 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaSTR: Language-Driven Time-Series Segment Retrieval
Feb 28, 2026Effectively searching time-series data is essential for system analysis, but existing methods often require expert-designed similarity criteria or rely on global, series-level descriptions. We study language-driven segment retrieval: given a natural language query, the goal is to retrieve relevant local segments from large time-series repositories. We build large-scale segment--caption training data by applying TV2-based segmentation to LOTSA windows and generating segment descriptions with GPT-5.2, and then train a Conformer-based contrastive retriever in a shared text--time-series embedding space. On a held-out test split, we evaluate single-positive retrieval together with caption-side consistency (SBERT and VLM-as-a-judge) under multiple candidate pool sizes. Across all settings, LaSTR outperforms random and CLIP baselines, yielding improved ranking quality and stronger semantic agreement between retrieved segments and query intent.
MIMII-Agent: Leveraging LLMs with Function Calling for Relative Evaluation of Anomalous Sound Detection
Jul 28, 2025This paper proposes a method for generating machine-type-specific anomalies to evaluate the relative performance of unsupervised anomalous sound detection (UASD) systems across different machine types, even in the absence of real anomaly sound data. Conventional keyword-based data augmentation methods often produce unrealistic sounds due to their reliance on manually defined labels, limiting scalability as machine types and anomaly patterns diversify. Advanced audio generative models, such as MIMII-Gen, show promise but typically depend on anomalous training data, making them less effective when diverse anomalous examples are unavailable. To address these limitations, we propose a novel synthesis approach leveraging large language models (LLMs) to interpret textual descriptions of faults and automatically select audio transformation functions, converting normal machine sounds into diverse and plausible anomalous sounds. We validate this approach by evaluating a UASD system trained only on normal sounds from five machine types, using both real and synthetic anomaly data. Experimental results reveal consistent trends in relative detection difficulty across machine types between synthetic and real anomalies. This finding supports our hypothesis and highlights the effectiveness of the proposed LLM-based synthesis approach for relative evaluation of UASD systems.
LLM-based Generative Error Correction for Rare Words with Synthetic Data and Phonetic Context
May 23, 2025Generative error correction (GER) with large language models (LLMs) has emerged as an effective post-processing approach to improve automatic speech recognition (ASR) performance. However, it often struggles with rare or domain-specific words due to limited training data. Furthermore, existing LLM-based GER approaches primarily rely on textual information, neglecting phonetic cues, which leads to over-correction. To address these issues, we propose a novel LLM-based GER approach that targets rare words and incorporates phonetic information. First, we generate synthetic data to contain rare words for fine-tuning the GER model. Second, we integrate ASR's N-best hypotheses along with phonetic context to mitigate over-correction. Experimental results show that our method not only improves the correction of rare words but also reduces the WER and CER across both English and Japanese datasets.
Retrieving Time-Series Differences Using Natural Language Queries
Mar 27, 2025Effectively searching time-series data is essential for system analysis; however, traditional methods often require domain expertise to define search criteria. Recent advancements have enabled natural language-based search, but these methods struggle to handle differences between time-series data. To address this limitation, we propose a natural language query-based approach for retrieving pairs of time-series data based on differences specified in the query. Specifically, we define six key characteristics of differences, construct a corresponding dataset, and develop a contrastive learning-based model to align differences between time-series data with query texts. Experimental results demonstrate that our model achieves an overall mAP score of 0.994 in retrieving time-series pairs.
CLaSP: Learning Concepts for Time-Series Signals from Natural Language Supervision
Nov 13, 2024This paper proposes a foundation model called "CLaSP" that can search time series signals using natural language that describes the characteristics of the signals as queries. Previous efforts to represent time series signal data in natural language have had challenges in designing a conventional class of time series signal characteristics, formulating their quantification, and creating a dictionary of synonyms. To overcome these limitations, the proposed method introduces a neural network based on contrastive learning. This network is first trained using the datasets TRUCE and SUSHI, which consist of time series signals and their corresponding natural language descriptions. Previous studies have proposed vocabularies that data analysts use to describe signal characteristics, and SUSHI was designed to cover these terms. We believe that a neural network trained on these datasets will enable data analysts to search using natural language vocabulary. Furthermore, our method does not require a dictionary of predefined synonyms, and it leverages common sense knowledge embedded in a large-scale language model (LLM). Experimental results demonstrate that CLaSP enables natural language search of time series signal data and can accurately learn the points at which signal data changes.
Retrieval-Augmented Approach for Unsupervised Anomalous Sound Detection and Captioning without Model Training
Oct 29, 2024This paper proposes a method for unsupervised anomalous sound detection (UASD) and captioning the reason for detection. While there is a method that captions the difference between given normal and anomalous sound pairs, it is assumed to be trained and used separately from the UASD model. Therefore, the obtained caption can be irrelevant to the differences that the UASD model captured. In addition, it requires many caption labels representing differences between anomalous and normal sounds for model training. The proposed method employs a retrieval-augmented approach for captioning of anomalous sounds. Difference captioning in the embedding space output by the pre-trained CLAP (contrastive language-audio pre-training) model makes the anomalous sound detection results consistent with the captions and does not require training. Experiments based on subjective evaluation and a sample-wise analysis of the output captions demonstrate the effectiveness of the proposed method.
Timbre Difference Capturing in Anomalous Sound Detection
Oct 29, 2024



This paper proposes a framework of explaining anomalous machine sounds in the context of anomalous sound detection~(ASD). While ASD has been extensively explored, identifying how anomalous sounds differ from normal sounds is also beneficial for machine condition monitoring. However, existing sound difference captioning methods require anomalous sounds for training, which is impractical in typical machine condition monitoring settings where such sounds are unavailable. To solve this issue, we propose a new strategy for explaining anomalous differences that does not require anomalous sounds for training. Specifically, we introduce a framework that explains differences in predefined timbre attributes instead of using free-form text captions. Objective metrics of timbre attributes can be computed using timbral models developed through psycho-acoustical research, enabling the estimation of how and what timbre attributes have changed from normal sounds without training machine learning models. Additionally, to accurately determine timbre differences regardless of variations in normal training data, we developed a method that jointly conducts anomalous sound detection and timbre difference estimation based on a k-nearest neighbors method in an audio embedding space. Evaluation using the MIMII DG dataset demonstrated the effectiveness of the proposed method.
End-to-End Integration of Speech Emotion Recognition with Voice Activity Detection using Self-Supervised Learning Features
Oct 17, 2024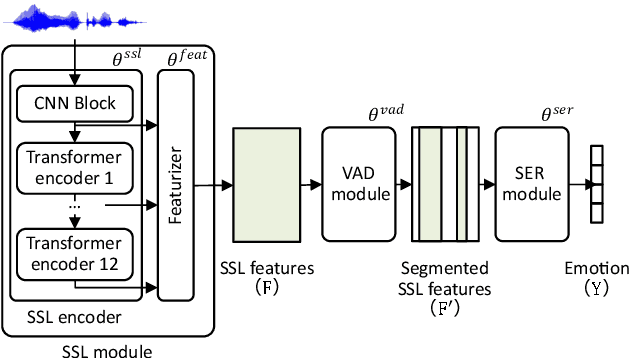
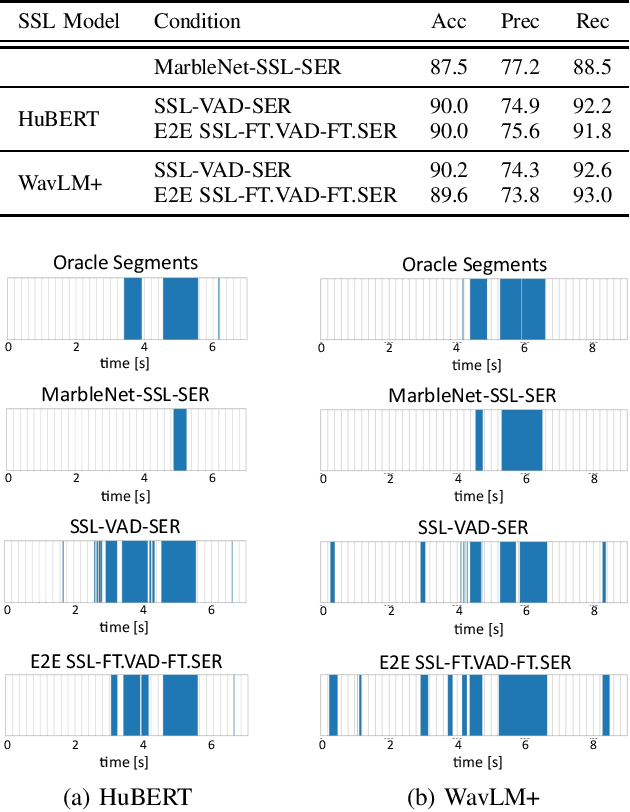
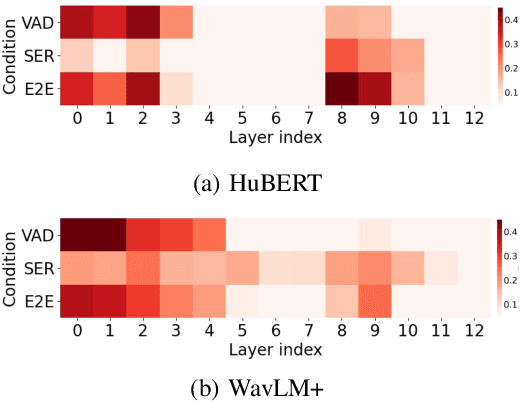
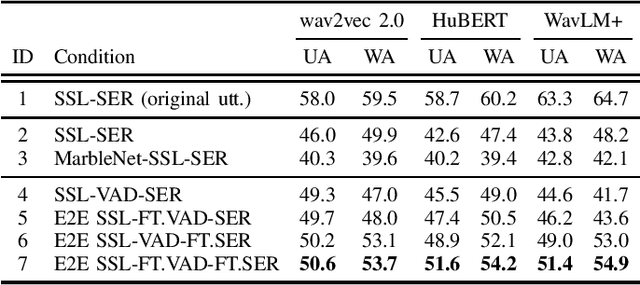
Speech Emotion Recognition (SER) often operates on speech segments detected by a Voice Activity Detection (VAD) model. However, VAD models may output flawed speech segments, especially in noisy environments, resulting in degraded performance of subsequent SER models. To address this issue, we propose an end-to-end (E2E) method that integrates VAD and SER using Self-Supervised Learning (SSL) features. The VAD module first receives the SSL features as input, and the segmented SSL features are then fed into the SER module. Both the VAD and SER modules are jointly trained to optimize SER performance. Experimental results on the IEMOCAP dataset demonstrate that our proposed method improves SER performance. Furthermore, to investigate the effect of our proposed method on the VAD and SSL modules, we present an analysis of the VAD outputs and the weights of each layer of the SSL encoder.
Can We Estimate Purchase Intention Based on Zero-shot Speech Emotion Recognition?
Oct 12, 2024This paper proposes a zero-shot speech emotion recognition (SER) method that estimates emotions not previously defined in the SER model training. Conventional methods are limited to recognizing emotions defined by a single word. Moreover, we have the motivation to recognize unknown bipolar emotions such as ``I want to buy - I do not want to buy.'' In order to allow the model to define classes using sentences freely and to estimate unknown bipolar emotions, our proposed method expands upon the contrastive language-audio pre-training (CLAP) framework by introducing multi-class and multi-task settings. We also focus on purchase intention as a bipolar emotion and investigate the model's performance to zero-shot estimate it. This study is the first attempt to estimate purchase intention from speech directly. Experiments confirm that the results of zero-shot estimation by the proposed method are at the same level as those of the model trained by supervised learning.
MIMII-Gen: Generative Modeling Approach for Simulated Evaluation of Anomalous Sound Detection System
Sep 27, 2024



Insufficient recordings and the scarcity of anomalies present significant challenges in developing and validating robust anomaly detection systems for machine sounds. To address these limitations, we propose a novel approach for generating diverse anomalies in machine sound using a latent diffusion-based model that integrates an encoder-decoder framework. Our method utilizes the Flan-T5 model to encode captions derived from audio file metadata, enabling conditional generation through a carefully designed U-Net architecture. This approach aids our model in generating audio signals within the EnCodec latent space, ensuring high contextual relevance and quality. We objectively evaluated the quality of our generated sounds using the Fr\'echet Audio Distance (FAD) score and other metrics, demonstrating that our approach surpasses existing models in generating reliable machine audio that closely resembles actual abnormal conditions. The evaluation of the anomaly detection system using our generated data revealed a strong correlation, with the area under the curve (AUC) score differing by 4.8\% from the original, validating the effectiveness of our generated data. These results demonstrate the potential of our approach to enhance the evaluation and robustness of anomaly detection systems across varied and previously unseen conditions. Audio samples can be found at \url{https://hpworkhub.github.io/MIMII-Gen.github.io/}.