 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeANCHOR: Autoregressive Non-intrusive Chunk-Ordered Refinement for Joint Multi-Resolution Speech Quality Modeling
Jun 08, 2026While speech quality is typically assessed on complete utterances, streaming and generative systems require incremental estimation from partial audio. Existing predictors assume full context, degrading on prefix-constrained inputs. Extending ARECHO, we propose ANCHOR, reformulating incremental assessment as a multi-resolution autoregressive task. It models chunk- and utterance-level quality within a single decoder using dual-resolution tokens and a resolution-aware hierarchy for coarse-to-fine refinement. Experiments show substantial robustness under partial input, including a 48% PLCMOS error reduction on 2-second prefixes. Convergence analysis reveals a 4-6 s effective perceptual context horizon. A stress test further isolates structured extrapolation biases under localized corruption. Results demonstrate that hierarchical supervision improves incremental prediction and elucidates how perceptual quality accumulates over time.
Shortcut Learning in Binary Classifier Black Boxes: Applications to Voice Anti-Spoofing and Biometrics
Jan 25, 2026The widespread adoption of deep-learning models in data-driven applications has drawn attention to the potential risks associated with biased datasets and models. Neglected or hidden biases within datasets and models can lead to unexpected results. This study addresses the challenges of dataset bias and explores ``shortcut learning'' or ``Clever Hans effect'' in binary classifiers. We propose a novel framework for analyzing the black-box classifiers and for examining the impact of both training and test data on classifier scores. Our framework incorporates intervention and observational perspectives, employing a linear mixed-effects model for post-hoc analysis. By evaluating classifier performance beyond error rates, we aim to provide insights into biased datasets and offer a comprehensive understanding of their influence on classifier behavior. The effectiveness of our approach is demonstrated through experiments on audio anti-spoofing and speaker verification tasks using both statistical models and deep neural networks. The insights gained from this study have broader implications for tackling biases in other domains and advancing the field of explainable artificial intelligence.
The CMU-AIST submission for the ICME 2025 Audio Encoder Challenge
Jan 22, 2026This technical report describes our submission to the ICME 2025 audio encoder challenge. Our submitted system is built on BEATs, a masked speech token prediction based audio encoder. We extend the BEATs model using 74,000 hours of data derived from various speech, music, and sound corpora and scale its architecture upto 300 million parameters. We experiment with speech-heavy and balanced pre-training mixtures to study the impact of different domains on final performance. Our submitted system consists of an ensemble of the Dasheng 1.2 billion model with two custom scaled-up BEATs models trained on the aforementioned pre-training data mixtures. We also propose a simple ensembling technique that retains the best capabilities of constituent models and surpasses both the baseline and Dasheng 1.2B. For open science, we publicly release our trained checkpoints via huggingface at https://huggingface.co/shikhar7ssu/OpenBEATs-ICME-SOUND and https://huggingface.co/shikhar7ssu/OpenBEATs-ICME.
Token-based Attractors and Cross-attention in Spoof Diarization
Sep 16, 2025Spoof diarization identifies ``what spoofed when" in a given speech by temporally locating spoofed regions and determining their manipulation techniques. As a first step toward this task, prior work proposed a two-branch model for localization and spoof type clustering, which laid the foundation for spoof diarization. However, its simple structure limits the ability to capture complex spoofing patterns and lacks explicit reference points for distinguishing between bona fide and various spoofing types. To address these limitations, our approach introduces learnable tokens where each token represents acoustic features of bona fide and spoofed speech. These attractors interact with frame-level embeddings to extract discriminative representations, improving separation between genuine and generated speech. Vast experiments on PartialSpoof dataset consistently demonstrate that our approach outperforms existing methods in bona fide detection and spoofing method clustering.
WildSpoof Challenge Evaluation Plan
Aug 23, 2025The WildSpoof Challenge aims to advance the use of in-the-wild data in two intertwined speech processing tasks. It consists of two parallel tracks: (1) Text-to-Speech (TTS) synthesis for generating spoofed speech, and (2) Spoofing-robust Automatic Speaker Verification (SASV) for detecting spoofed speech. While the organizers coordinate both tracks and define the data protocols, participants treat them as separate and independent tasks. The primary objectives of the challenge are: (i) to promote the use of in-the-wild data for both TTS and SASV, moving beyond conventional clean and controlled datasets and considering real-world scenarios; and (ii) to encourage interdisciplinary collaboration between the spoofing generation (TTS) and spoofing detection (SASV) communities, thereby fostering the development of more integrated, robust, and realistic systems.
Geolocation-Aware Robust Spoken Language Identification
Aug 23, 2025



While Self-supervised Learning (SSL) has significantly improved Spoken Language Identification (LID), existing models often struggle to consistently classify dialects and accents of the same language as a unified class. To address this challenge, we propose geolocation-aware LID, a novel approach that incorporates language-level geolocation information into the SSL-based LID model. Specifically, we introduce geolocation prediction as an auxiliary task and inject the predicted vectors into intermediate representations as conditioning signals. This explicit conditioning encourages the model to learn more unified representations for dialectal and accented variations. Experiments across six multilingual datasets demonstrate that our approach improves robustness to intra-language variations and unseen domains, achieving new state-of-the-art accuracy on FLEURS (97.7%) and 9.7% relative improvement on ML-SUPERB 2.0 dialect set.
OpenBEATs: A Fully Open-Source General-Purpose Audio Encoder
Jul 18, 2025



Masked token prediction has emerged as a powerful pre-training objective across language, vision, and speech, offering the potential to unify these diverse modalities through a single pre-training task. However, its application for general audio understanding remains underexplored, with BEATs being the only notable example. BEATs has seen limited modifications due to the absence of open-source pre-training code. Furthermore, BEATs was trained only on AudioSet, restricting its broader downstream applicability. To address these gaps, we present OpenBEATs, an open-source framework that extends BEATs via multi-domain audio pre-training. We conduct comprehensive evaluations across six types of tasks, twenty five datasets, and three audio domains, including audio reasoning tasks such as audio question answering, entailment, and captioning. OpenBEATs achieves state-of-the-art performance on six bioacoustics datasets, two environmental sound datasets and five reasoning datasets, performing better than models exceeding a billion parameters at one-fourth their parameter size. These results demonstrate the effectiveness of multi-domain datasets and masked token prediction task to learn general-purpose audio representations. To promote further research and reproducibility, we release all pre-training and evaluation code, pretrained and fine-tuned checkpoints, and training logs at https://shikhar-s.github.io/OpenBEATs
ARECHO: Autoregressive Evaluation via Chain-Based Hypothesis Optimization for Speech Multi-Metric Estimation
May 30, 2025Speech signal analysis poses significant challenges, particularly in tasks such as speech quality evaluation and profiling, where the goal is to predict multiple perceptual and objective metrics. For instance, metrics like PESQ (Perceptual Evaluation of Speech Quality), STOI (Short-Time Objective Intelligibility), and MOS (Mean Opinion Score) each capture different aspects of speech quality. However, these metrics often have different scales, assumptions, and dependencies, making joint estimation non-trivial. To address these issues, we introduce ARECHO (Autoregressive Evaluation via Chain-based Hypothesis Optimization), a chain-based, versatile evaluation system for speech assessment grounded in autoregressive dependency modeling. ARECHO is distinguished by three key innovations: (1) a comprehensive speech information tokenization pipeline; (2) a dynamic classifier chain that explicitly captures inter-metric dependencies; and (3) a two-step confidence-oriented decoding algorithm that enhances inference reliability. Experiments demonstrate that ARECHO significantly outperforms the baseline framework across diverse evaluation scenarios, including enhanced speech analysis, speech generation evaluation, and noisy speech evaluation. Furthermore, its dynamic dependency modeling improves interpretability by capturing inter-metric relationships.
ASVspoof 5: Design, Collection and Validation of Resources for Spoofing, Deepfake, and Adversarial Attack Detection Using Crowdsourced Speech
Feb 13, 2025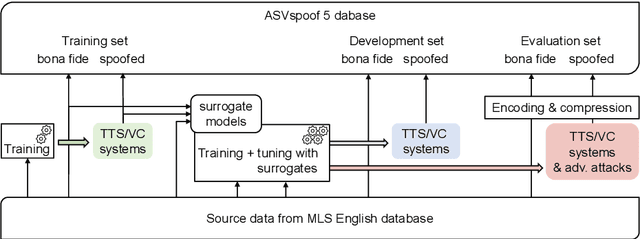

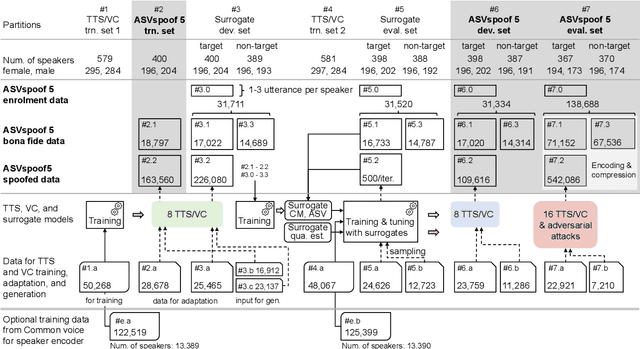
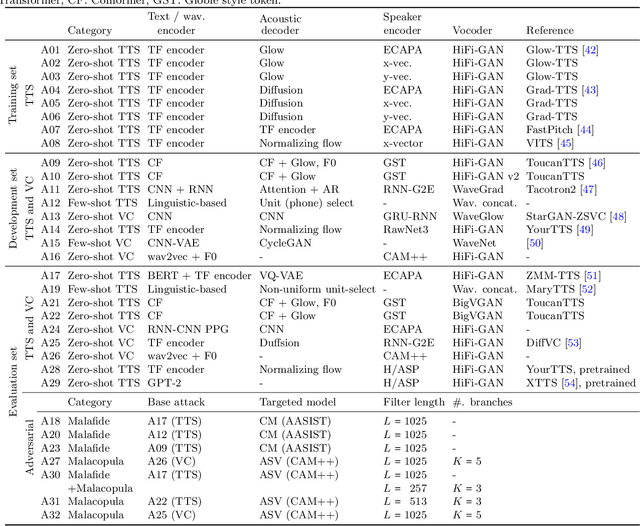
ASVspoof 5 is the fifth edition in a series of challenges which promote the study of speech spoofing and deepfake attacks as well as the design of detection solutions. We introduce the ASVspoof 5 database which is generated in crowdsourced fashion from data collected in diverse acoustic conditions (cf. studio-quality data for earlier ASVspoof databases) and from ~2,000 speakers (cf. ~100 earlier). The database contains attacks generated with 32 different algorithms, also crowdsourced, and optimised to varying degrees using new surrogate detection models. Among them are attacks generated with a mix of legacy and contemporary text-to-speech synthesis and voice conversion models, in addition to adversarial attacks which are incorporated for the first time. ASVspoof 5 protocols comprise seven speaker-disjoint partitions. They include two distinct partitions for the training of different sets of attack models, two more for the development and evaluation of surrogate detection models, and then three additional partitions which comprise the ASVspoof 5 training, development and evaluation sets. An auxiliary set of data collected from an additional 30k speakers can also be used to train speaker encoders for the implementation of attack algorithms. Also described herein is an experimental validation of the new ASVspoof 5 database using a set of automatic speaker verification and spoof/deepfake baseline detectors. With the exception of protocols and tools for the generation of spoofed/deepfake speech, the resources described in this paper, already used by participants of the ASVspoof 5 challenge in 2024, are now all freely available to the community.
Towards Explainable Spoofed Speech Attribution and Detection:a Probabilistic Approach for Characterizing Speech Synthesizer Components
Feb 07, 2025We propose an explainable probabilistic framework for characterizing spoofed speech by decomposing it into probabilistic attribute embeddings. Unlike raw high-dimensional countermeasure embeddings, which lack interpretability, the proposed probabilistic attribute embeddings aim to detect specific speech synthesizer components, represented through high-level attributes and their corresponding values. We use these probabilistic embeddings with four classifier back-ends to address two downstream tasks: spoofing detection and spoofing attack attribution. The former is the well-known bonafide-spoof detection task, whereas the latter seeks to identify the source method (generator) of a spoofed utterance. We additionally use Shapley values, a widely used technique in machine learning, to quantify the relative contribution of each attribute value to the decision-making process in each task. Results on the ASVspoof2019 dataset demonstrate the substantial role of duration and conversion modeling in spoofing detection; and waveform generation and speaker modeling in spoofing attack attribution. In the detection task, the probabilistic attribute embeddings achieve $99.7\%$ balanced accuracy and $0.22\%$ equal error rate (EER), closely matching the performance of raw embeddings ($99.9\%$ balanced accuracy and $0.22\%$ EER). Similarly, in the attribution task, our embeddings achieve $90.23\%$ balanced accuracy and $2.07\%$ EER, compared to $90.16\%$ and $2.11\%$ with raw embeddings. These results demonstrate that the proposed framework is both inherently explainable by design and capable of achieving performance comparable to raw CM embeddings.