Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnvironmental Sound Extraction Using Onomatopoeia
Paper and Code
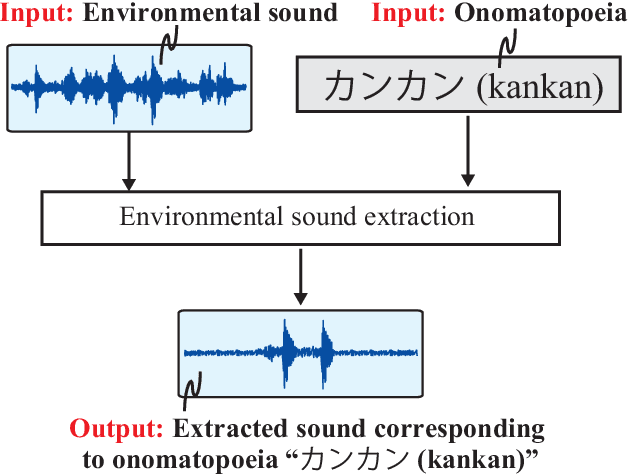
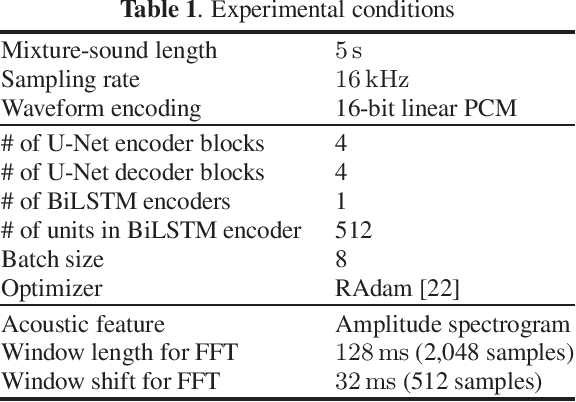
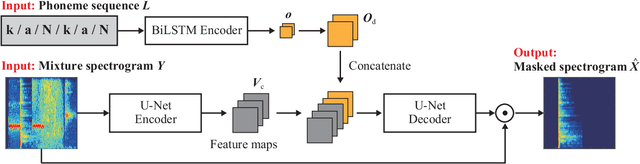
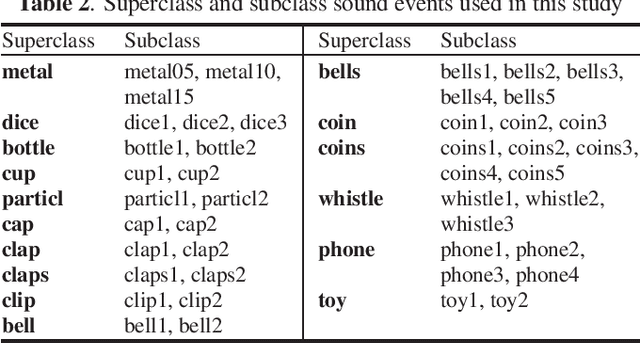
Onomatopoeia, which is a character sequence that phonetically imitates a sound, is effective in expressing characteristics of sound such as duration, pitch, and timbre. We propose an environmental-sound-extraction method using onomatopoeia to specify the target sound to be extracted. With this method, we estimate a time-frequency mask from an input mixture spectrogram and onomatopoeia by using U-Net architecture then extract the corresponding target sound by masking the spectrogram. Experimental results indicate that the proposed method can extract only the target sound corresponding to onomatopoeia and performs better than conventional methods that use sound-event classes to specify the target sound.
* Submitted to ICASSP2022
View paper on