 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGroupFace: Learning Latent Groups and Constructing Group-based Representations for Face Recognition
May 25, 2020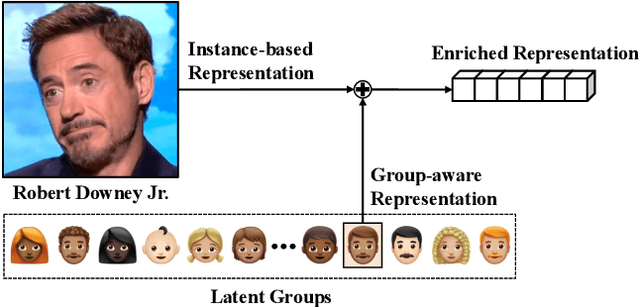
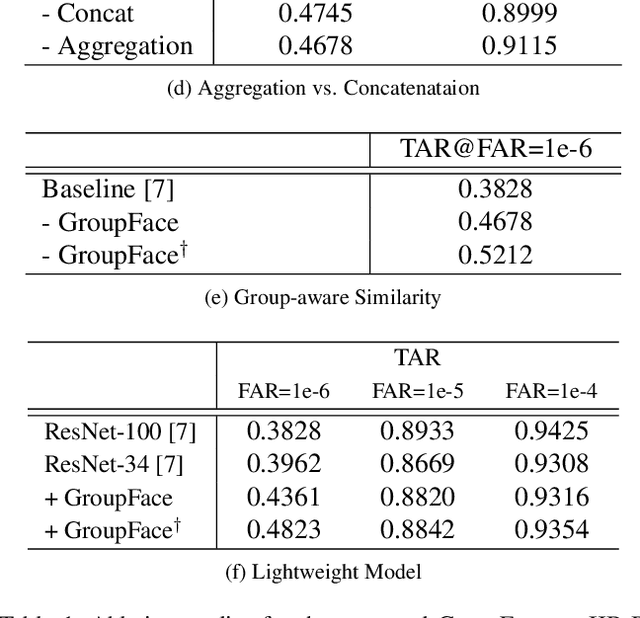
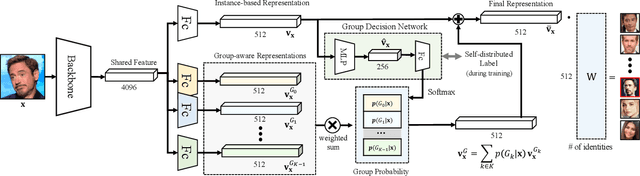
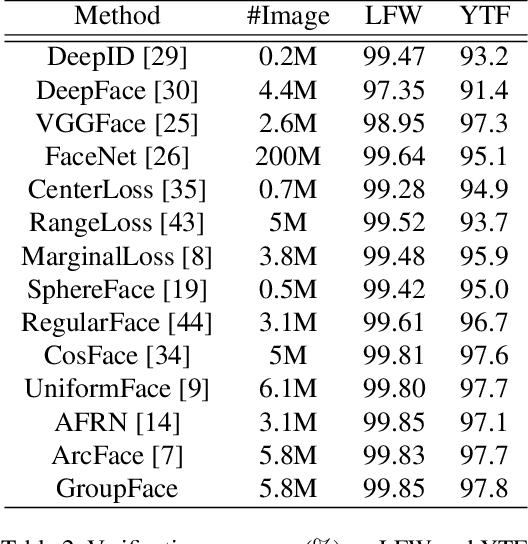
In the field of face recognition, a model learns to distinguish millions of face images with fewer dimensional embedding features, and such vast information may not be properly encoded in the conventional model with a single branch. We propose a novel face-recognition-specialized architecture called GroupFace that utilizes multiple group-aware representations, simultaneously, to improve the quality of the embedding feature. The proposed method provides self-distributed labels that balance the number of samples belonging to each group without additional human annotations, and learns the group-aware representations that can narrow down the search space of the target identity. We prove the effectiveness of the proposed method by showing extensive ablation studies and visualizations. All the components of the proposed method can be trained in an end-to-end manner with a marginal increase of computational complexity. Finally, the proposed method achieves the state-of-the-art results with significant improvements in 1:1 face verification and 1:N face identification tasks on the following public datasets: LFW, YTF, CALFW, CPLFW, CFP, AgeDB-30, MegaFace, IJB-B and IJB-C.
Uncorrelated Feature Encoding for Faster Image Style Transfer
Jul 04, 2018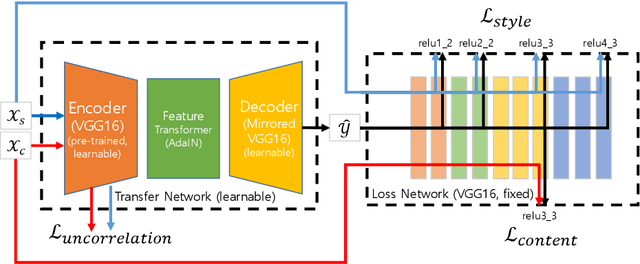

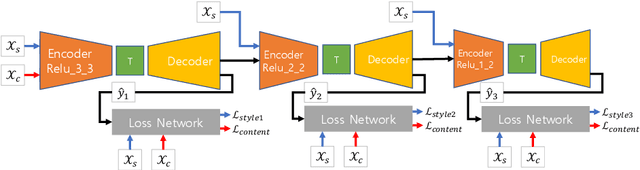

Recent fast style transfer methods use a pre-trained convolutional neural network as a feature encoder and a perceptual loss network. Although the pre-trained network is used to generate responses of receptive fields effective for representing style and content of image, it is not optimized for image style transfer but rather for image classification. Furthermore, it also requires a time-consuming and correlation-considering feature alignment process for image style transfer because of its inter-channel correlation. In this paper, we propose an end-to-end learning method which optimizes an encoder/decoder network for the purpose of style transfer as well as relieves the feature alignment complexity from considering inter-channel correlation. We used uncorrelation loss, i.e., the total correlation coefficient between the responses of different encoder channels, with style and content losses for training style transfer network. This makes the encoder network to be trained to generate inter-channel uncorrelated features and to be optimized for the task of image style transfer which maintained the quality of image style only with a light-weighted and correlation-unaware feature alignment process. Moreover, our method drastically reduced redundant channels of the encoded feature and this resulted in the efficient size of structure of network and faster forward processing speed. Our method can also be applied to cascade network scheme for multiple scaled style transferring and allows user-control of style strength by using a content-style trade-off parameter.
Face Alignment Robust to Pose, Expressions and Occlusions
Jul 19, 2017
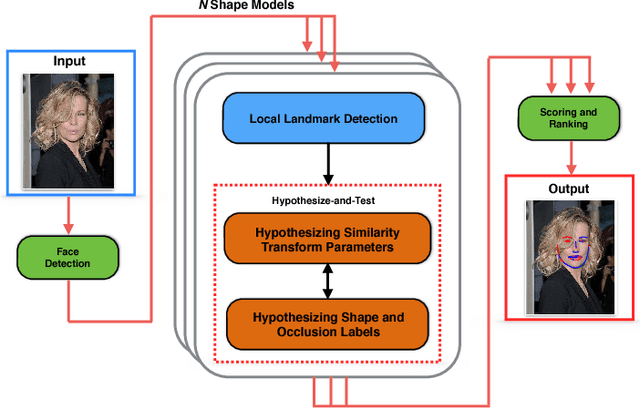
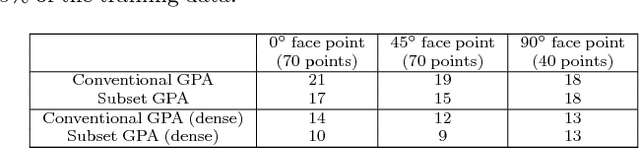
We propose an Ensemble of Robust Constrained Local Models for alignment of faces in the presence of significant occlusions and of any unknown pose and expression. To account for partial occlusions we introduce, Robust Constrained Local Models, that comprises of a deformable shape and local landmark appearance model and reasons over binary occlusion labels. Our occlusion reasoning proceeds by a hypothesize-and-test search over occlusion labels. Hypotheses are generated by Constrained Local Model based shape fitting over randomly sampled subsets of landmark detector responses and are evaluated by the quality of face alignment. To span the entire range of facial pose and expression variations we adopt an ensemble of independent Robust Constrained Local Models to search over a discretized representation of pose and expression. We perform extensive evaluation on a large number of face images, both occluded and unoccluded. We find that our face alignment system trained entirely on facial images captured "in-the-lab" exhibits a high degree of generalization to facial images captured "in-the-wild". Our results are accurate and stable over a wide spectrum of occlusions, pose and expression variations resulting in excellent performance on many real-world face datasets.