 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReverbMiipher: Generative Speech Restoration meets Reverberation Characteristics Controllability
May 08, 2025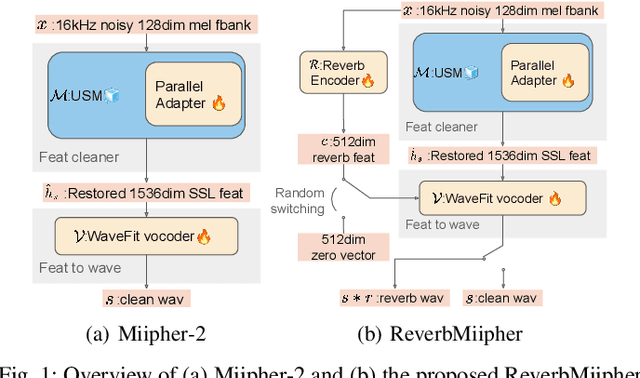
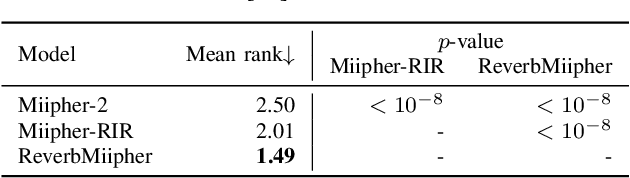
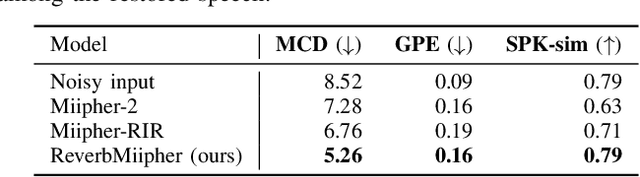
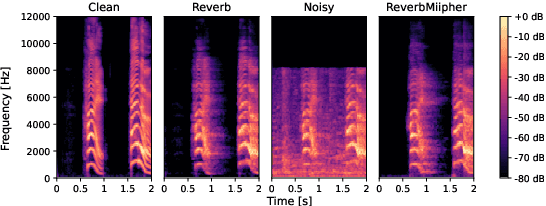
Reverberation encodes spatial information regarding the acoustic source environment, yet traditional Speech Restoration (SR) usually completely removes reverberation. We propose ReverbMiipher, an SR model extending parametric resynthesis framework, designed to denoise speech while preserving and enabling control over reverberation. ReverbMiipher incorporates a dedicated ReverbEncoder to extract a reverb feature vector from noisy input. This feature conditions a vocoder to reconstruct the speech signal, removing noise while retaining the original reverberation characteristics. A stochastic zero-vector replacement strategy during training ensures the feature specifically encodes reverberation, disentangling it from other speech attributes. This learned representation facilitates reverberation control via techniques such as interpolation between features, replacement with features from other utterances, or sampling from a latent space. Objective and subjective evaluations confirm ReverbMiipher effectively preserves reverberation, removes other artifacts, and outperforms the conventional two-stage SR and convolving simulated room impulse response approach. We further demonstrate its ability to generate novel reverberation effects through feature manipulation.
Miipher-2: A Universal Speech Restoration Model for Million-Hour Scale Data Restoration
May 07, 2025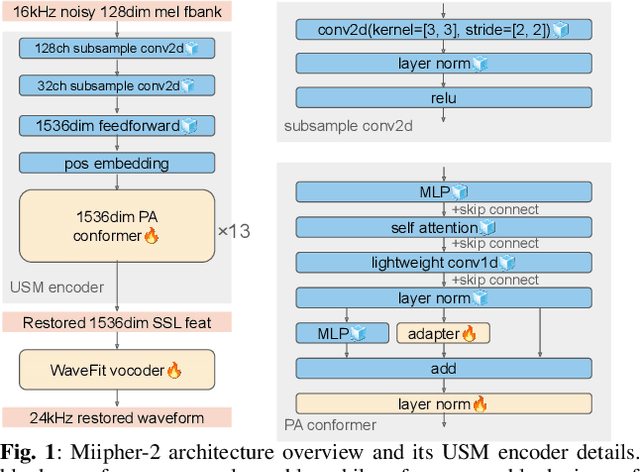
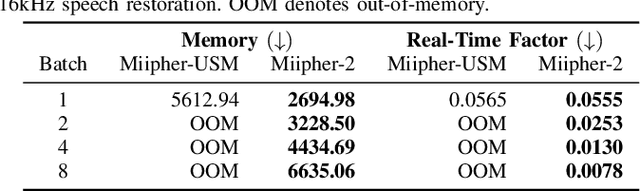
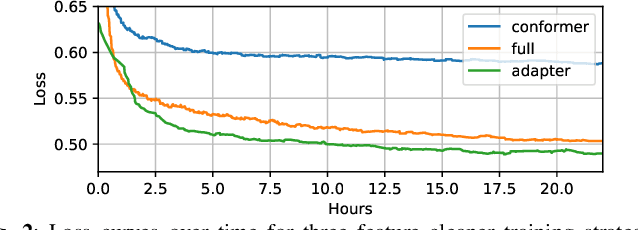
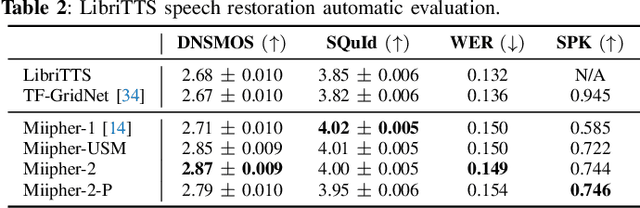
Training data cleaning is a new application for generative model-based speech restoration (SR). This paper introduces Miipher-2, an SR model designed for million-hour scale data, for training data cleaning for large-scale generative models like large language models. Key challenges addressed include generalization to unseen languages, operation without explicit conditioning (e.g., text, speaker ID), and computational efficiency. Miipher-2 utilizes a frozen, pre-trained Universal Speech Model (USM), supporting over 300 languages, as a robust, conditioning-free feature extractor. To optimize efficiency and minimize memory, Miipher-2 incorporates parallel adapters for predicting clean USM features from noisy inputs and employs the WaneFit neural vocoder for waveform synthesis. These components were trained on 3,000 hours of multi-lingual, studio-quality recordings with augmented degradations, while USM parameters remained fixed. Experimental results demonstrate Miipher-2's superior or comparable performance to conventional SR models in word-error-rate, speaker similarity, and both objective and subjective sound quality scores across all tested languages. Miipher-2 operates efficiently on consumer-grade accelerators, achieving a real-time factor of 0.0078, enabling the processing of a million-hour speech dataset in approximately three days using only 100 such accelerators.
FLEURS-R: A Restored Multilingual Speech Corpus for Generation Tasks
Aug 12, 2024
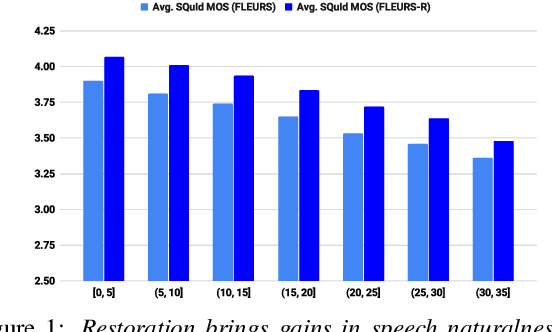
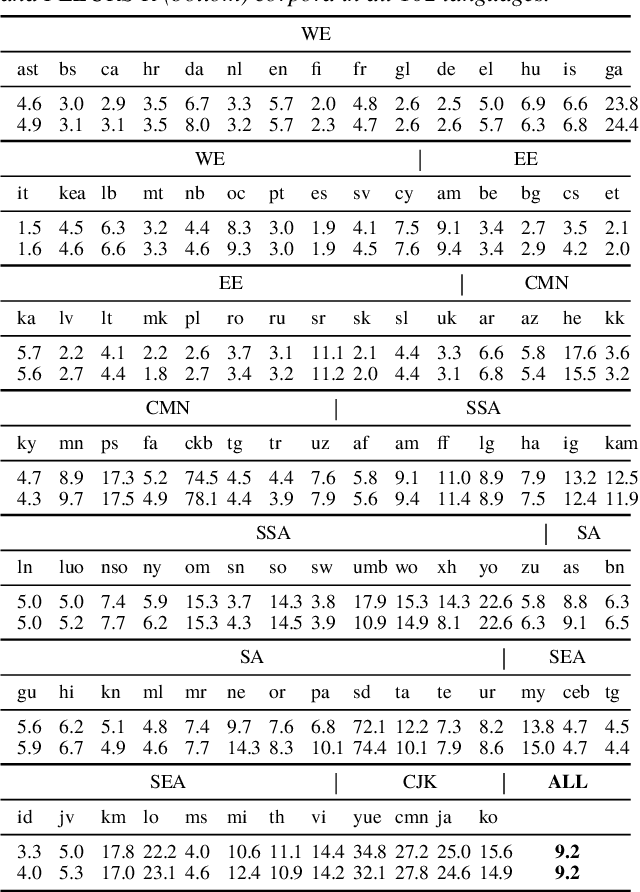
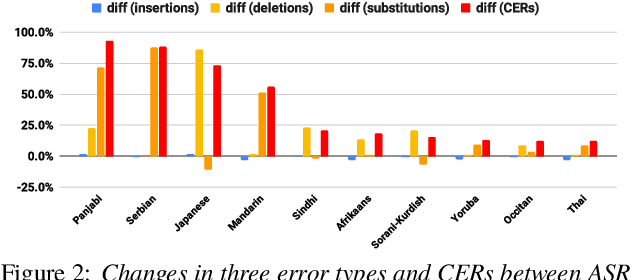
This paper introduces FLEURS-R, a speech restoration applied version of the Few-shot Learning Evaluation of Universal Representations of Speech (FLEURS) corpus. FLEURS-R maintains an N-way parallel speech corpus in 102 languages as FLEURS, with improved audio quality and fidelity by applying the speech restoration model Miipher. The aim of FLEURS-R is to advance speech technology in more languages and catalyze research including text-to-speech (TTS) and other speech generation tasks in low-resource languages. Comprehensive evaluations with the restored speech and TTS baseline models trained from the new corpus show that the new corpus obtained significantly improved speech quality while maintaining the semantic contents of the speech. The corpus is publicly released via Hugging Face.
LibriTTS-R: A Restored Multi-Speaker Text-to-Speech Corpus
May 30, 2023
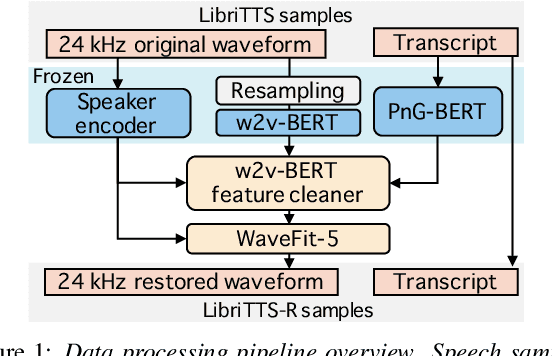
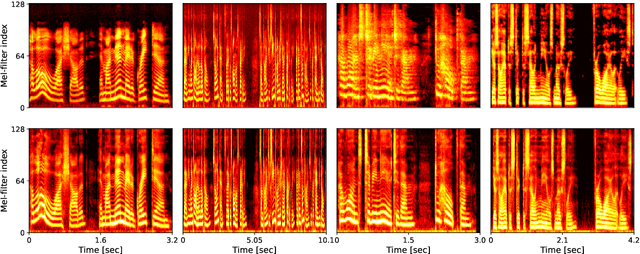

This paper introduces a new speech dataset called ``LibriTTS-R'' designed for text-to-speech (TTS) use. It is derived by applying speech restoration to the LibriTTS corpus, which consists of 585 hours of speech data at 24 kHz sampling rate from 2,456 speakers and the corresponding texts. The constituent samples of LibriTTS-R are identical to those of LibriTTS, with only the sound quality improved. Experimental results show that the LibriTTS-R ground-truth samples showed significantly improved sound quality compared to those in LibriTTS. In addition, neural end-to-end TTS trained with LibriTTS-R achieved speech naturalness on par with that of the ground-truth samples. The corpus is freely available for download from \url{http://www.openslr.org/141/}.
Description and Discussion on DCASE 2023 Challenge Task 2: First-Shot Unsupervised Anomalous Sound Detection for Machine Condition Monitoring
May 13, 2023



We present the task description of the Detection and Classification of Acoustic Scenes and Events (DCASE) 2023 Challenge Task 2: "First-shot unsupervised anomalous sound detection (ASD) for machine condition monitoring". The main goal is to enable rapid deployment of ASD systems for new kinds of machines using only a few normal samples, without the need for hyperparameter tuning. In the past ASD tasks, developed methods tuned hyperparameters for each machine type, as the development and evaluation datasets had the same machine types. However, collecting normal and anomalous data as the development dataset can be infeasible in practice. In 2023 Task 2, we focus on solving first-shot problem, which is the challenge of training a model on a few machines of a completely novel machine type. Specifically, (i) each machine type has only one section, and (ii) machine types in the development and evaluation datasets are completely different. We will add challenge results and analysis of the submissions after the challenge submission deadline.
Miipher: A Robust Speech Restoration Model Integrating Self-Supervised Speech and Text Representations
Mar 03, 2023



Speech restoration (SR) is a task of converting degraded speech signals into high-quality ones. In this study, we propose a robust SR model called Miipher, and apply Miipher to a new SR application: increasing the amount of high-quality training data for speech generation by converting speech samples collected from the Web to studio-quality. To make our SR model robust against various degradation, we use (i) a speech representation extracted from w2v-BERT for the input feature, and (ii) a text representation extracted from transcripts via PnG-BERT as a linguistic conditioning feature. Experiments show that Miipher (i) is robust against various audio degradation and (ii) enable us to train a high-quality text-to-speech (TTS) model from restored speech samples collected from the Web. Audio samples are available at our demo page: google.github.io/df-conformer/miipher/
WaveFit: An Iterative and Non-autoregressive Neural Vocoder based on Fixed-Point Iteration
Oct 03, 2022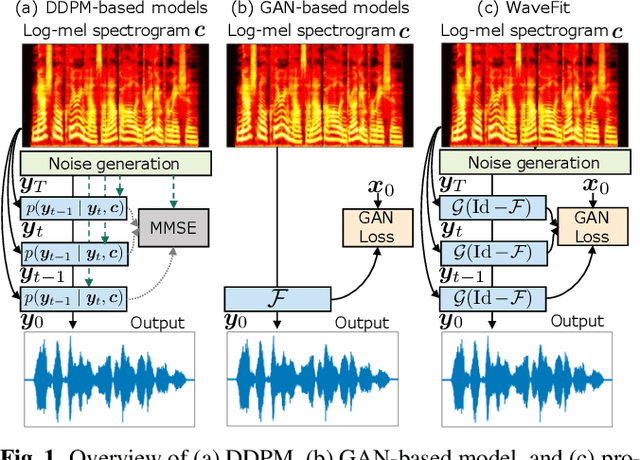
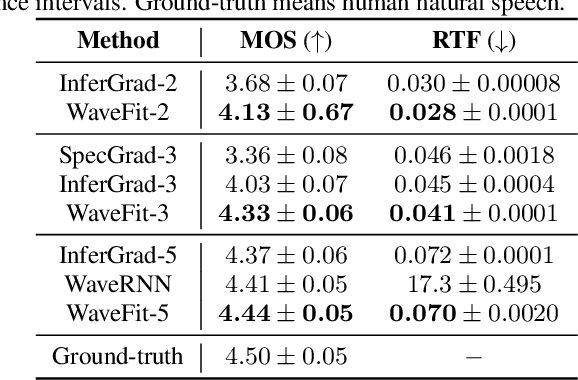
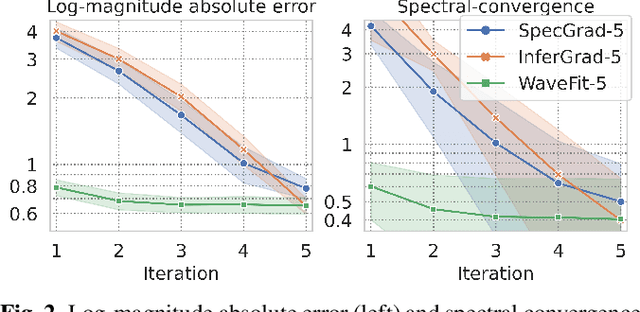
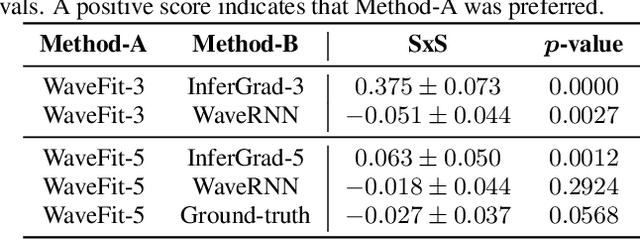
Denoising diffusion probabilistic models (DDPMs) and generative adversarial networks (GANs) are popular generative models for neural vocoders. The DDPMs and GANs can be characterized by the iterative denoising framework and adversarial training, respectively. This study proposes a fast and high-quality neural vocoder called \textit{WaveFit}, which integrates the essence of GANs into a DDPM-like iterative framework based on fixed-point iteration. WaveFit iteratively denoises an input signal, and trains a deep neural network (DNN) for minimizing an adversarial loss calculated from intermediate outputs at all iterations. Subjective (side-by-side) listening tests showed no statistically significant differences in naturalness between human natural speech and those synthesized by WaveFit with five iterations. Furthermore, the inference speed of WaveFit was more than 240 times faster than WaveRNN. Audio demos are available at \url{google.github.io/df-conformer/wavefit/}.
Description and Discussion on DCASE 2022 Challenge Task 2: Unsupervised Anomalous Sound Detection for Machine Condition Monitoring Applying Domain Generalization Techniques
Jun 13, 2022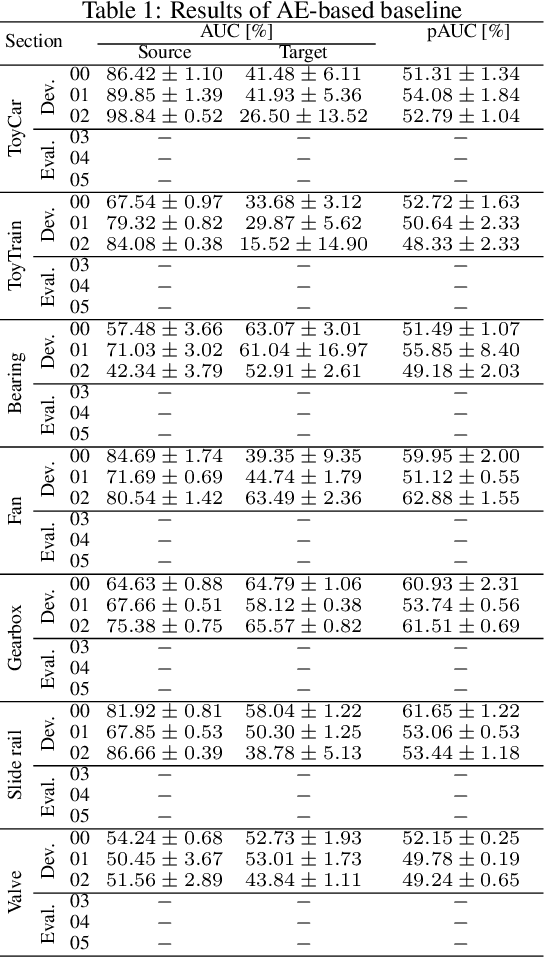
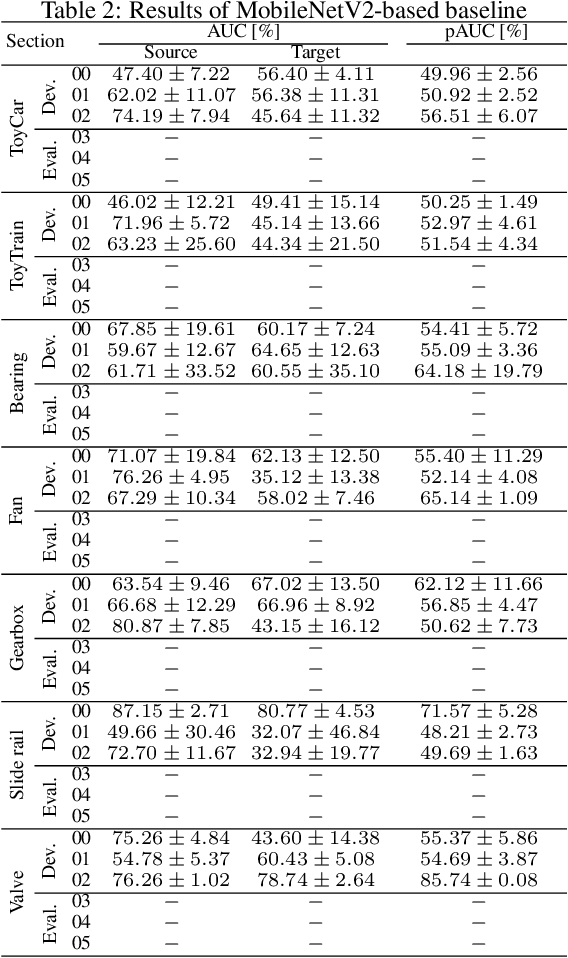
We present the task description of the Detection and Classification of Acoustic Scenes and Events (DCASE) 2022 Challenge Task 2: "Unsupervised anomalous sound detection (ASD) for machine condition monitoring applying domain generalization techniques". Domain shifts are a critical problem for the application of ASD systems. Because domain shifts can change the acoustic characteristics of data, a model trained in a source domain performs poorly for a target domain. In DCASE 2021 Challenge Task 2, we organized an ASD task for handling domain shifts. In this task, it was assumed that the occurrences of domain shifts are known. However, in practice, the domain of each sample may not be given, and the domain shifts can occur implicitly. In 2022 Task 2, we focus on domain generalization techniques that detects anomalies regardless of the domain shifts. Specifically, the domain of each sample is not given in the test data and only one threshold is allowed for all domains. We will add challenge results and analysis of the submissions after the challenge submission deadline.
Mask scalar prediction for improving robust automatic speech recognition
Apr 26, 2022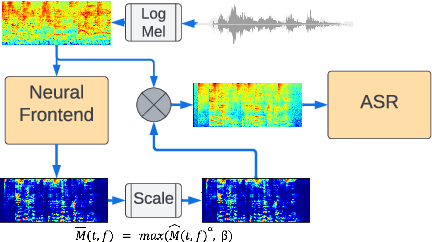
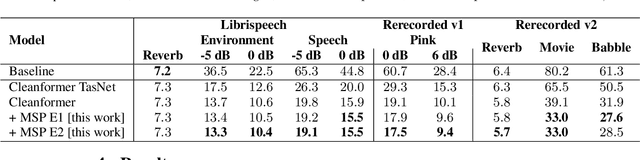
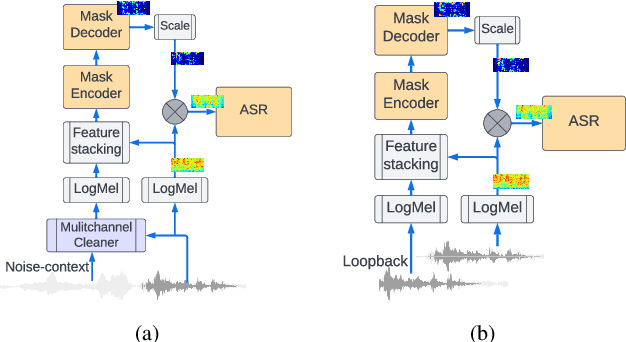
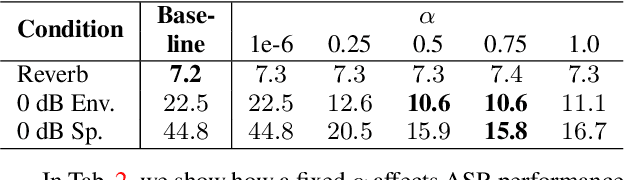
Using neural network based acoustic frontends for improving robustness of streaming automatic speech recognition (ASR) systems is challenging because of the causality constraints and the resulting distortion that the frontend processing introduces in speech. Time-frequency masking based approaches have been shown to work well, but they need additional hyper-parameters to scale the mask to limit speech distortion. Such mask scalars are typically hand-tuned and chosen conservatively. In this work, we present a technique to predict mask scalars using an ASR-based loss in an end-to-end fashion, with minimal increase in the overall model size and complexity. We evaluate the approach on two robust ASR tasks: multichannel enhancement in the presence of speech and non-speech noise, and acoustic echo cancellation (AEC). Results show that the presented algorithm consistently improves word error rate (WER) without the need for any additional tuning over strong baselines that use hand-tuned hyper-parameters: up to 16% for multichannel enhancement in noisy conditions, and up to 7% for AEC.
SpecGrad: Diffusion Probabilistic Model based Neural Vocoder with Adaptive Noise Spectral Shaping
Mar 31, 2022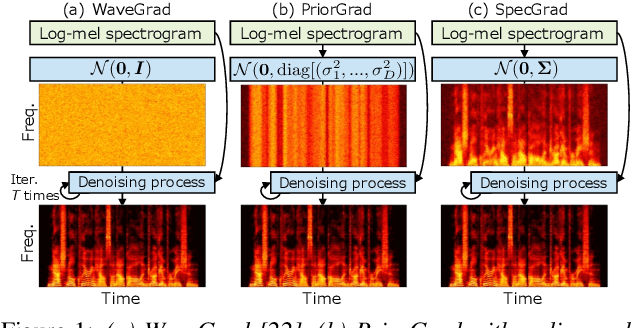
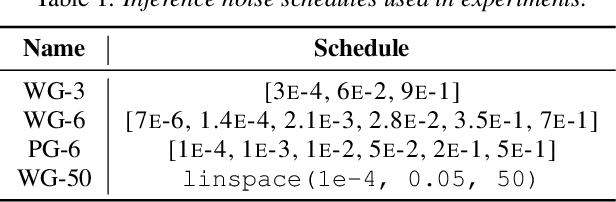
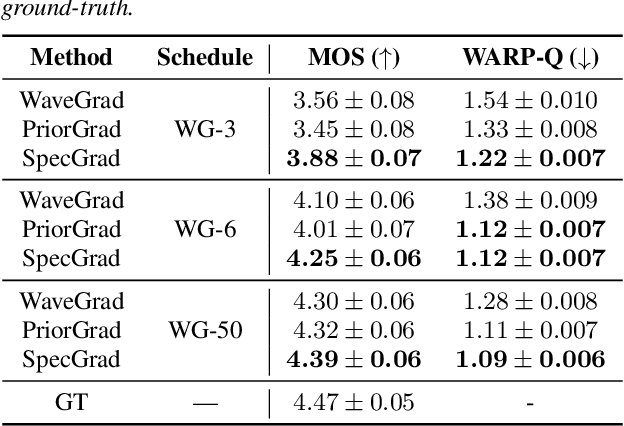
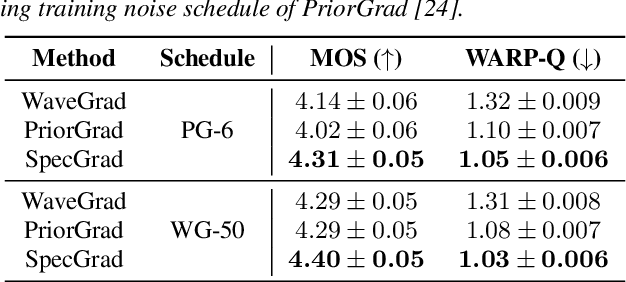
Neural vocoder using denoising diffusion probabilistic model (DDPM) has been improved by adaptation of the diffusion noise distribution to given acoustic features. In this study, we propose SpecGrad that adapts the diffusion noise so that its time-varying spectral envelope becomes close to the conditioning log-mel spectrogram. This adaptation by time-varying filtering improves the sound quality especially in the high-frequency bands. It is processed in the time-frequency domain to keep the computational cost almost the same as the conventional DDPM-based neural vocoders. Experimental results showed that SpecGrad generates higher-fidelity speech waveform than conventional DDPM-based neural vocoders in both analysis-synthesis and speech enhancement scenarios. Audio demos are available at wavegrad.github.io/specgrad/.