 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-To-Speech Synthesis In The Wild
Sep 13, 2024Text-to-speech (TTS) systems are traditionally trained using modest databases of studio-quality, prompted or read speech collected in benign acoustic environments such as anechoic rooms. The recent literature nonetheless shows efforts to train TTS systems using data collected in the wild. While this approach allows for the use of massive quantities of natural speech, until now, there are no common datasets. We introduce the TTS In the Wild (TITW) dataset, the result of a fully automated pipeline, in this case, applied to the VoxCeleb1 dataset commonly used for speaker recognition. We further propose two training sets. TITW-Hard is derived from the transcription, segmentation, and selection of VoxCeleb1 source data. TITW-Easy is derived from the additional application of enhancement and additional data selection based on DNSMOS. We show that a number of recent TTS models can be trained successfully using TITW-Easy, but that it remains extremely challenging to produce similar results using TITW-Hard. Both the dataset and protocols are publicly available and support the benchmarking of TTS systems trained using TITW data.
Spontaneous speech synthesis with linguistic-speech consistency training using pseudo-filled pauses
Oct 18, 2022

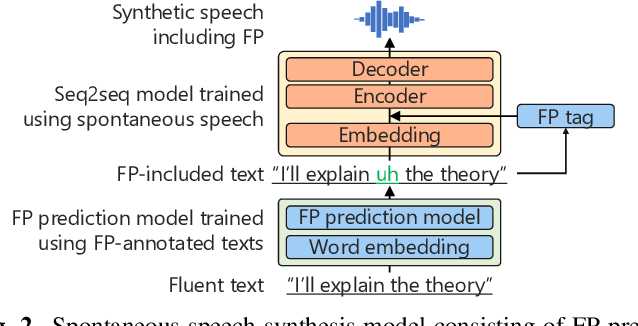
We propose a training method for spontaneous speech synthesis models that guarantees the consistency of linguistic parts of synthesized speech. Personalized spontaneous speech synthesis aims to reproduce the individuality of disfluency, such as filled pauses. Our prior model includes a filled-pause prediction model and synthesizes filled-pause-included speech from text without filled pauses. However, inserting the filled pauses degrades the quality of the linguistic parts of the synthesized speech. This might be because filled-pause insertion tendencies differ between training and inference, and the synthesis model cannot represent connections between filled pauses and surrounding phonemes in inference. We, therefore, developed a linguistic-speech consistency training that guarantees the consistency of linguistic parts of synthetic speech with and without filled pauses. The proposed consistency training utilizes not only ground-truth-filled pauses but also pseudo ones. Our experiments demonstrate that this method improves the naturalness of the synthetic linguistic speech and the entire predicted-filled-pause-included synthetic speech.
Empirical Study Incorporating Linguistic Knowledge on Filled Pauses for Personalized Spontaneous Speech Synthesis
Oct 14, 2022
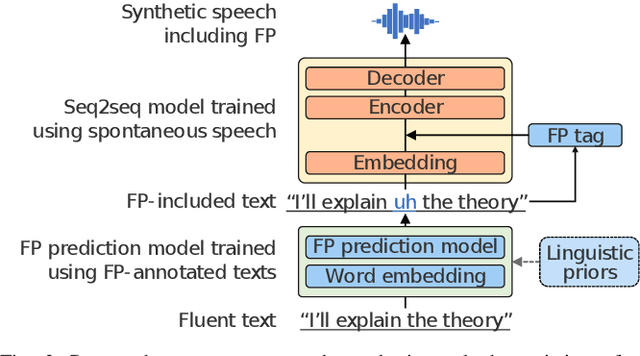
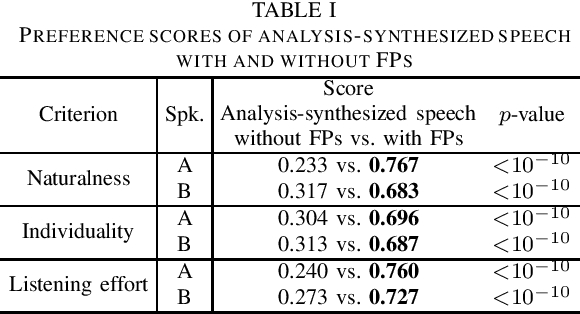
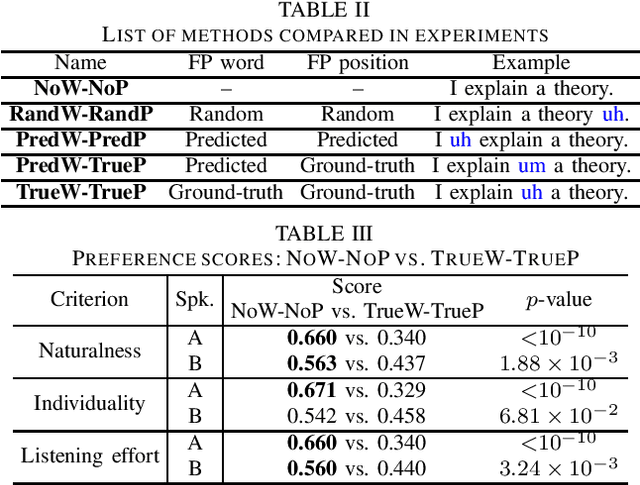
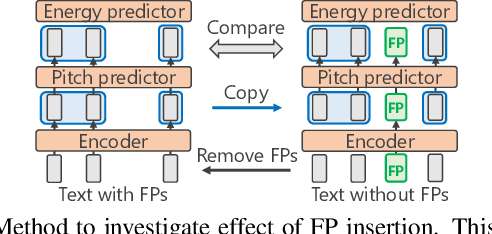
We present a comprehensive empirical study for personalized spontaneous speech synthesis on the basis of linguistic knowledge. With the advent of voice cloning for reading-style speech synthesis, a new voice cloning paradigm for human-like and spontaneous speech synthesis is required. We, therefore, focus on personalized spontaneous speech synthesis that can clone both the individual's voice timbre and speech disfluency. Specifically, we deal with filled pauses, a major source of speech disfluency, which is known to play an important role in speech generation and communication in psychology and linguistics. To comparatively evaluate personalized filled pause insertion and non-personalized filled pause prediction methods, we developed a speech synthesis method with a non-personalized external filled pause predictor trained with a multi-speaker corpus. The results clarify the position-word entanglement of filled pauses, i.e., the necessity of precisely predicting positions for naturalness and the necessity of precisely predicting words for individuality on the evaluation of synthesized speech.
Personalized filled-pause generation with group-wise prediction models
Mar 18, 2022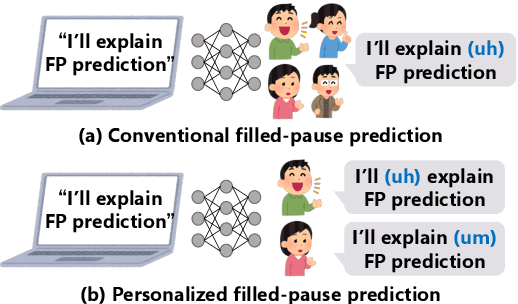
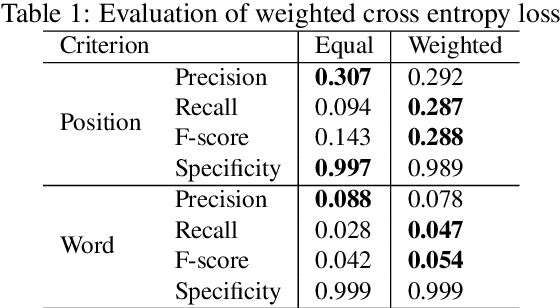
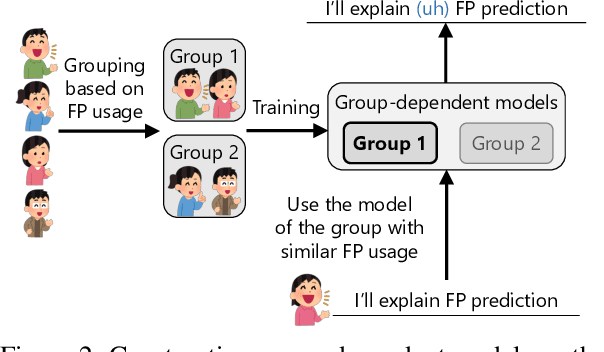
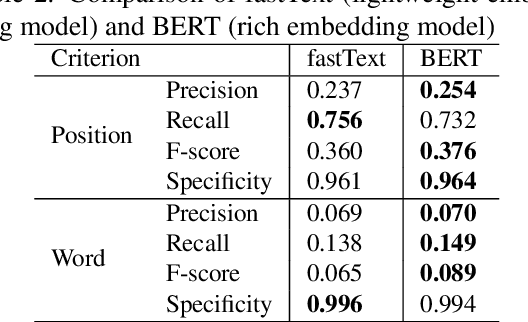
In this paper, we propose a method to generate personalized filled pauses (FPs) with group-wise prediction models. Compared with fluent text generation, disfluent text generation has not been widely explored. To generate more human-like texts, we addressed disfluent text generation. The usage of disfluency, such as FPs, rephrases, and word fragments, differs from speaker to speaker, and thus, the generation of personalized FPs is required. However, it is difficult to predict them because of the sparsity of position and the frequency difference between more and less frequently used FPs. Moreover, it is sometimes difficult to adapt FP prediction models to each speaker because of the large variation of the tendency within each speaker. To address these issues, we propose a method to build group-dependent prediction models by grouping speakers on the basis of their tendency to use FPs. This method does not require a large amount of data and time to train each speaker model. We further introduce a loss function and a word embedding model suitable for FP prediction. Our experimental results demonstrate that group-dependent models can predict FPs with higher scores than a non-personalized one and the introduced loss function and word embedding model improve the prediction performance.