 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Explainable Spoofed Speech Attribution and Detection:a Probabilistic Approach for Characterizing Speech Synthesizer Components
Feb 07, 2025We propose an explainable probabilistic framework for characterizing spoofed speech by decomposing it into probabilistic attribute embeddings. Unlike raw high-dimensional countermeasure embeddings, which lack interpretability, the proposed probabilistic attribute embeddings aim to detect specific speech synthesizer components, represented through high-level attributes and their corresponding values. We use these probabilistic embeddings with four classifier back-ends to address two downstream tasks: spoofing detection and spoofing attack attribution. The former is the well-known bonafide-spoof detection task, whereas the latter seeks to identify the source method (generator) of a spoofed utterance. We additionally use Shapley values, a widely used technique in machine learning, to quantify the relative contribution of each attribute value to the decision-making process in each task. Results on the ASVspoof2019 dataset demonstrate the substantial role of duration and conversion modeling in spoofing detection; and waveform generation and speaker modeling in spoofing attack attribution. In the detection task, the probabilistic attribute embeddings achieve $99.7\%$ balanced accuracy and $0.22\%$ equal error rate (EER), closely matching the performance of raw embeddings ($99.9\%$ balanced accuracy and $0.22\%$ EER). Similarly, in the attribution task, our embeddings achieve $90.23\%$ balanced accuracy and $2.07\%$ EER, compared to $90.16\%$ and $2.11\%$ with raw embeddings. These results demonstrate that the proposed framework is both inherently explainable by design and capable of achieving performance comparable to raw CM embeddings.
An Explainable Probabilistic Attribute Embedding Approach for Spoofed Speech Characterization
Sep 17, 2024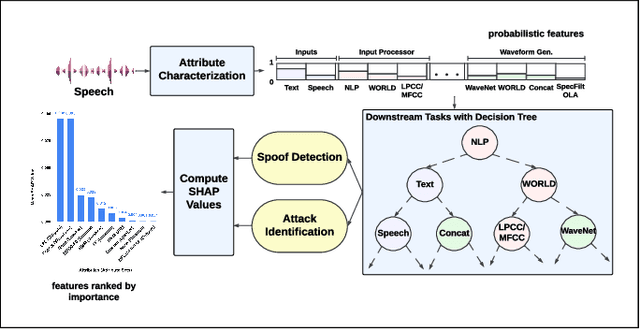
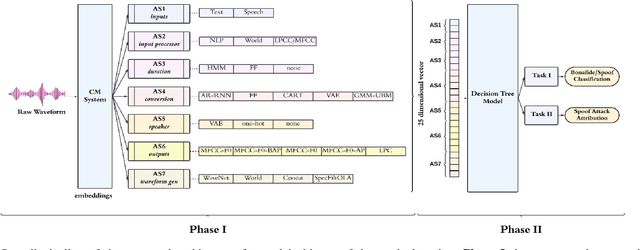
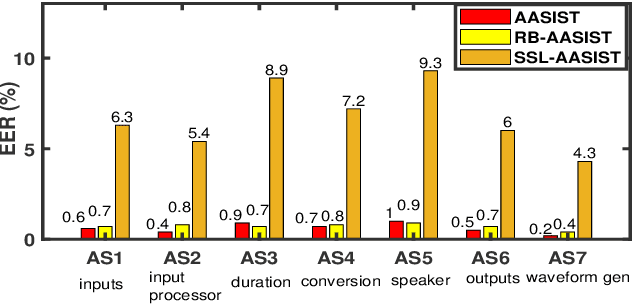
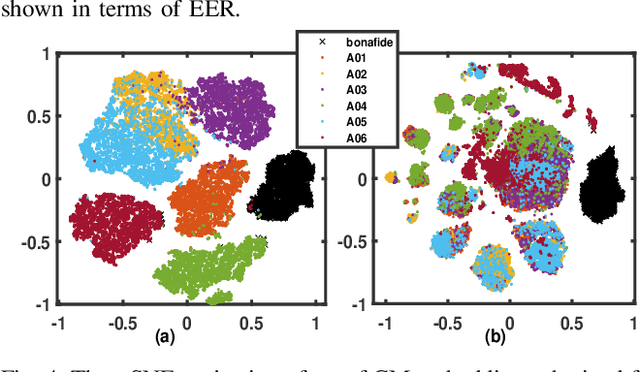
We propose a novel approach for spoofed speech characterization through explainable probabilistic attribute embeddings. In contrast to high-dimensional raw embeddings extracted from a spoofing countermeasure (CM) whose dimensions are not easy to interpret, the probabilistic attributes are designed to gauge the presence or absence of sub-components that make up a specific spoofing attack. These attributes are then applied to two downstream tasks: spoofing detection and attack attribution. To enforce interpretability also to the back-end, we adopt a decision tree classifier. Our experiments on the ASVspoof2019 dataset with spoof CM embeddings extracted from three models (AASIST, Rawboost-AASIST, SSL-AASIST) suggest that the performance of the attribute embeddings are on par with the original raw spoof CM embeddings for both tasks. The best performance achieved with the proposed approach for spoofing detection and attack attribution, in terms of accuracy, is 99.7% and 99.2%, respectively, compared to 99.7% and 94.7% using the raw CM embeddings. To analyze the relative contribution of each attribute, we estimate their Shapley values. Attributes related to acoustic feature prediction, waveform generation (vocoder), and speaker modeling are found important for spoofing detection; while duration modeling, vocoder, and input type play a role in spoofing attack attribution.