 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSchrodinger Audio-Visual Editor: Object-Level Audiovisual Removal
Dec 14, 2025Joint editing of audio and visual content is crucial for precise and controllable content creation. This new task poses challenges due to the limitations of paired audio-visual data before and after targeted edits, and the heterogeneity across modalities. To address the data and modeling challenges in joint audio-visual editing, we introduce SAVEBench, a paired audiovisual dataset with text and mask conditions to enable object-grounded source-to-target learning. With SAVEBench, we train the Schrodinger Audio-Visual Editor (SAVE), an end-to-end flow-matching model that edits audio and video in parallel while keeping them aligned throughout processing. SAVE incorporates a Schrodinger Bridge that learns a direct transport from source to target audiovisual mixtures. Our evaluation demonstrates that the proposed SAVE model is able to remove the target objects in audio and visual content while preserving the remaining content, with stronger temporal synchronization and audiovisual semantic correspondence compared with pairwise combinations of an audio editor and a video editor.
FoleyBench: A Benchmark For Video-to-Audio Models
Nov 17, 2025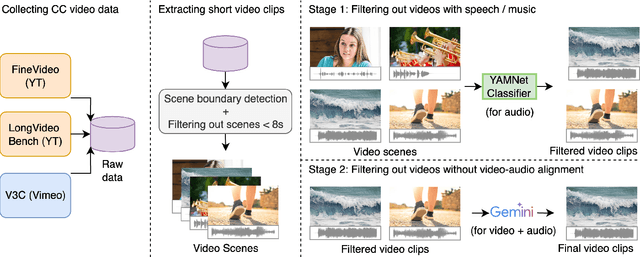
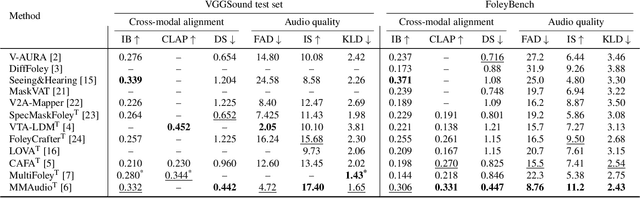
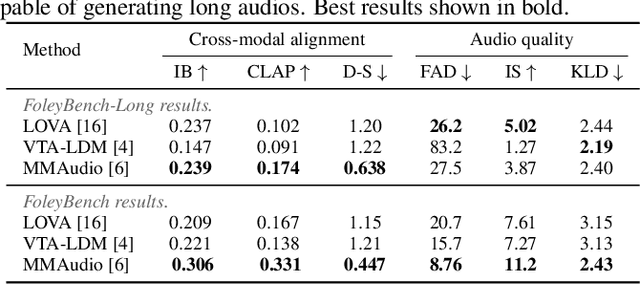

Video-to-audio generation (V2A) is of increasing importance in domains such as film post-production, AR/VR, and sound design, particularly for the creation of Foley sound effects synchronized with on-screen actions. Foley requires generating audio that is both semantically aligned with visible events and temporally aligned with their timing. Yet, there is a mismatch between evaluation and downstream applications due to the absence of a benchmark tailored to Foley-style scenarios. We find that 74% of videos from past evaluation datasets have poor audio-visual correspondence. Moreover, they are dominated by speech and music, domains that lie outside the use case for Foley. To address this gap, we introduce FoleyBench, the first large-scale benchmark explicitly designed for Foley-style V2A evaluation. FoleyBench contains 5,000 (video, ground-truth audio, text caption) triplets, each featuring visible sound sources with audio causally tied to on-screen events. The dataset is built using an automated, scalable pipeline applied to in-the-wild internet videos from YouTube-based and Vimeo-based sources. Compared to past datasets, we show that videos from FoleyBench have stronger coverage of sound categories from a taxonomy specifically designed for Foley sound. Each clip is further labeled with metadata capturing source complexity, UCS/AudioSet category, and video length, enabling fine-grained analysis of model performance and failure modes. We benchmark several state-of-the-art V2A models, evaluating them on audio quality, audio-video alignment, temporal synchronization, and audio-text consistency. Samples are available at: https://gclef-cmu.org/foleybench
TalkCuts: A Large-Scale Dataset for Multi-Shot Human Speech Video Generation
Oct 08, 2025In this work, we present TalkCuts, a large-scale dataset designed to facilitate the study of multi-shot human speech video generation. Unlike existing datasets that focus on single-shot, static viewpoints, TalkCuts offers 164k clips totaling over 500 hours of high-quality human speech videos with diverse camera shots, including close-up, half-body, and full-body views. The dataset includes detailed textual descriptions, 2D keypoints and 3D SMPL-X motion annotations, covering over 10k identities, enabling multimodal learning and evaluation. As a first attempt to showcase the value of the dataset, we present Orator, an LLM-guided multi-modal generation framework as a simple baseline, where the language model functions as a multi-faceted director, orchestrating detailed specifications for camera transitions, speaker gesticulations, and vocal modulation. This architecture enables the synthesis of coherent long-form videos through our integrated multi-modal video generation module. Extensive experiments in both pose-guided and audio-driven settings show that training on TalkCuts significantly enhances the cinematographic coherence and visual appeal of generated multi-shot speech videos. We believe TalkCuts provides a strong foundation for future work in controllable, multi-shot speech video generation and broader multimodal learning.
SoundReactor: Frame-level Online Video-to-Audio Generation
Oct 02, 2025



Prevailing Video-to-Audio (V2A) generation models operate offline, assuming an entire video sequence or chunks of frames are available beforehand. This critically limits their use in interactive applications such as live content creation and emerging generative world models. To address this gap, we introduce the novel task of frame-level online V2A generation, where a model autoregressively generates audio from video without access to future video frames. Furthermore, we propose SoundReactor, which, to the best of our knowledge, is the first simple yet effective framework explicitly tailored for this task. Our design enforces end-to-end causality and targets low per-frame latency with audio-visual synchronization. Our model's backbone is a decoder-only causal transformer over continuous audio latents. For vision conditioning, it leverages grid (patch) features extracted from the smallest variant of the DINOv2 vision encoder, which are aggregated into a single token per frame to maintain end-to-end causality and efficiency. The model is trained through a diffusion pre-training followed by consistency fine-tuning to accelerate the diffusion head decoding. On a benchmark of diverse gameplay videos from AAA titles, our model successfully generates semantically and temporally aligned, high-quality full-band stereo audio, validated by both objective and human evaluations. Furthermore, our model achieves low per-frame waveform-level latency (26.3ms with the head NFE=1, 31.5ms with NFE=4) on 30FPS, 480p videos using a single H100. Demo samples are available at https://koichi-saito-sony.github.io/soundreactor/.
Music Arena: Live Evaluation for Text-to-Music
Jul 28, 2025We present Music Arena, an open platform for scalable human preference evaluation of text-to-music (TTM) models. Soliciting human preferences via listening studies is the gold standard for evaluation in TTM, but these studies are expensive to conduct and difficult to compare, as study protocols may differ across systems. Moreover, human preferences might help researchers align their TTM systems or improve automatic evaluation metrics, but an open and renewable source of preferences does not currently exist. We aim to fill these gaps by offering *live* evaluation for TTM. In Music Arena, real-world users input text prompts of their choosing and compare outputs from two TTM systems, and their preferences are used to compile a leaderboard. While Music Arena follows recent evaluation trends in other AI domains, we also design it with key features tailored to music: an LLM-based routing system to navigate the heterogeneous type signatures of TTM systems, and the collection of *detailed* preferences including listening data and natural language feedback. We also propose a rolling data release policy with user privacy guarantees, providing a renewable source of preference data and increasing platform transparency. Through its standardized evaluation protocol, transparent data access policies, and music-specific features, Music Arena not only addresses key challenges in the TTM ecosystem but also demonstrates how live evaluation can be thoughtfully adapted to unique characteristics of specific AI domains. Music Arena is available at: https://music-arena.org
Schrödinger Bridge Consistency Trajectory Models for Speech Enhancement
Jul 16, 2025Speech enhancement (SE) utilizing diffusion models is a promising technology that improves speech quality in noisy speech data. Furthermore, the Schr\"odinger bridge (SB) has recently been used in diffusion-based SE to improve speech quality by resolving a mismatch between the endpoint of the forward process and the starting point of the reverse process. However, the SB still exhibits slow inference owing to the necessity of a large number of function evaluations (NFE) for inference to obtain high-quality results. While Consistency Models (CMs) address this issue by employing consistency training that uses distillation from pretrained models in the field of image generation, it does not improve generation quality when the number of steps increases. As a solution to this problem, Consistency Trajectory Models (CTMs) not only accelerate inference speed but also maintain a favorable trade-off between quality and speed. Furthermore, SoundCTM demonstrates the applicability of CTM techniques to the field of sound generation. In this paper, we present Schr\"odinger bridge Consistency Trajectory Models (SBCTM) by applying the CTM's technique to the Schr\"odinger bridge for SE. Additionally, we introduce a novel auxiliary loss, including a perceptual loss, into the original CTM's training framework. As a result, SBCTM achieves an approximately 16x improvement in the real-time factor (RTF) compared to the conventional Schr\"odinger bridge for SE. Furthermore, the favorable trade-off between quality and speed in SBCTM allows for time-efficient inference by limiting multi-step refinement to cases where 1-step inference is insufficient. Our code, pretrained models, and audio samples are available at https://github.com/sony/sbctm/.
Dyadic Mamba: Long-term Dyadic Human Motion Synthesis
May 14, 2025Generating realistic dyadic human motion from text descriptions presents significant challenges, particularly for extended interactions that exceed typical training sequence lengths. While recent transformer-based approaches have shown promising results for short-term dyadic motion synthesis, they struggle with longer sequences due to inherent limitations in positional encoding schemes. In this paper, we introduce Dyadic Mamba, a novel approach that leverages State-Space Models (SSMs) to generate high-quality dyadic human motion of arbitrary length. Our method employs a simple yet effective architecture that facilitates information flow between individual motion sequences through concatenation, eliminating the need for complex cross-attention mechanisms. We demonstrate that Dyadic Mamba achieves competitive performance on standard short-term benchmarks while significantly outperforming transformer-based approaches on longer sequences. Additionally, we propose a new benchmark for evaluating long-term motion synthesis quality, providing a standardized framework for future research. Our results demonstrate that SSM-based architectures offer a promising direction for addressing the challenging task of long-term dyadic human motion synthesis from text descriptions.
Aligning Text-to-Music Evaluation with Human Preferences
Mar 20, 2025Despite significant recent advances in generative acoustic text-to-music (TTM) modeling, robust evaluation of these models lags behind, relying in particular on the popular Fr\'echet Audio Distance (FAD). In this work, we rigorously study the design space of reference-based divergence metrics for evaluating TTM models through (1) designing four synthetic meta-evaluations to measure sensitivity to particular musical desiderata, and (2) collecting and evaluating on MusicPrefs, the first open-source dataset of human preferences for TTM systems. We find that not only is the standard FAD setup inconsistent on both synthetic and human preference data, but that nearly all existing metrics fail to effectively capture desiderata, and are only weakly correlated with human perception. We propose a new metric, the MAUVE Audio Divergence (MAD), computed on representations from a self-supervised audio embedding model. We find that this metric effectively captures diverse musical desiderata (average rank correlation 0.84 for MAD vs. 0.49 for FAD and also correlates more strongly with MusicPrefs (0.62 vs. 0.14).
VERSA: A Versatile Evaluation Toolkit for Speech, Audio, and Music
Dec 23, 2024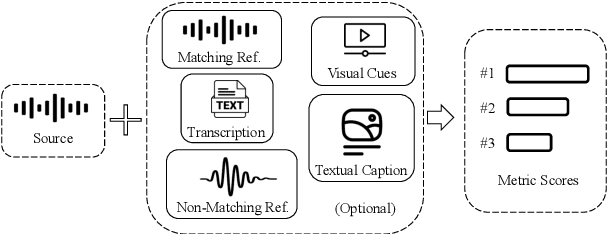
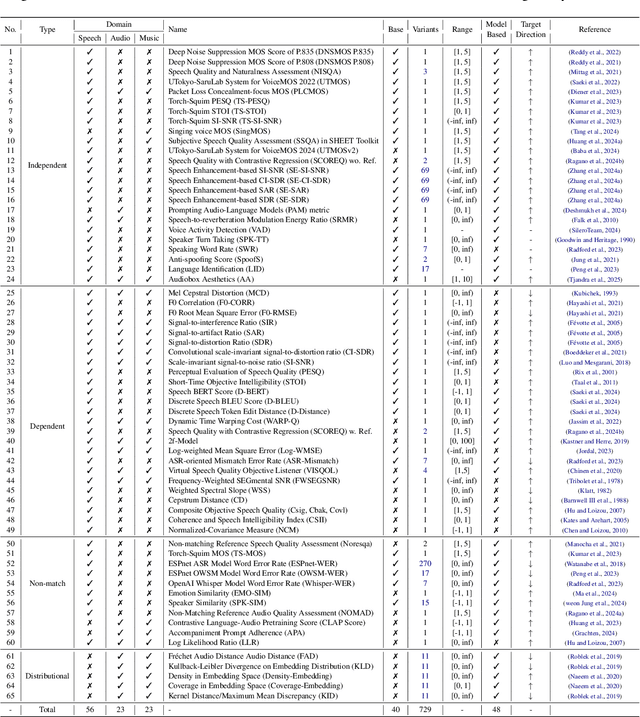

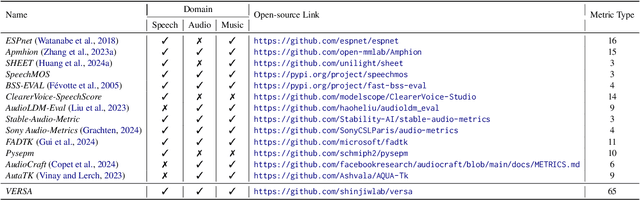
In this work, we introduce VERSA, a unified and standardized evaluation toolkit designed for various speech, audio, and music signals. The toolkit features a Pythonic interface with flexible configuration and dependency control, making it user-friendly and efficient. With full installation, VERSA offers 63 metrics with 711 metric variations based on different configurations. These metrics encompass evaluations utilizing diverse external resources, including matching and non-matching reference audio, text transcriptions, and text captions. As a lightweight yet comprehensive toolkit, VERSA is versatile to support the evaluation of a wide range of downstream scenarios. To demonstrate its capabilities, this work highlights example use cases for VERSA, including audio coding, speech synthesis, speech enhancement, singing synthesis, and music generation. The toolkit is available at https://github.com/shinjiwlab/versa.
DisMix: Disentangling Mixtures of Musical Instruments for Source-level Pitch and Timbre Manipulation
Aug 20, 2024



Existing work on pitch and timbre disentanglement has been mostly focused on single-instrument music audio, excluding the cases where multiple instruments are presented. To fill the gap, we propose DisMix, a generative framework in which the pitch and timbre representations act as modular building blocks for constructing the melody and instrument of a source, and the collection of which forms a set of per-instrument latent representations underlying the observed mixture. By manipulating the representations, our model samples mixtures with novel combinations of pitch and timbre of the constituent instruments. We can jointly learn the disentangled pitch-timbre representations and a latent diffusion transformer that reconstructs the mixture conditioned on the set of source-level representations. We evaluate the model using both a simple dataset of isolated chords and a realistic four-part chorales in the style of J.S. Bach, identify the key components for the success of disentanglement, and demonstrate the application of mixture transformation based on source-level attribute manipulation.