 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpontaneous speech synthesis with linguistic-speech consistency training using pseudo-filled pauses
Paper and Code
Oct 18, 2022

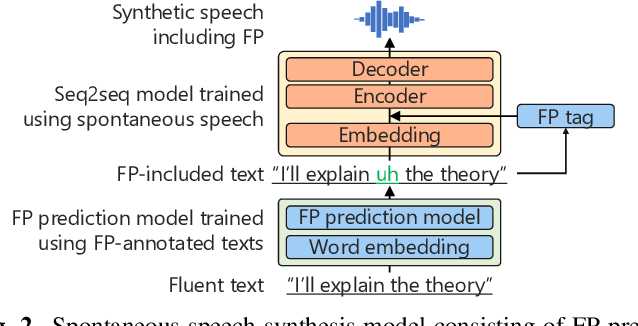
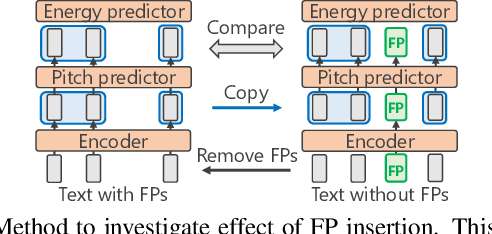
We propose a training method for spontaneous speech synthesis models that guarantees the consistency of linguistic parts of synthesized speech. Personalized spontaneous speech synthesis aims to reproduce the individuality of disfluency, such as filled pauses. Our prior model includes a filled-pause prediction model and synthesizes filled-pause-included speech from text without filled pauses. However, inserting the filled pauses degrades the quality of the linguistic parts of the synthesized speech. This might be because filled-pause insertion tendencies differ between training and inference, and the synthesis model cannot represent connections between filled pauses and surrounding phonemes in inference. We, therefore, developed a linguistic-speech consistency training that guarantees the consistency of linguistic parts of synthetic speech with and without filled pauses. The proposed consistency training utilizes not only ground-truth-filled pauses but also pseudo ones. Our experiments demonstrate that this method improves the naturalness of the synthetic linguistic speech and the entire predicted-filled-pause-included synthetic speech.