 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpirical Study Incorporating Linguistic Knowledge on Filled Pauses for Personalized Spontaneous Speech Synthesis
Paper and Code

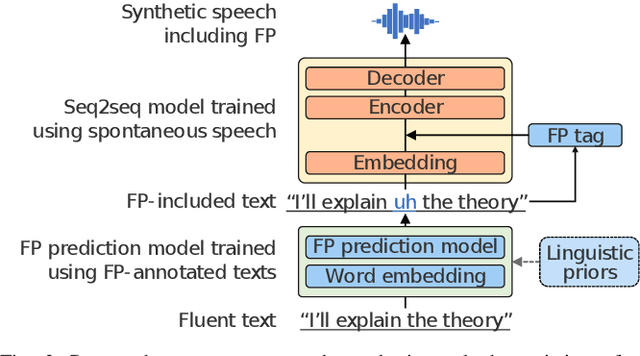
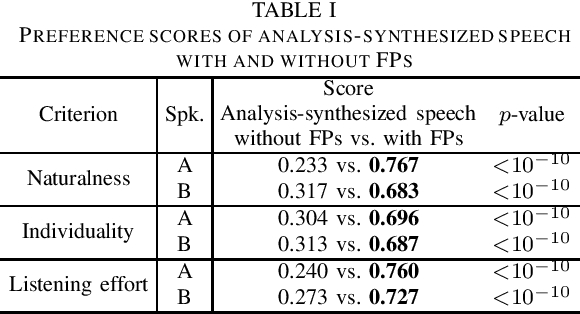
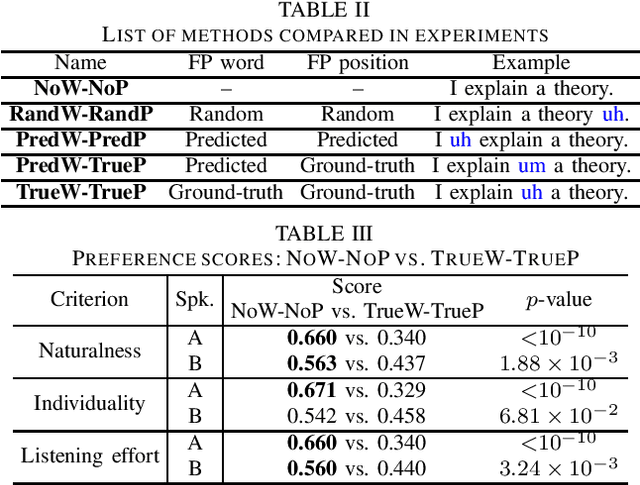
We present a comprehensive empirical study for personalized spontaneous speech synthesis on the basis of linguistic knowledge. With the advent of voice cloning for reading-style speech synthesis, a new voice cloning paradigm for human-like and spontaneous speech synthesis is required. We, therefore, focus on personalized spontaneous speech synthesis that can clone both the individual's voice timbre and speech disfluency. Specifically, we deal with filled pauses, a major source of speech disfluency, which is known to play an important role in speech generation and communication in psychology and linguistics. To comparatively evaluate personalized filled pause insertion and non-personalized filled pause prediction methods, we developed a speech synthesis method with a non-personalized external filled pause predictor trained with a multi-speaker corpus. The results clarify the position-word entanglement of filled pauses, i.e., the necessity of precisely predicting positions for naturalness and the necessity of precisely predicting words for individuality on the evaluation of synthesized speech.