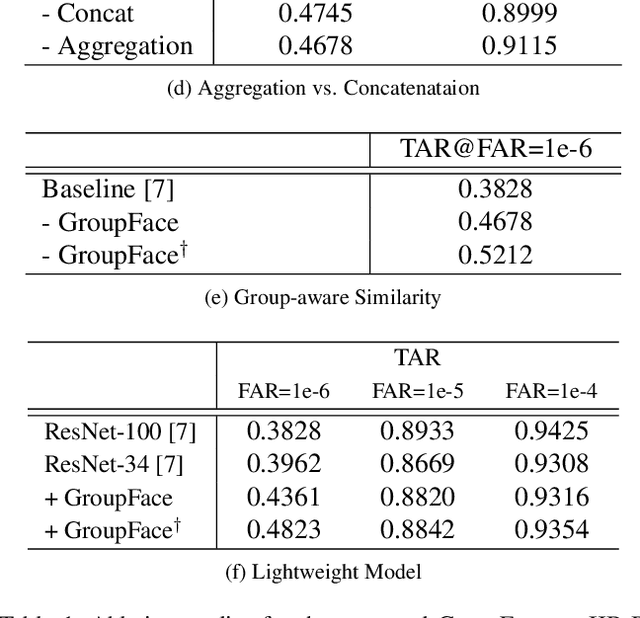
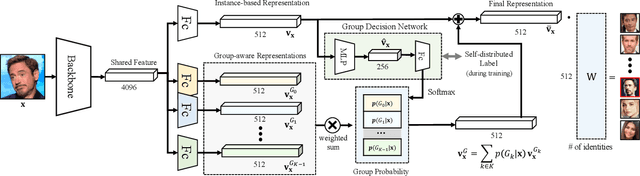
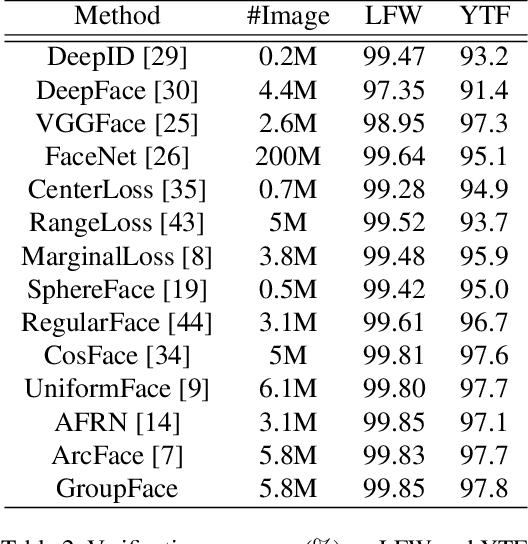
In the field of face recognition, a model learns to distinguish millions of face images with fewer dimensional embedding features, and such vast information may not be properly encoded in the conventional model with a single branch. We propose a novel face-recognition-specialized architecture called GroupFace that utilizes multiple group-aware representations, simultaneously, to improve the quality of the embedding feature. The proposed method provides self-distributed labels that balance the number of samples belonging to each group without additional human annotations, and learns the group-aware representations that can narrow down the search space of the target identity. We prove the effectiveness of the proposed method by showing extensive ablation studies and visualizations. All the components of the proposed method can be trained in an end-to-end manner with a marginal increase of computational complexity. Finally, the proposed method achieves the state-of-the-art results with significant improvements in 1:1 face verification and 1:N face identification tasks on the following public datasets: LFW, YTF, CALFW, CPLFW, CFP, AgeDB-30, MegaFace, IJB-B and IJB-C.