 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Silence: Bias Analysis through Loss and Asymmetric Approach in Audio Anti-Spoofing
Paper and Code
Jun 25, 2024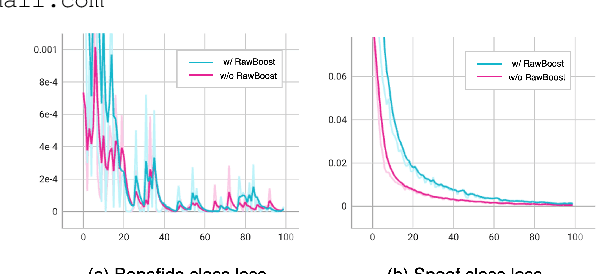


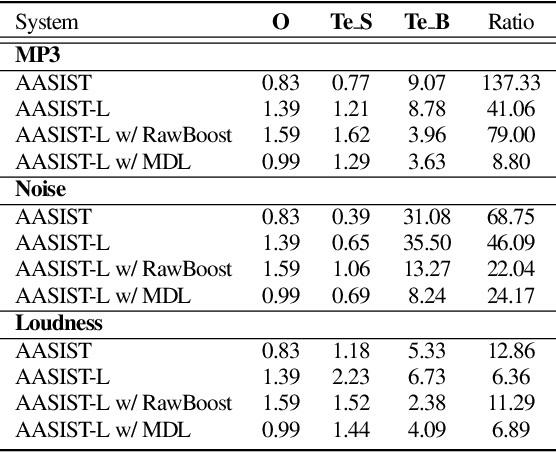
Current trends in audio anti-spoofing detection research strive to improve models' ability to generalize across unseen attacks by learning to identify a variety of spoofing artifacts. This emphasis has primarily focused on the spoof class. Recently, several studies have noted that the distribution of silence differs between the two classes, which can serve as a shortcut. In this paper, we extend class-wise interpretations beyond silence. We employ loss analysis and asymmetric methodologies to move away from traditional attack-focused and result-oriented evaluations towards a deeper examination of model behaviors. Our investigations highlight the significant differences in training dynamics between the two classes, emphasizing the need for future research to focus on robust modeling of the bonafide class.