 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-based Generative Error Correction for Rare Words with Synthetic Data and Phonetic Context
May 23, 2025Generative error correction (GER) with large language models (LLMs) has emerged as an effective post-processing approach to improve automatic speech recognition (ASR) performance. However, it often struggles with rare or domain-specific words due to limited training data. Furthermore, existing LLM-based GER approaches primarily rely on textual information, neglecting phonetic cues, which leads to over-correction. To address these issues, we propose a novel LLM-based GER approach that targets rare words and incorporates phonetic information. First, we generate synthetic data to contain rare words for fine-tuning the GER model. Second, we integrate ASR's N-best hypotheses along with phonetic context to mitigate over-correction. Experimental results show that our method not only improves the correction of rare words but also reduces the WER and CER across both English and Japanese datasets.
End-to-End Integration of Speech Emotion Recognition with Voice Activity Detection using Self-Supervised Learning Features
Oct 17, 2024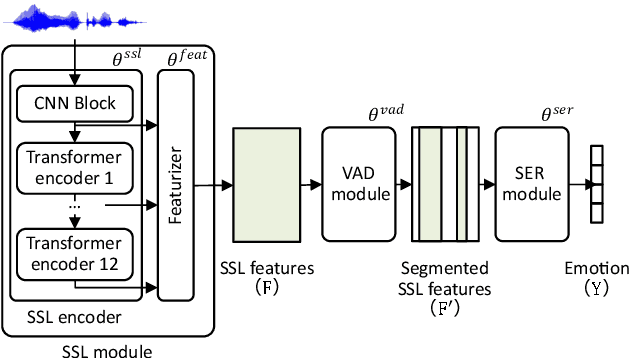
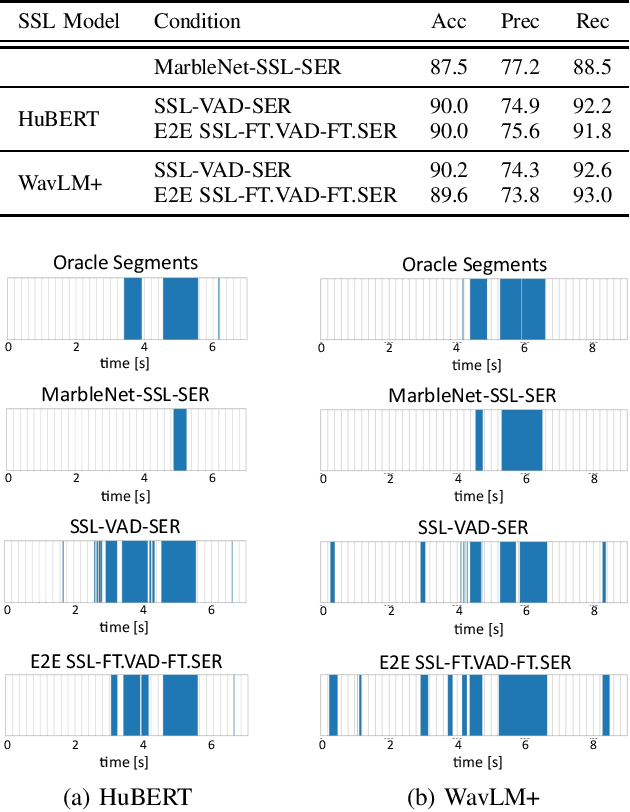
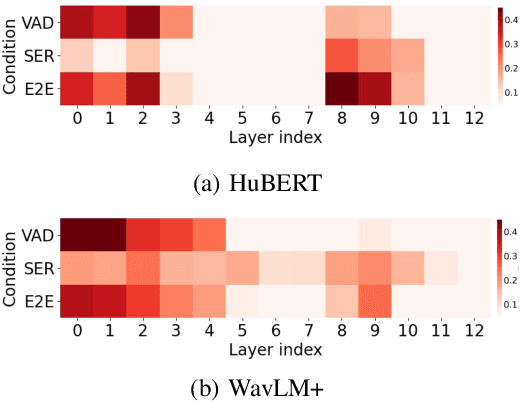
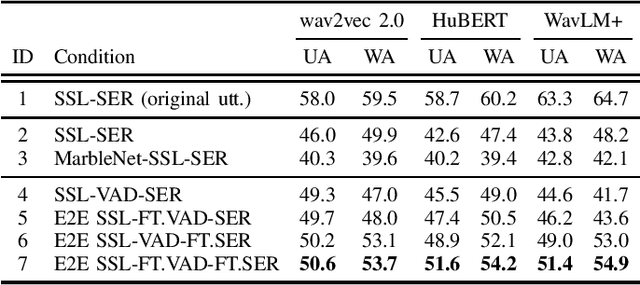
Speech Emotion Recognition (SER) often operates on speech segments detected by a Voice Activity Detection (VAD) model. However, VAD models may output flawed speech segments, especially in noisy environments, resulting in degraded performance of subsequent SER models. To address this issue, we propose an end-to-end (E2E) method that integrates VAD and SER using Self-Supervised Learning (SSL) features. The VAD module first receives the SSL features as input, and the segmented SSL features are then fed into the SER module. Both the VAD and SER modules are jointly trained to optimize SER performance. Experimental results on the IEMOCAP dataset demonstrate that our proposed method improves SER performance. Furthermore, to investigate the effect of our proposed method on the VAD and SSL modules, we present an analysis of the VAD outputs and the weights of each layer of the SSL encoder.
Description and Discussion on DCASE 2022 Challenge Task 2: Unsupervised Anomalous Sound Detection for Machine Condition Monitoring Applying Domain Generalization Techniques
Jun 13, 2022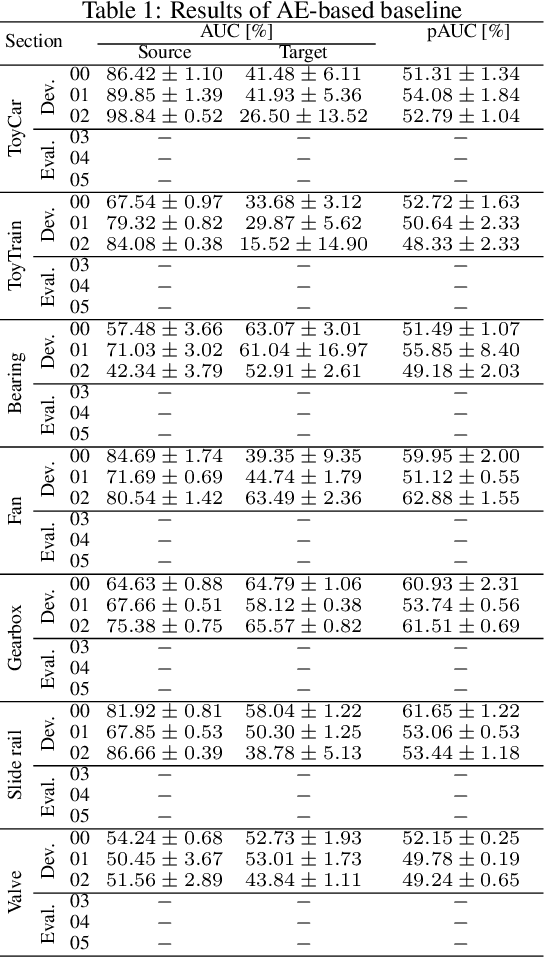
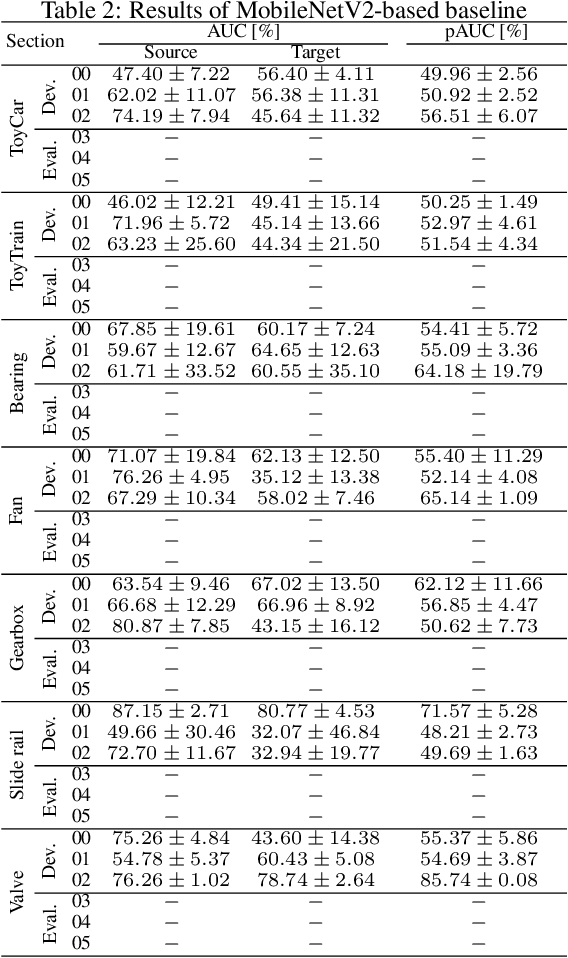
We present the task description of the Detection and Classification of Acoustic Scenes and Events (DCASE) 2022 Challenge Task 2: "Unsupervised anomalous sound detection (ASD) for machine condition monitoring applying domain generalization techniques". Domain shifts are a critical problem for the application of ASD systems. Because domain shifts can change the acoustic characteristics of data, a model trained in a source domain performs poorly for a target domain. In DCASE 2021 Challenge Task 2, we organized an ASD task for handling domain shifts. In this task, it was assumed that the occurrences of domain shifts are known. However, in practice, the domain of each sample may not be given, and the domain shifts can occur implicitly. In 2022 Task 2, we focus on domain generalization techniques that detects anomalies regardless of the domain shifts. Specifically, the domain of each sample is not given in the test data and only one threshold is allowed for all domains. We will add challenge results and analysis of the submissions after the challenge submission deadline.
Hierarchical Conditional Variational Autoencoder Based Acoustic Anomaly Detection
Jun 11, 2022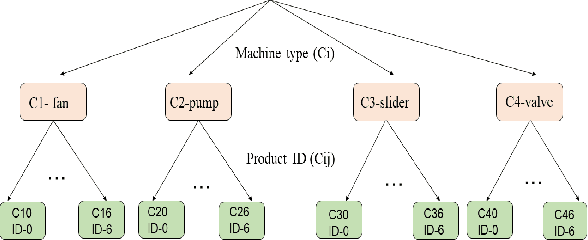
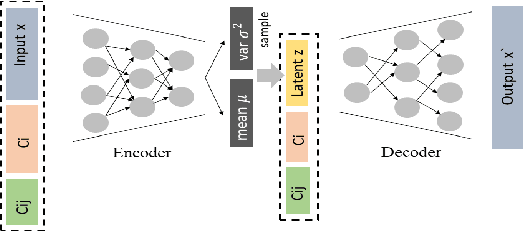
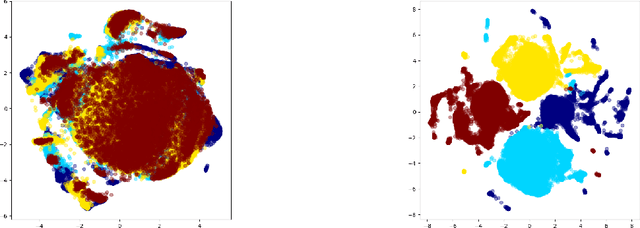
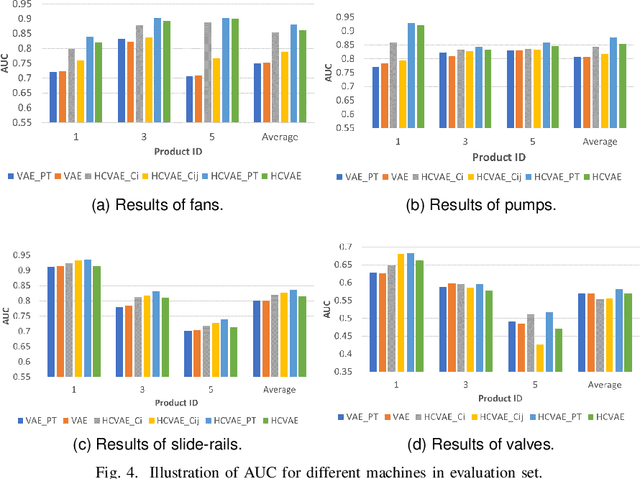
This paper aims to develop an acoustic signal-based unsupervised anomaly detection method for automatic machine monitoring. Existing approaches such as deep autoencoder (DAE), variational autoencoder (VAE), conditional variational autoencoder (CVAE) etc. have limited representation capabilities in the latent space and, hence, poor anomaly detection performance. Different models have to be trained for each different kind of machines to accurately perform the anomaly detection task. To solve this issue, we propose a new method named as hierarchical conditional variational autoencoder (HCVAE). This method utilizes available taxonomic hierarchical knowledge about industrial facility to refine the latent space representation. This knowledge helps model to improve the anomaly detection performance as well. We demonstrated the generalization capability of a single HCVAE model for different types of machines by using appropriate conditions. Additionally, to show the practicability of the proposed approach, (i) we evaluated HCVAE model on different domain and (ii) we checked the effect of partial hierarchical knowledge. Our results show that HCVAE method validates both of these points, and it outperforms the baseline system on anomaly detection task by utmost 15 % on the AUC score metric.
MIMII DG: Sound Dataset for Malfunctioning Industrial Machine Investigation and Inspection for Domain Generalization Task
May 27, 2022

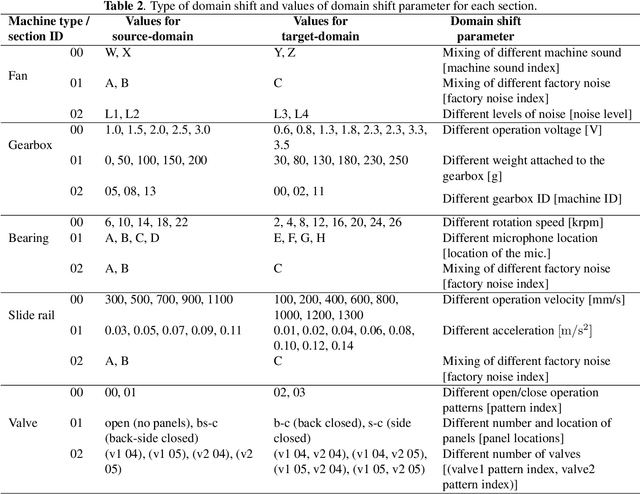
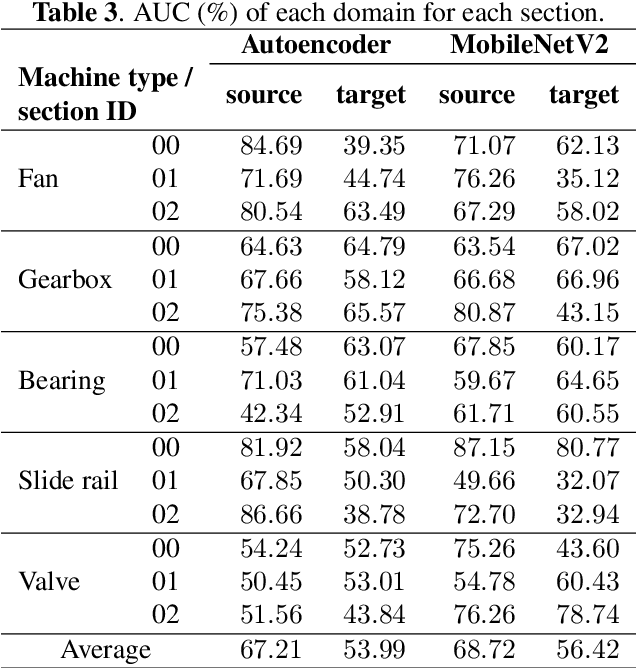
We present a machine sound dataset to benchmark domain generalization techniques for anomalous sound detection (ASD). To handle performance degradation caused by domain shifts that are difficult to detect or too frequent to adapt, domain generalization techniques are preferred. However, currently available datasets have difficulties in evaluating these techniques, such as limited number of values for parameters that cause domain shifts (domain shift parameters). In this paper, we present the first ASD dataset for the domain generalization techniques, called MIMII DG. The dataset consists of five machine types and three domain shift scenarios for each machine type. We prepared at least two values for the domain shift parameters in the source domain. Also, we introduced domain shifts that can be difficult to notice. Experimental results using two baseline systems indicate that the dataset reproduces the domain shift scenarios and is useful for benchmarking domain generalization techniques.
Anomalous Sound Detection Based on Machine Activity Detection
Apr 15, 2022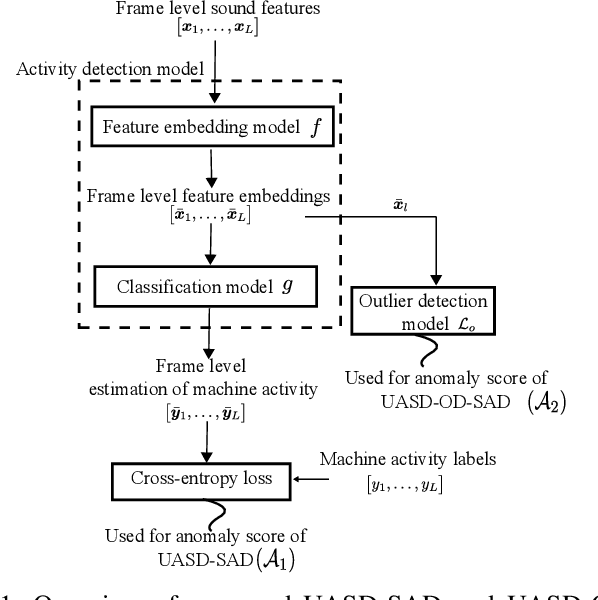
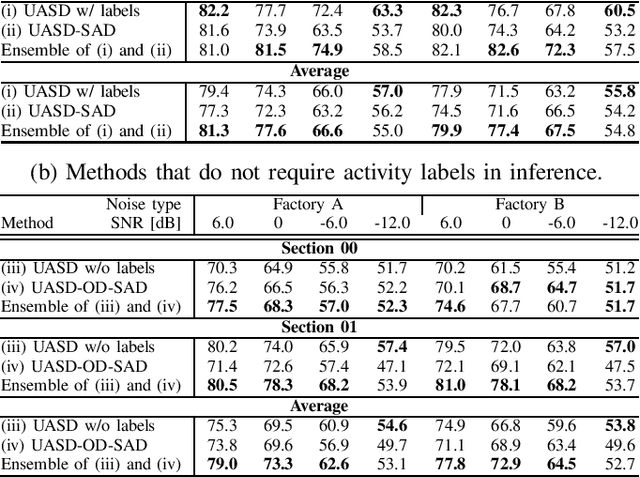
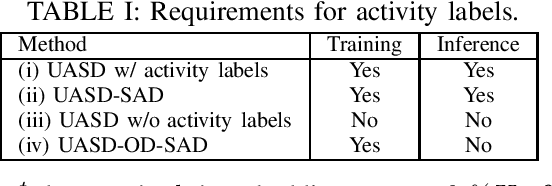
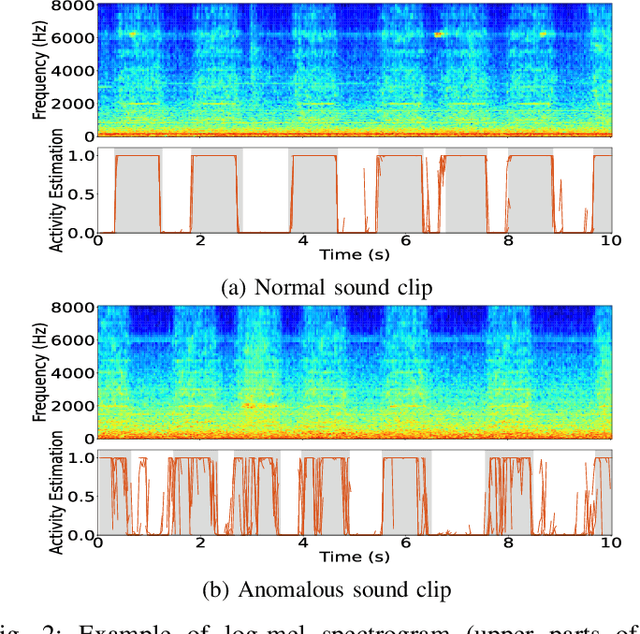
We have developed an unsupervised anomalous sound detection method for machine condition monitoring that utilizes an auxiliary task -- detecting when the target machine is active. First, we train a model that detects machine activity by using normal data with machine activity labels and then use the activity-detection error as the anomaly score for a given sound clip if we have access to the ground-truth activity labels in the inference phase. If these labels are not available, the anomaly score is calculated through outlier detection on the embedding vectors obtained by the activity-detection model. Solving this auxiliary task enables the model to learn the difference between the target machine sounds and similar background noise, which makes it possible to identify small deviations in the target sounds. Experimental results showed that the proposed method improves the anomaly-detection performance of the conventional method complementarily by means of an ensemble.
Environmental Sound Extraction Using Onomatopoeia
Dec 02, 2021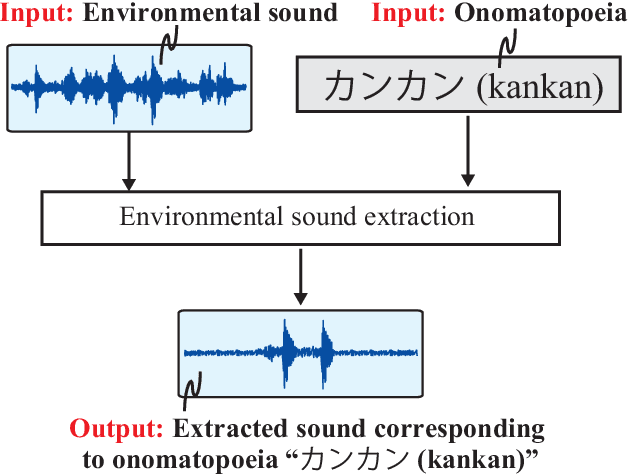
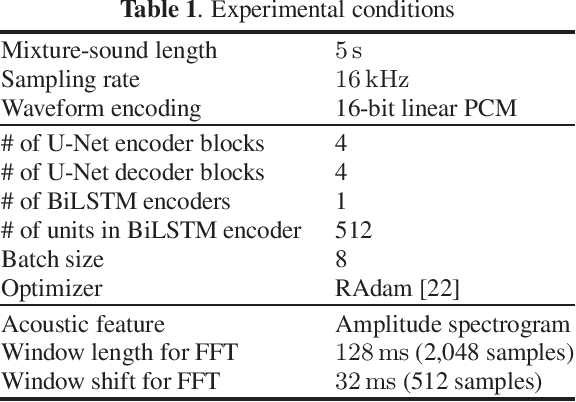
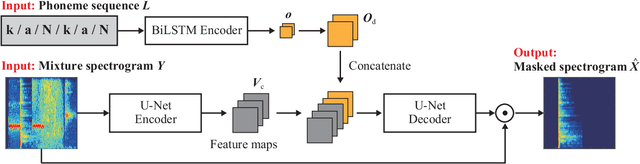
Onomatopoeia, which is a character sequence that phonetically imitates a sound, is effective in expressing characteristics of sound such as duration, pitch, and timbre. We propose an environmental-sound-extraction method using onomatopoeia to specify the target sound to be extracted. With this method, we estimate a time-frequency mask from an input mixture spectrogram and onomatopoeia by using U-Net architecture then extract the corresponding target sound by masking the spectrogram. Experimental results indicate that the proposed method can extract only the target sound corresponding to onomatopoeia and performs better than conventional methods that use sound-event classes to specify the target sound.